Clear Sky Science · pt
Avaliação de desempenho de transformadores pré-treinados generativos no Exame Nacional de Licenciamento Veterinário no Japão
Por que exames veterinários melhores importam para todos
Por trás de cada visita ao hospital veterinário há anos de treinamento rigoroso e um exame nacional de alto risco. No Japão, os futuros veterinários devem passar no Exame Nacional de Licenciamento Veterinário (NVLE), que avalia desde biologia básica até julgamento clínico complexo. Este estudo fez uma pergunta oportuna: os modelos avançados de linguagem de IA de hoje, os mesmos que alimentam chatbots populares, conseguem resolver esse exigente exame em japonês — e o que isso pode significar para a educação veterinária e o cuidado animal?
Testando IA em um exame real de licenciamento veterinário
Os pesquisadores concentraram-se em três gerações de grandes modelos de linguagem da OpenAI: GPT‑4o, o1 e o3. Esses sistemas foram projetados para ler e gerar texto com aparência humana, mas nunca foram treinados especificamente em medicina veterinária. Para colocá‑los à prova, a equipe usou o 74º NVLE do Japão (2023) como referência. O exame é dividido em cinco seções, incluindo questões apenas em texto e questões com imagens que mostram radiografias, fotos ou diagramas. Todas as questões são de múltipla escolha com cinco opções, assim como no exame real aplicado aos estudantes. Os modelos receberam cada pergunta por meio de um roteiro de computador padronizado e foram obrigados a responder apenas com o número da opção escolhida, sem chance de "explicar" ou negociar para obter crédito.
Qual modelo de IA ficou no topo?
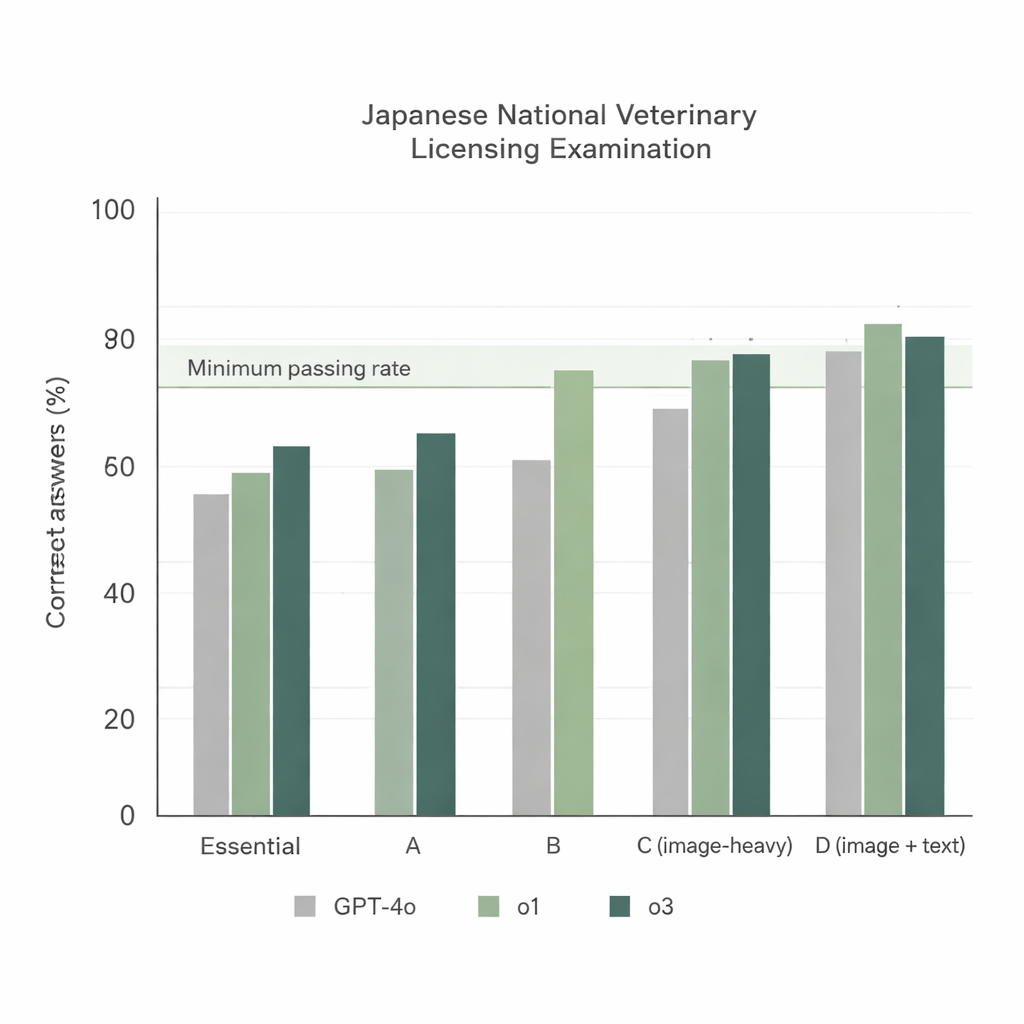
Quando os três modelos enfrentaram o 74º NVLE usando a configuração mais simples — perguntas em japonês e um prompt de instrução direto — surgiram duas tendências claras. Primeiro, todos os modelos tiveram bom desempenho nas seções baseadas em texto, mas o1 e o3 superaram consistentemente o GPT‑4o. Segundo, o desempenho caiu nas seções com muitas imagens, ainda assim o1 e o3 mantiveram‑se acima da taxa mínima oficial de aprovação, enquanto o GPT‑4o ficou aquém em uma dessas seções. No geral, o GPT‑4o acertou cerca de 78% das questões, enquanto o o1 atingiu cerca de 92% e o o3 cerca de 93%. Como o o3 superou ligeiramente o o1 na pontuação total, os pesquisadores escolheram o3 para o restante dos experimentos.
Prompts ou traduções realmente ajudam?
Muito se escreveu sobre "engenharia de prompt" — elaborar instruções detalhadas para extrair respostas melhores da IA — e sobre traduzir perguntas locais para o inglês para alinhá‑las aos dados de treinamento dos modelos. O estudo testou diretamente essas ideias com o modelo o3, comparando um prompt básico de resolução versus um prompt mais detalhado e otimizado, e perguntas em japonês versus versões primeiro traduzidas para o inglês pelo próprio modelo. Surpreendentemente, nenhuma dessas mudanças fez diferença significativa: o o3 passou confortavelmente em todas as seis combinações, e a abordagem mais simples (texto original em japonês com o prompt básico) funcionou tão bem quanto as configurações mais complexas. Isso sugere que, pelo menos para essas questões veterinárias, os modelos mais recentes já compreendem o japonês de forma confiável e não exigem prompts intrincados para ter um desempenho elevado.
Quão estável é o desempenho em exames mais recentes?
Para verificar se os resultados fortes eram um acaso, a equipe aplicou em seguida ao o3 os 75º (2024) e 76º (2025) NVLEs, novamente usando apenas as perguntas originais em japonês e o prompt normal. O modelo obteve pontuações globais acima de 92% em ambos os exames e ultrapassou o limite de aprovação em todas as seções, incluindo as áreas com muitas imagens. A maioria das questões recebeu a mesma resposta em três execuções independentes, mostrando que as respostas do o3 foram geralmente estáveis mesmo quando alguma aleatoriedade foi permitida. Ao analisar mais de perto os erros do modelo, os pesquisadores verificaram que as falhas se concentraram em duas áreas: conhecimentos veterinários práticos (como leis veterinárias japonesas) e medicina clínica, que exigem regras específicas do país e raciocínio em múltiplas etapas em vez de simples memorização de fatos.
O que isso significa — e o que não significa
O estudo conclui que modelos de ponta no estilo GPT agora podem passar no exame de licenciamento veterinário do Japão em japonês, sem truques de tradução ou prompts complexos. Para faculdades e estudantes de veterinária, isso abre a porta para usar IA como parceiro de estudo, gerador de questões ou explicador de tópicos de exame. Para o público, sinaliza que a IA está se tornando uma ferramenta poderosa para organizar e compartilhar conhecimento veterinário. No entanto, os autores ressaltam que esses sistemas não estão prontos para substituir veterinários nem para tomar decisões médicas por conta própria. Os modelos ainda podem interpretar imagens incorretamente, ter dificuldade com julgamentos clínicos sutis e, às vezes, inventar fatos. Usados com cuidado, podem tornar‑se assistentes valiosos na educação veterinária e no suporte informacional — mas a responsabilidade pela saúde animal continuará firme nas mãos humanas.
Citação: Kako, T., Kato, D., Iguchi, T. et al. Performance evaluation of generative pre-trained transformer on the National Veterinary Licensing Examination in Japan. Sci Rep 16, 4306 (2026). https://doi.org/10.1038/s41598-026-37300-9
Palavras-chave: exames de licenciamento veterinário, grandes modelos de linguagem, inteligência artificial na medicina, desempenho do GPT, educação veterinária no Japão