Clear Sky Science · pt
Um método para detectar capacetes de segurança em ambientes subterrâneos com base no modelo YOLOv11-SRA
Por que checagens de capacete mais inteligentes importam no subsolo
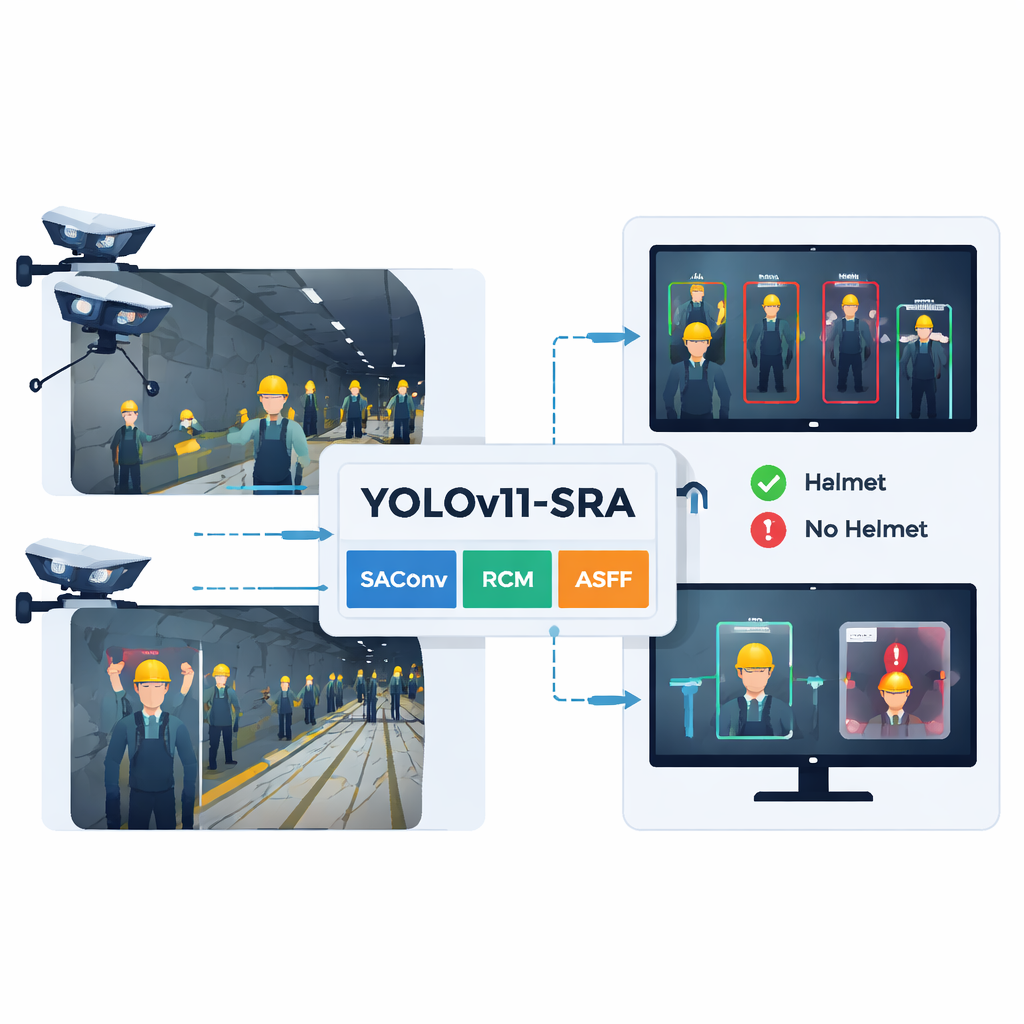
Em profundidades nas minas e túneis, os trabalhadores dependem dos capacetes de segurança como última linha de defesa contra quedas de rochas, máquinas e tetos baixos. Ainda assim, em passagens escuras, empoeiradas e lotadas, é difícil para supervisores — e até para câmeras convencionais — identificar quem está devidamente protegido. Este artigo apresenta um novo sistema de visão computacional, baseado em um modelo aprimorado YOLOv11-SRA, que pode detectar automaticamente capacetes e cabeças descobertas em tempo real, mesmo quando a iluminação é fraca, a visão está bloqueada e as pessoas estão distantes da câmera.
Os perigos de depender de inspeções humanas
A inspeção tradicional de capacetes em minas ainda depende fortemente de pessoas que percorrem os túneis buscando violações, ou de catracas e pontos de controle pelos quais os trabalhadores devem passar. Esses métodos são lentos, cobrem apenas alguns locais e podem deixar passar comportamentos arriscados quando as pessoas se deslocam para partes mais profundas. Capacetes com sensores, etiquetas ou eletrônica integrada oferecem alguma automação, mas são caros, difíceis de manter em condições adversas e exigem modificar cada capacete. À medida que a mineração se expande e os turnos se tornam mais longos, essas abordagens antigas têm dificuldade em fornecer a vigilância contínua e abrangente necessária para prevenir acidentes.
Ensinar câmeras a enxergar capacetes em condições difíceis
Avanços recentes em aprendizado profundo transformaram a forma como computadores interpretam imagens, especialmente para identificar objetos como carros ou pedestres. A família de algoritmos YOLO é amplamente usada porque consegue analisar uma imagem e localizar objetos em uma única passada rápida — ideal para vídeo ao vivo. No entanto, cenários subterrâneos pressionam esses sistemas ao máximo. Capacetes podem aparecer como pequenos fragmentos coloridos em uma cabeça distante, ficar parcialmente ocultos por tubos ou máquinas, ou fundir-se ao fundo sob iluminação fraca e desigual. Os autores projetaram o YOLOv11-SRA especificamente para lidar com esses problemas, para que as câmeras das minas possam distinguir de forma confiável entre trabalhadores protegidos e desprotegidos.
Uma atualização em três partes para um motor de visão popular
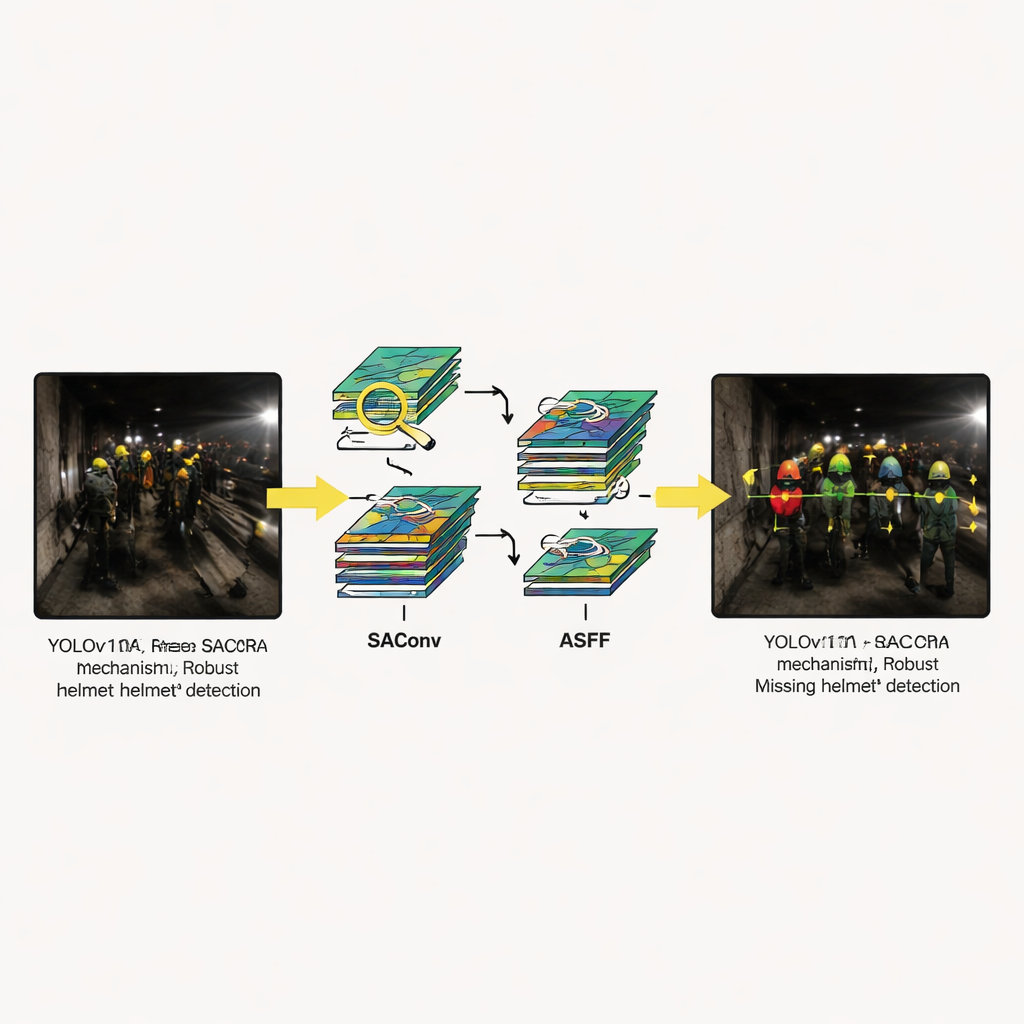
O novo modelo mantém a estrutura geral do YOLOv11 — entrada, backbone, neck e cabeça de detecção — mas adiciona três módulos especializados. Primeiro, o bloco SAConv permite que a rede analise cada imagem em vários “níveis de zoom” simultaneamente, capturando tanto capacetes pequenos e distantes quanto os maiores e mais próximos sem custo extra. Segundo, o bloco RCM guia o modelo a focar em regiões longas e retangulares que correspondem à forma típica da cabeça e dos ombros de uma pessoa em um túnel, ajudando a traçar as bordas do capacete mesmo quando equipamentos ou outros trabalhadores atrapalham. Terceiro, o bloco ASFF combina informações de múltiplas escalas de imagem, permitindo ao sistema escolher, pixel por pixel, qual nível descreve melhor cada parte da cena. Juntas, essas melhorias reduzem a confusão entre capacetes e ruído de fundo e acentuam os contornos de capacetes pequenos ou parcialmente visíveis.
Colocando o sistema à prova
Para verificar se essas ideias funcionam na prática, os pesquisadores treinaram e testaram o modelo no CUMT-HelmeT, uma coleção pública de imagens de vigilância subterrânea rotuladas com casos de “capacete” e “sem capacete”, além de outros objetos comuns. Como o conjunto de dados bruto é relativamente pequeno, eles o ampliaram cinco vezes cortando, girando e clareando imagens para simular diferentes ângulos de câmera e iluminações. Neste benchmark desafiador, o YOLOv11-SRA alcançou uma média de precisão (mAP) de cerca de 84% e uma recall próxima de 80%, superando claramente diversos detectores conhecidos, incluindo versões mais novas do YOLO, RetinaNet, SSD e Faster R-CNN. Apesar da maior precisão, o modelo permanece compacto e eficiente: usa menos parâmetros e menos computação que a maioria dos concorrentes e pode analisar quase 100 imagens por segundo em uma placa gráfica moderna, velocidade suficiente para alertas em tempo real.
Enxergando através da escuridão, poeira e brilho
Exemplos visuais destacam como o sistema se comporta em situações que frequentemente confundem métodos antigos: capacetes meio ocultos, cenas iluminadas apenas por lâmpadas fracas, trabalhadores distantes da câmera e reflexos fortes em superfícies brilhantes. Em cada caso, o YOLOv11-SRA produz detecções mais confiantes e consistentes do que modelos rivais. Ele é menos propenso a perder capacetes pequenos ou pouco iluminados e melhor em evitar falsos positivos quando pontos brilhantes ou canos imitam cores de capacete. Estudos de ablação — onde os autores desativam módulos individuais — mostram que cada parte contribui, mas os maiores ganhos aparecem quando os três estão combinados, confirmando que o projeto funciona como um todo integrado e não como um conjunto de truques isolados.
Do protótipo de pesquisa a turnos mais seguros
Em termos acessíveis, este trabalho equivale a dar às câmeras das minas um “olho” mais nítido e adaptável para equipamentos de proteção básicos. Ao sinalizar com maior confiabilidade os trabalhadores que estão sem capacete, mesmo em feeds de vídeo ruidosos e com pouca luz, o sistema YOLOv11-SRA pode ajudar supervisores a intervir mais cedo e reduzir a chance de lesões na cabeça. Por ser relativamente leve, o modelo pode ser implantado em dispositivos embarcados próximos às câmeras, em vez de depender apenas de centros de dados remotos. Os autores observam que dados de treinamento mais amplos e maior otimização poderiam tornar a abordagem ainda mais robusta, mas seus resultados já apontam para um monitoramento de segurança mais inteligente e escalável nas exigentes condições da mineração subterrânea moderna.
Citação: Wang, L., Wan, X., Shi, X. et al. A method for detecting safety helmets underground based on the YOLOv11-SRA model. Sci Rep 16, 6194 (2026). https://doi.org/10.1038/s41598-026-37148-z
Palavras-chave: segurança em mineração subterrânea, detecção de capacete, visão computacional, monitoramento em tempo real, aprendizado profundo