Clear Sky Science · pt
Melhoria da representação do conhecimento médico em grandes modelos de linguagem por otimização de tokens clínicos
Por que uma leitura médica mais inteligente importa
Por trás de todo assistente de IA médico há uma habilidade simples, mas crucial: como ele divide o texto em partes que pode entender. Quando essa “corte” falha — especialmente para termos médicos complexos em chinês — a IA pode perder ideias-chave em anotações de médicos ou em perguntas de pacientes. Este artigo mostra como uma mudança pequena, porém direcionada, nessa etapa inicial pode tornar grandes modelos de linguagem melhores em ler, raciocinar sobre e responder perguntas sobre dados médicos em chinês, sem a necessidade de construir um sistema totalmente novo do zero.
Dividindo o texto em peças do jeito certo
Modelos de linguagem modernos não leem caracteres ou palavras diretamente; eles primeiro convertem o texto em unidades curtas chamadas tokens. Para o inglês, isso funciona razoavelmente bem, porque os espaços já marcam os limites das palavras. O chinês é mais complicado: não há espaços e muitas expressões médicas são frases longas e especializadas. Tokenizadores padrão, projetados principalmente para o inglês, tendem a fatiar essas expressões em muitos fragmentos arbitrários. Quando um modelo vê o nome de uma doença ou um exame laboratorial dividido em várias partes desconexas, fica mais difícil aprender o que esse termo realmente significa, e suas respostas a perguntas médicas podem tornar-se vagas ou imprecisas.
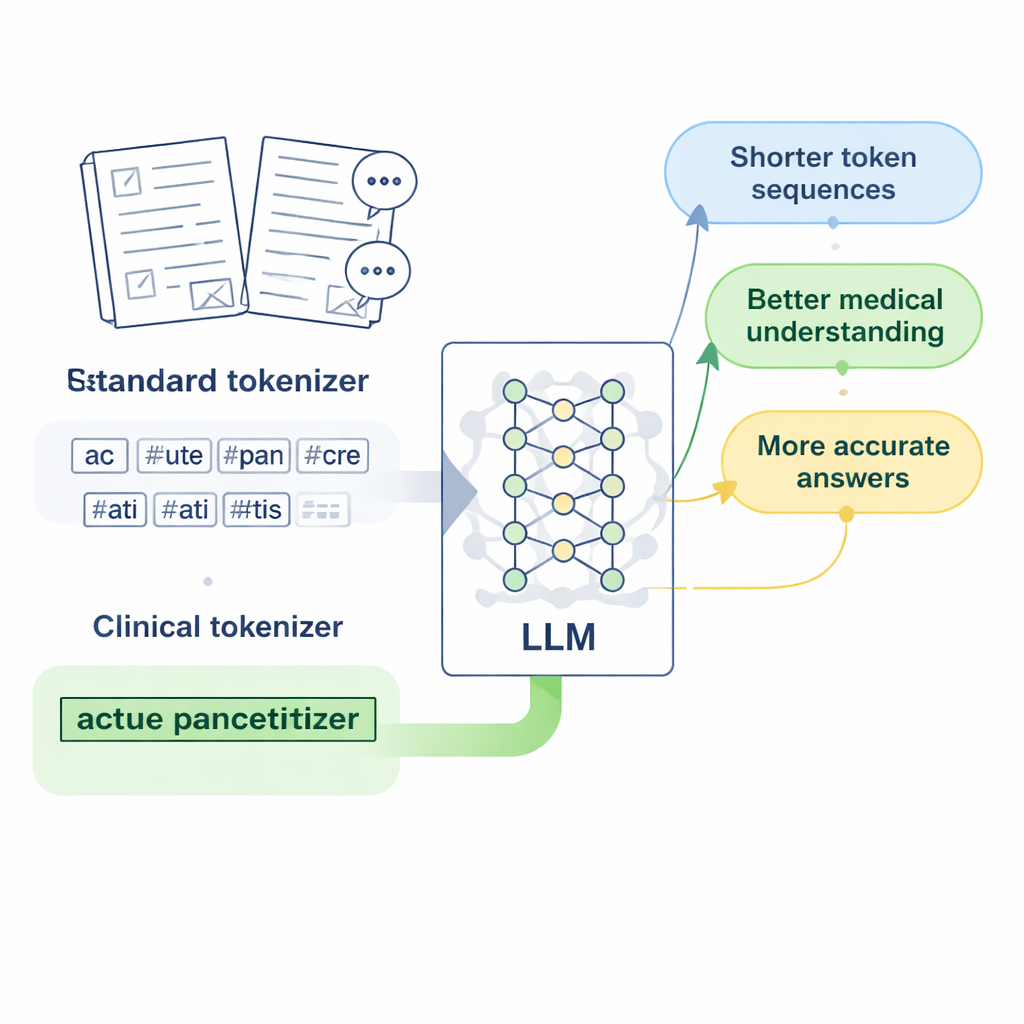
Projetando “tokens clínicos” para a medicina chinesa
Os pesquisadores focam no LLaMA2, um popular modelo de grande porte de código aberto, e perguntam: e se simplesmente ensinássemos ao seu tokenizador um vocabulário médico mais rico? Eles reúnem grandes coleções de texto médico em chinês, incluindo bancos de dados de medicina tradicional chinesa cuidadosamente editados, milhares de registros clínicos e pares de perguntas e respostas médico–paciente. Usando uma versão em nível de byte do algoritmo Byte Pair Encoding, implementada com a ferramenta SentencePiece, treinam um novo tokenizador que aprende a manter expressões médicas comuns juntas como unidades únicas. Essas novas unidades, que os autores chamam de “tokens clínicos”, são então mescladas ao vocabulário original do LLaMA2, expandindo-o para cobrir melhor a linguagem médica chinesa sem descartar o que o modelo já sabe.
De melhores tokens a um modelo médico melhor
Adicionar novos tokens é apenas o primeiro passo; o modelo precisa aprender boas representações para eles. A equipe ajusta a camada interna de embeddings do LLaMA2 para que ela possa armazenar vetores para o vocabulário expandido e testa duas formas de inicializar esses novos vetores. Um método faz a média dos vetores das subpartes antigas de cada palavra, enquanto o outro usa valores randômicos cuidadosamente escalados. Contraintuitivamente, o método randômico tem desempenho melhor, provavelmente porque evita aprisionar o modelo em um palpite inicial ruim sobre o significado de cada termo. Em seguida, os autores continuam o treinamento do modelo em texto médico e fazem fine-tuning em perguntas e respostas médicas no formato de instrução usando um método eficiente em recursos chamado LoRA, produzindo uma versão especializada que chamam de Medical-LLaMA.
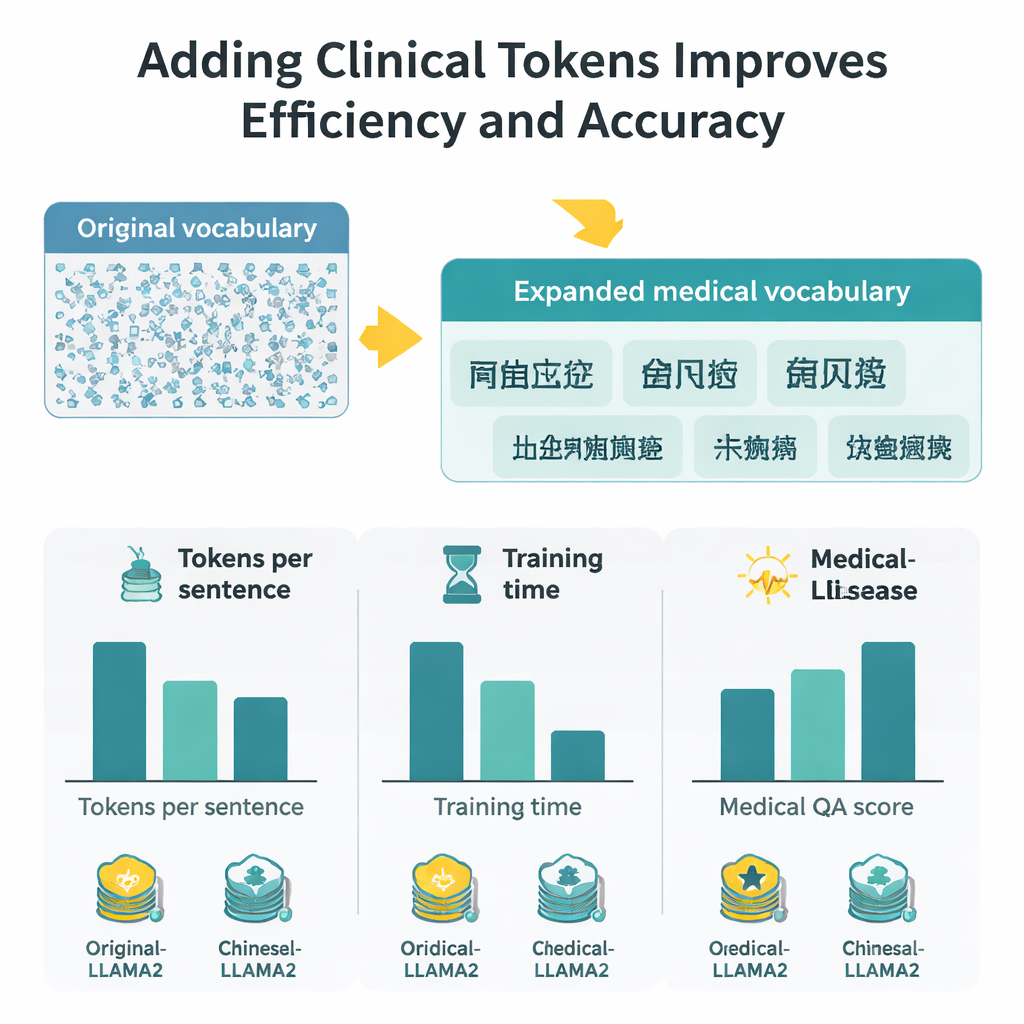
Medindo ganhos em velocidade, contexto e precisão
Com o vocabulário expandido, cada caractere chinês agora exige cerca de metade dos tokens anteriores, o que significa que o modelo pode processar trechos mais longos na mesma janela fixa de tokens. Na prática, o comprimento efetivo de contexto em chinês dobra aproximadamente, e o tempo de fine-tuning em um grande conjunto de perguntas e respostas médicas é reduzido em quase metade. Para avaliar a qualidade das respostas, os autores combinam duas estratégias: BERTScore, que mede quão semanticamente próxima uma resposta gerada está de uma referência, e um modelo de avaliação sofisticado (DeepSeek-R1) que pontua relevância, precisão, completude e fluência. Nessas medidas, o Medical-LLaMA supera consistentemente tanto o LLaMA2 original quanto uma variante otimizada para chinês que não incluiu tokens específicos médicos. Também apresenta melhorias pequenas, porém estáveis, em tarefas relacionadas, como reconhecimento de entidades médicas e classificação de texto clínico, tudo isso preservando o desempenho em perguntas gerais, não médicas.
O que isso significa para a IA médica do futuro
Para não-especialistas, a mensagem-chave é que “óculos de leitura” mais inteligentes para a IA — aqui, uma maneira melhor de fatiar a linguagem médica — podem melhorar de forma notável o quanto ela entende e responde a perguntas de saúde. Ao inserir tokens clínicos bem escolhidos no vocabulário de um modelo existente, os autores aumentam tanto a eficiência quanto a precisão sem exigir treinos massivos adicionais ou arquiteturas totalmente novas. Embora o trabalho seja limitado a um modelo de 7 bilhões de parâmetros e a textos médicos em chinês, ele aponta para uma receita prática: adaptar a camada mais inicial do processamento de linguagem ao domínio e, em seguida, re-treinar levemente. Essa estratégia pode ajudar futuras ferramentas de IA médica a se tornarem parceiras mais confiáveis para clínicos e pacientes, especialmente em idiomas e especialidades que modelos padrão têm dificuldade em ler.
Citação: Li, Q., Tong, J., Liu, S. et al. Medical knowledge representation enhancement in large language models through clinical tokens optimization. Sci Rep 16, 6563 (2026). https://doi.org/10.1038/s41598-026-37438-6
Palavras-chave: modelos de linguagem médica, texto clínico em chinês, tokenização, vocabulário clínico, resposta a perguntas médicas