Clear Sky Science · pt
O impacto da escolha de K na validação cruzada K‑fold sobre viés e variância em modelos de aprendizagem supervisionada
Por que checar seu modelo duas vezes realmente importa
De diagnósticos médicos a concessão de crédito, muitas decisões hoje dependem de modelos de aprendizado de máquina treinados com dados históricos. Mas como saber se um modelo que parece bom na tela do computador se comportará bem em casos novos e não vistos? Uma maneira popular de "testar" modelos é a validação cruzada k‑fold, na qual os dados são repetidamente divididos em partes de treinamento e de teste. Este estudo faz uma pergunta aparentemente simples, porém crucial: quantas partes — qual deve ser o tamanho de k — e como essa escolha molda silenciosamente a confiabilidade do desempenho relatado do modelo?
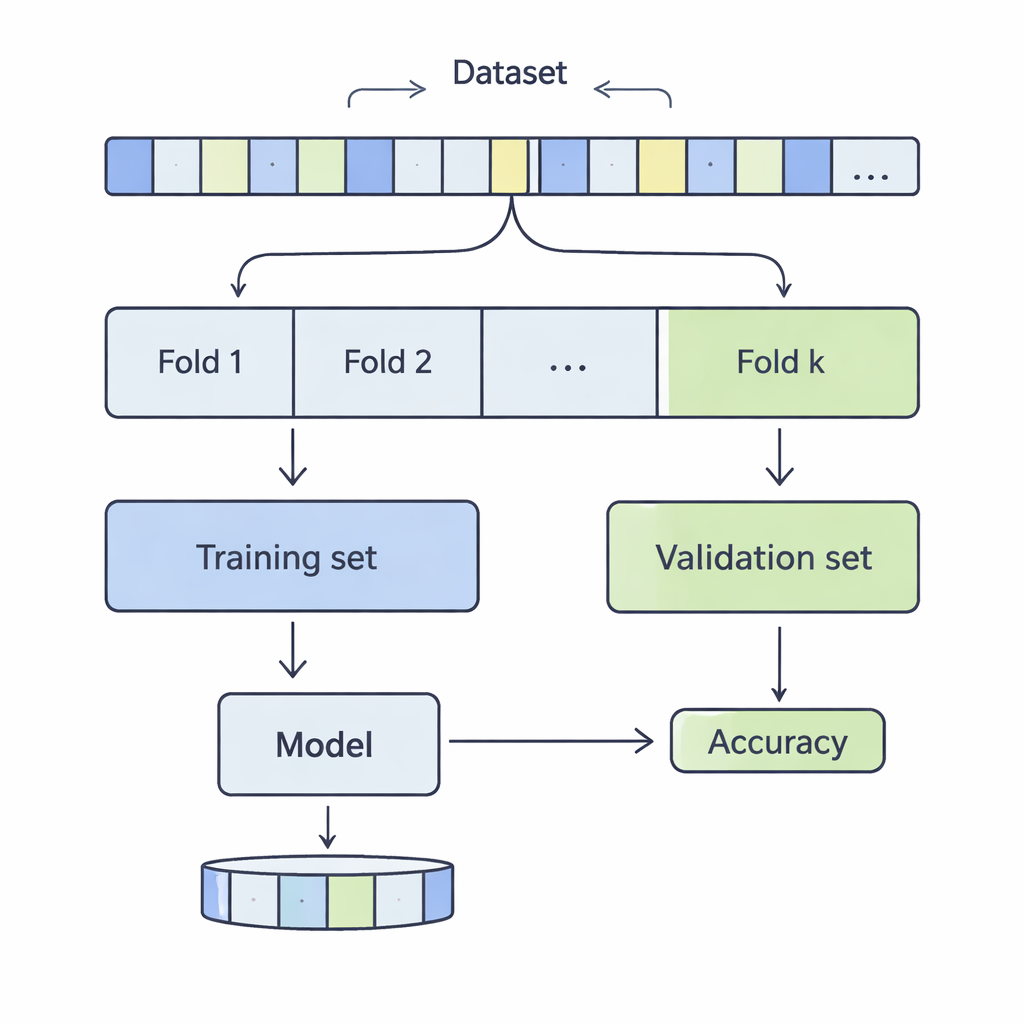
Como os dados são fatiados para um cheque de realidade
Na validação cruzada k‑fold, um conjunto de dados é embaralhado e dividido em k partes iguais, ou folds. O modelo é treinado em k‑1 desses folds e avaliado no restante; esse processo se repete até que cada fold tenha sido usado como conjunto de teste. Os autores examinaram valores de k de 3 a 20, em 12 conjuntos de dados do mundo real variando de alguns milhares a mais de meio milhão de registros, cobrindo áreas como previsão de renda, desfechos médicos, ciberataques, jogos e qualidade do vinho. Aplicaram quatro métodos de classificação comuns — Máquinas de Vetores de Suporte, Árvores de Decisão, Regressão Logística e k‑Vizinhos Mais Próximos — e mediram cuidadosamente como a escolha de k afetou dois aspectos-chave do desempenho: viés e variância.
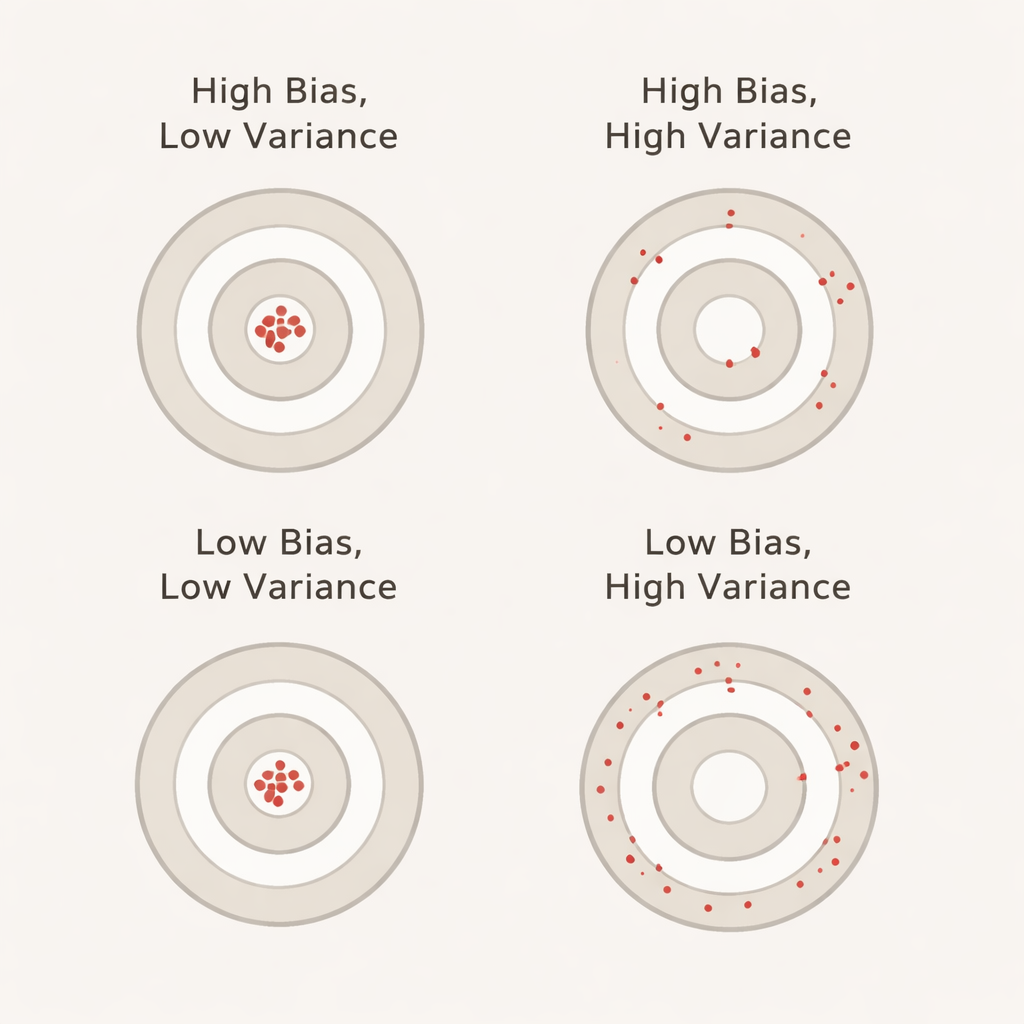
O que viés e variância significam em termos cotidianos
Viés, neste contexto, captura o quanto o modelo parece performar melhor durante a validação cruzada do que realmente faz em um conjunto de teste separado e intocado. Um viés positivo grande significa que o modelo parece excessivamente otimista durante a validação — semelhante a um estudante que vai muito bem nas provas práticas, mas tropeça no exame real. Variância reflete o quanto o desempenho do modelo oscila de um fold para outro: baixa variância significa que as pontuações são estáveis entre diferentes fatias de dados, enquanto alta variância significa que elas sobem e descem. Idealmente, queremos tanto o viés quanto a variância baixos, de modo que a precisão relatada seja ao mesmo tempo realista e estável.
O que acontece à medida que aumentamos o número de folds
Em todos os doze conjuntos de dados e nos quatro algoritmos, um padrão se destacou com força: à medida que k aumentou, a variância quase sempre aumentou. Em outras palavras, usar mais folds tornou a precisão relatada menos estável de um fold para outro. Isso contraria a crença comum de que mais folds automaticamente fornecem estimativas melhores e mais confiáveis. A razão é que, quando k é grande, cada fatia de validação fica muito pequena e menos representativa, de modo que os resultados ficam mais sensíveis a peculiaridades dos dados. Ao mesmo tempo, o comportamento do viés foi menos uniforme. Para k‑Vizinhos Mais Próximos e Máquinas de Vetores de Suporte, o viés tendia a aumentar com o crescimento de k, o que significa que esses modelos frequentemente pareciam mais precisos na validação cruzada do que no conjunto de teste reservado. Árvores de Decisão mostraram padrões mais equilibrados, e Regressão Logística ficou entre eles, com mudanças de viés mistas, porém mais moderadas.
Por que as “configurações padrão” podem ser enganadoras
A maioria dos guias práticos simplesmente sugere usar cinco ou dez folds, independentemente do conjunto de dados ou do algoritmo de aprendizado. A análise dos autores mostra que esse conselho único para todos pode ser enganador. Em alguns conjuntos de dados e para alguns modelos, valores maiores de k ampliaram impressões otimistas demais sobre o desempenho; em todos eles, mais folds trouxeram mais variabilidade nas estimativas. Isso é especialmente preocupante em áreas de alto risco, como saúde, finanças ou infraestrutura, onde confiança falsa na precisão de um modelo pode ter consequências reais. O estudo argumenta que os efeitos de k dependem tanto da natureza dos dados (pequenos vs. grandes, ruidosos vs. mais limpos) quanto de como o algoritmo específico aprende a partir de conjuntos de treinamento repetidos e quase idênticos.
Mensagem principal para quem usa aprendizado de máquina
A lição central é que o número de folds na validação cruzada não é um detalhe técnico inofensivo — ele molda diretamente o quão confiáveis são seus números de precisão. Nestes experimentos, mais folds tornaram os resultados consistentemente mais instáveis e frequentemente fizeram alguns modelos parecerem melhores do que realmente eram. Em vez de escolher cegamente k=5 ou k=10, os autores recomendam tratar k como um botão de ajuste: verifique como os resultados mudam em uma pequena faixa de valores de k e, quando possível, examine mais de uma métrica de desempenho. Para praticantes e leitores interessados, a mensagem é clara: ao avaliar modelos de aprendizado de máquina, a forma como você fati a os dados pode importar quase tanto quanto o próprio modelo.
Citação: Abedin, T., Xu, H. & Uddin, S. The impact of K selection in K‑fold cross-validation on bias and variance in supervised learning models. Sci Rep 16, 6084 (2026). https://doi.org/10.1038/s41598-026-37247-x
Palavras-chave: validação cruzada k-fold, compromisso viés‑variância, avaliação de modelo, validação em aprendizado de máquina, classificação supervisionada