Clear Sky Science · pt
AE-LFOG-YOLO: detecção robusta de capacetes de segurança via âncoras adaptativas e aprendizado invariante à iluminação
Por que as checagens inteligentes de capacete são importantes
Em grandes obras e em túneis subterrâneos, um simples capacete de segurança pode ser a diferença entre um susto e um acidente que muda a vida. Ainda assim, no caos dos canteiros de obra, as pessoas esquecem ou deixam de usar o capacete, e supervisores humanos não conseguem vigiar todos os cantos o tempo todo. Este estudo explora como construir um sistema automatizado por câmeras que identifique de forma confiável quem está ou não usando capacete, mesmo quando o túnel está escuro, cheio de reflexos de lâmpadas ou com trabalhadores distribuídos a várias distâncias da câmera.
Desafios de enxergar sob iluminação severa em túneis
Os locais de construção de túneis são visualmente extremos. Holofotes brilhantes geram ofuscamento, enquanto bolsões profundos de sombra escondem detalhes. Pessoas se aproximam e se afastam da câmera, de modo que os capacetes aparecem em muitos tamanhos diferentes. Detectores de inteligência artificial padrão frequentemente falham nessas condições: eles deixam de detectar capacetes em áreas escuras, confundem outros objetos arredondados com capacetes ou têm dificuldade com trabalhadores muito pequenos ou distantes. Muitos sistemas tentam corrigir isso clareando ou limpando as imagens antes da detecção, ou ajustando alguns componentes de modelos populares YOLO. Mas como essas etapas costumam ser soluções complementares em vez de parte de um processo de aprendizado unificado, elas deixam desempenho em aberto e não são robustas quando a iluminação ou a configuração da cena muda.
Uma nova forma de ensinar câmeras a ignorar iluminação ruim
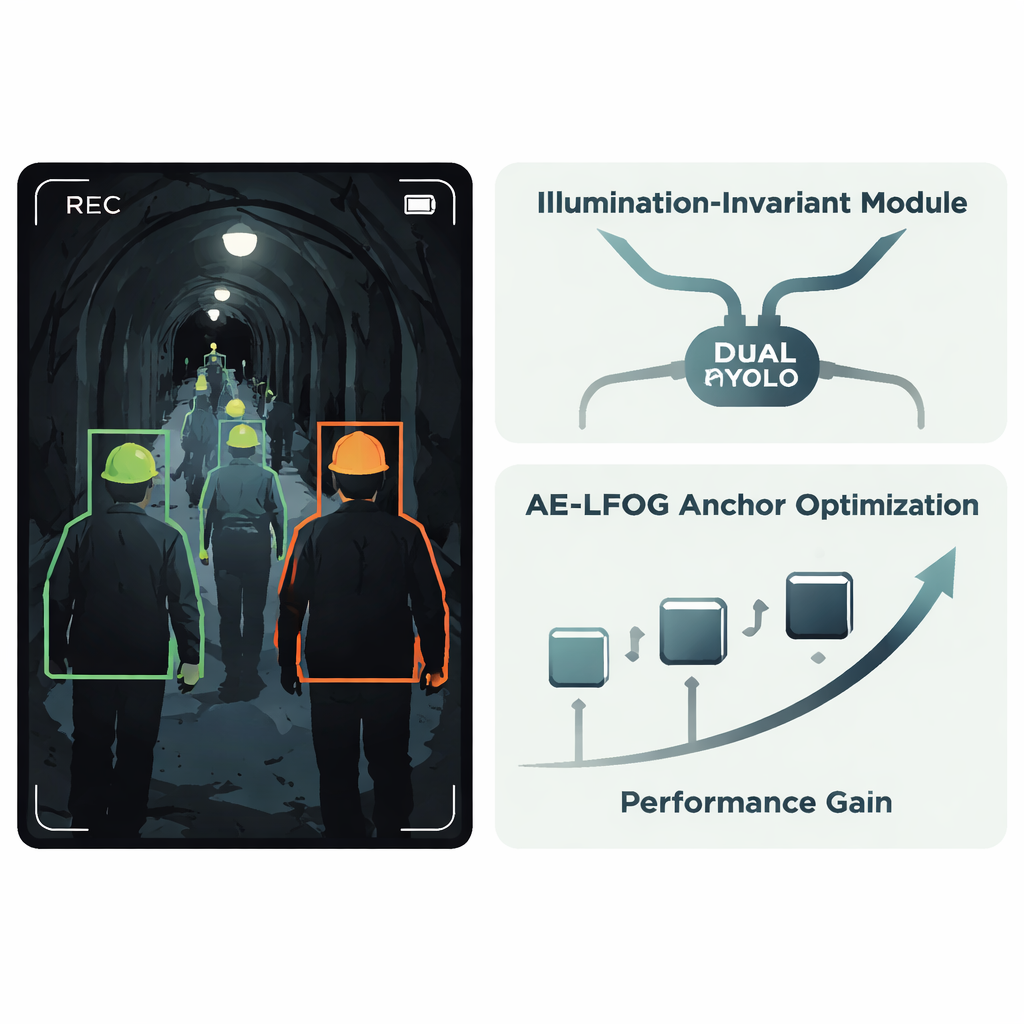
Os autores propõem um sistema aprimorado chamado AE-LFOG-YOLO, construído sobre o detector YOLOv8 amplamente usado. A primeira ideia-chave é um Módulo Invariante à Iluminação, uma pequena unidade inserida na rede que aprende a separar “o que a luz está fazendo” do “que aparência real os objetos têm”. Ele divide os mapas de características de entrada em uma parte que reflete principalmente padrões de iluminação e outra que captura formas e texturas mais estáveis, como a borda curva de um capacete. Usando operações de gating especiais e um ramo focado em bordas e cantos, o módulo atenua oscilações de brilho e enfatiza geometria estável. Como isso ocorre dentro do detector em vez de em um passo de pré-processamento separado, todo o sistema pode ser treinado de ponta a ponta para permanecer focado nos capacetes em si, em vez de ser enganado por manchas de ofuscamento ou escuridão.
Deixar o modelo evoluir seus próprios hábitos de visão
A segunda ideia principal mira em como o detector estima onde os objetos podem aparecer. Muitos detectores começam com um conjunto fixo de “caixas-âncora” que sugerem tamanhos e formatos prováveis de objetos; essas normalmente são escolhidas uma vez a partir dos dados de treinamento e não são atualizadas. Em túneis, contudo, o tamanho aparente de um capacete pode mudar dramaticamente com a distância da câmera e o ângulo de visão. O AE-LFOG-YOLO substitui âncoras estáticas por um processo dinâmico chamado Adaptive Evolutionary – Light Field Optimized Generation. Ao final de cada rodada de treinamento, o sistema perturba levemente suas caixas-âncora, avalia quão bem elas correspondem a capacetes reais de todos os tamanhos e também verifica se suas dimensões fazem sentido dado princípios básicos da ótica da câmera — quão grande um capacete real deve parecer no sensor em distâncias de trabalho típicas. Conjuntos de âncoras com melhor pontuação sobrevivem à próxima rodada. Com o tempo, o detector “evolui” âncoras que tanto se ajustam aos dados quanto respeitam como as câmeras de fato formam imagens do mundo.
Adaptando o treinamento à qualidade real das imagens
Além de mudar o que o modelo busca, os autores também alteram como ele aprende. Eles introduzem uma estratégia de treinamento que dá mais atenção ao posicionamento preciso das caixas delimitadoras quando a qualidade da imagem é baixa, e maior ênfase em rotular corretamente capacete versus sem capacete quando as condições são boas. Uma pontuação baseada em física, novamente derivada de princípios de formação de imagem por câmera, informa ao sistema quão confiáveis são as imagens em cada estágio. Se a iluminação ou o foco estiver ruim, o processo de treinamento aumenta automaticamente a importância de acertar as caixas delimitadoras; se as condições melhoram, desloca o peso para a classificação. Isso cria um ciclo de retroalimentação em que o modelo ajusta continuamente suas prioridades para corresponder ao ambiente físico que enfrentará em túneis reais.
O que os testes mostram na prática
Os pesquisadores testam sua abordagem em um conjunto de dados real de capacetes de segurança em túneis e a comparam com vários métodos avançados baseados em YOLO. O AE-LFOG-YOLO detecta capacetes com precisão muito alta, identificando corretamente cerca de 95% dos capacetes num limiar padrão de sobreposição e superando a linha de base YOLOv8 simples tanto em precisão quanto em recall. Ele roda rápido o suficiente para uso em tempo real e se mostra especialmente forte quando a iluminação é fortemente manipulada para simular escuridão extrema ou superexposição. Nestas condições difíceis, o novo modelo mantém maior confiança, detecta mais trabalhadores pequenos e distantes e opera sobre uma faixa de brilho mais de um terço maior que a da linha de base, o que significa que permanece confiável em um conjunto muito maior de cenas do mundo real.
Como isso ajuda a manter os trabalhadores mais seguros
Para não especialistas, a conclusão é direta: ao ensinar um sistema de IA a entender não apenas pixels, mas também a física de como câmeras enxergam em ambientes difíceis, este trabalho entrega um observador mais inteligente e mais confiável na parede do túnel. O AE-LFOG-YOLO consegue ignorar melhor iluminações enganosas e se adaptar a vistas mutáveis, reduzindo detecções perdidas e alarmes falsos. Implantado por meses em uma linha ferroviária em operação, ele já demonstrou que pode apoiar equipes de segurança em assegurar que trabalhadores mantenham seus capacetes, oferecendo um passo prático rumo a canteiros de obra mais seguros e com monitoramento mais próximo.
Citação: Liu, S., Wang, J. AE-LFOG-YOLO: robust safety helmet detection via adaptive anchors and illumination invariant learning. Sci Rep 16, 6402 (2026). https://doi.org/10.1038/s41598-026-37326-z
Palavras-chave: detecção de capacete de segurança, construção de túneis, visão computacional, imagens em baixa luminosidade, YOLOv8