Clear Sky Science · pt
Uma estrutura de deep learning baseada em DNABERT para prever sítios de ligação de fatores de transcrição
Por que prever interruptores de controle do DNA é importante
Cada célula do seu corpo carrega essencialmente o mesmo DNA, ainda que neurônios, hepatócitos e células do sistema imune se comportem de maneiras muito diferentes. Uma razão é que proteínas especiais chamadas fatores de transcrição atuam como interruptores moleculares, ligando ou desligando genes ao se acoplarem a trechos curtos de DNA conhecidos como sítios de ligação. Identificar experimentalmente todas essas posições ao longo do genoma é lento e caro. Este estudo apresenta o TFBS-Finder, um novo modelo de inteligência artificial que pode ler as letras brutas do DNA e prever com mais precisão onde fatores de transcrição se ligam, potencialmente acelerando a pesquisa sobre regulação gênica e doenças.
Lendo o DNA como uma língua
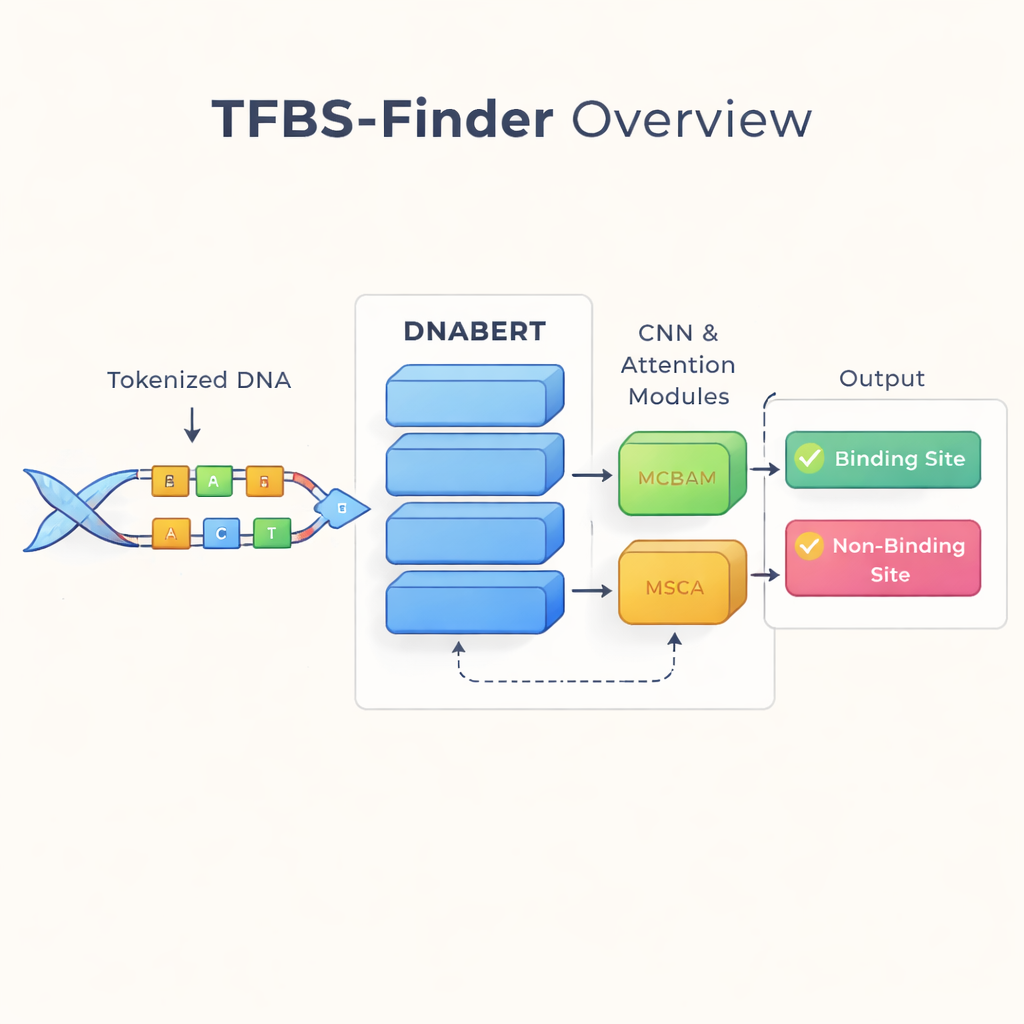
Os autores se baseiam em uma ideia que transformou a tecnologia de linguagem: tratar o DNA como se fosse texto. Eles usam o DNABERT, uma versão do modelo de linguagem BERT re-treinada no DNA humano em vez de palavras. O DNABERT não analisa apenas letras isoladas; ele segmenta o DNA em “palavras” sobrepostas de cinco letras e aprende como esses pedaços tendem a coocorrer. Isso permite ao modelo capturar contexto de longo alcance, como a relação entre padrões em uma extremidade de uma sequência e padrões distantes, de modo semelhante a compreender o sentido de uma frase em vez de palavras isoladas.
Encontrando padrões locais com atenção focalizada
Embora o DNABERT seja bom em captar contexto global, a ligação de fatores de transcrição frequentemente depende de motivos muito curtos e precisos — padrões locais no DNA. O TFBS-Finder, portanto, adiciona vários componentes extras sobre o DNABERT. Uma rede neural convolucional (CNN) percorre as embeddings da sequência para destacar formas locais recorrentes, análogo a como softwares de imagem detectam bordas e cantos. Dois módulos de atenção, chamados MCBAM e MSCA, atuam como holofotes ajustáveis, reforçando as características mais informativas e atenuando ruído. Juntos, esses blocos balanceiam uma visão de grande escala com detalhes finos para decidir se um segmento de DNA contém um sítio de ligação verdadeiro.
Demonstrando que cada peça realmente ajuda
Para testar se todos esses componentes são necessários, a equipe realizou extensos experimentos de “ablação”, removendo ou rearranjando sistematicamente módulos e re-treinando o sistema em 165 conjuntos de referência cobrindo 29 fatores de transcrição em 32 tipos celulares. Usando medidas padrão de qualidade de predição, o modelo completo TFBS-Finder consistentemente ficou no topo. Versões mais simples que dependiam apenas do DNABERT, ou que omitiram um dos módulos de atenção, perderam claramente em acurácia. Testes estatísticos confirmaram que essas quedas de desempenho não se deviam ao acaso, mostrando que a combinação entre compreensão global da sequência e atenção local cuidadosamente projetada é crucial.
Funcionando entre tipos celulares e superando ferramentas antigas
Uma questão importante é se um modelo treinado em um contexto biológico pode generalizar para outro. Os autores se concentraram em um fator de transcrição bem estudado chamado CTCF e treinaram o TFBS-Finder em dados de uma linhagem celular, testando-o em outras. Em todas as combinações, o modelo alcançou altas pontuações, sugerindo que captura características centrais da ligação de CTCF compartilhadas entre tecidos. Comparado a nove métodos de ponta, incluindo modelos anteriores de deep learning e baseados em BERT, o TFBS-Finder mostrou maior acurácia média e produziu ordenações de sítios de ligação mais confiáveis. Também rodou um pouco mais rápido e usou menos memória do que o modelo mais similar anterior, indicando que melhor desempenho não exigiu computação mais pesada.
Vendo o que o modelo aprendeu
Sistemas complexos de IA costumam ser criticados como “caixas-pretas”. Aqui, os pesquisadores tentaram abrir essa caixa visualizando quais posições do DNA mais influenciaram as decisões do TFBS-Finder. Para dois fatores de transcrição com motivos de ligação bem conhecidos, CEBPB e GATA3, eles geraram escores de importância ao longo da sequência e agruparam os sinais mais fortes em padrões consensuais. Esses motivos recuperados corresponderam de perto a motivos de referência de bancos de dados estabelecidos, e as regiões de ligação previstas se sobrepuseram a instâncias de motivos detectadas independentemente. Isso sugere que o TFBS-Finder não está apenas memorizando exemplos, mas aprendeu regras biologicamente significativas sobre como fatores de transcrição reconhecem o DNA.
O que isso significa para genética e medicina
O TFBS-Finder fornece uma maneira mais precisa e interpretável de mapear os interruptores de controle embutidos em nosso DNA. Ao apontar onde fatores de transcrição provavelmente se ligam, ele pode ajudar pesquisadores a traçar redes de regulação gênica, priorizar quais variantes genéticas podem perturbar sítios de controle cruciais e desenhar experimentos mais direcionados. Embora o trabalho atual use sequências embaralhadas como negativos artificiais e se concentre apenas nas letras do DNA, os autores planejam adicionar informação estrutural sobre a forma do DNA e explorar sequências de fundo mais realistas. À medida que esses modelos melhorarem, eles podem se tornar ferramentas poderosas para entender como mudanças no DNA não codificante contribuem para desenvolvimento, evolução e risco de doenças.
Citação: Dutta, P., Ghosh, N. & Santoni, D. A DNABERT based deep learning framework for predicting transcription factor binding sites. Sci Rep 16, 7018 (2026). https://doi.org/10.1038/s41598-026-37483-1
Palavras-chave: locais de ligação de fatores de transcrição, deep learning, DNABERT, regulação gênica, genômica