Clear Sky Science · pt
Análise comparativa de modelos supervisionados e em conjunto com exploração não supervisionada para previsão da doença de Alzheimer
Por que o alerta precoce é importante
A doença de Alzheimer rouba lentamente a memória e a independência das pessoas, muitas vezes muito antes de um diagnóstico definitivo ser feito. Famílias, médicos e sistemas de saúde se beneficiam quando sinais de alerta são detectados cedo, porque é nesse momento que tratamento, planejamento e apoio podem fazer a maior diferença. Este estudo faz uma pergunta prática: programas de computador cuidadosamente projetados, treinados com informações clínicas rotineiras e de exames cerebrais, podem detectar demência de forma mais confiável do que as ferramentas padrão atuais — e ao mesmo tempo revelar padrões ocultos em como a doença se desenvolve?
Transformando registros de pacientes em sinais utilizáveis
Os pesquisadores recorreram a uma coleção de dados bem conhecida chamada OASIS-2, que acompanha 150 idosos entre 60 e 96 anos ao longo de vários anos. Para cada visita, o conjunto de dados inclui informações básicas como idade, anos de escolaridade e nível socioeconômico, bem como pontuações em testes cognitivos e medidas derivadas de ressonâncias magnéticas cerebrais, como o volume cerebral total. Antes que qualquer previsão pudesse ocorrer, a equipe limpou os dados, removeu identificadores e casos ambíguos, preencheu um pequeno número de valores ausentes e colocou todas as medidas numéricas em uma escala comum. Eles também enfrentaram um problema do mundo real: havia muito mais pessoas saudáveis do que com demência no conjunto de dados. Para evitar que os modelos simplesmente previssem “sem demência” na maioria das vezes, os pesquisadores usaram esquemas de ponderação que fazem com que erros no grupo menor, com demência, tenham peso maior durante o treinamento.
Comparando ferramentas clássicas com equipes de modelos
Com esse conjunto de dados preparado, os autores compararam ferramentas de aprendizado de máquina familiares com “ensembles” mais avançados, que combinam vários modelos em um preditor mais forte. O grupo clássico incluiu regressão logística, árvores de decisão, máquinas de vetor de suporte e florestas aleatórias. O grupo de ensembles contou com AdaBoost, XGBoost e um modelo de votação majoritária que mesclava três classificadores ajustados. Todos os modelos foram treinados em uma porção dos dados e testados em casos retidos, com o desempenho avaliado usando acurácia, a capacidade de identificar corretamente indivíduos com demência (recall) e a área sob a curva ROC, um resumo de quão bem o modelo separa casos saudáveis dos doentes. 
Quando muitas mentes vencem uma
Os resultados do confronto foram claros. Enquanto os melhores métodos tradicionais tiveram desempenho razoável, eles atingiram um platô próximo ao nível relatado em estudos anteriores, com acurácias de teste na faixa baixa a média de 80%. Em contraste, o ensemble de votação majoritária alcançou cerca de 95% de acurácia e uma pontuação ROC igualmente alta, superando o patamar comumente citado de 92%. AdaBoost e outros modelos em conjunto também se saíram melhor do que qualquer modelo tradicional isolado. Essa vantagem surge porque algoritmos diferentes captam aspectos distintos dos dados; ao permitir que “votem”, o ensemble suaviza peculiaridades e overfitting individuais, levando a previsões mais estáveis. O preço desse ganho é a transparência reduzida: é mais difícil ver, de relance, por que um ensemble tomou determinada decisão em comparação com uma regressão simples ou uma única árvore. 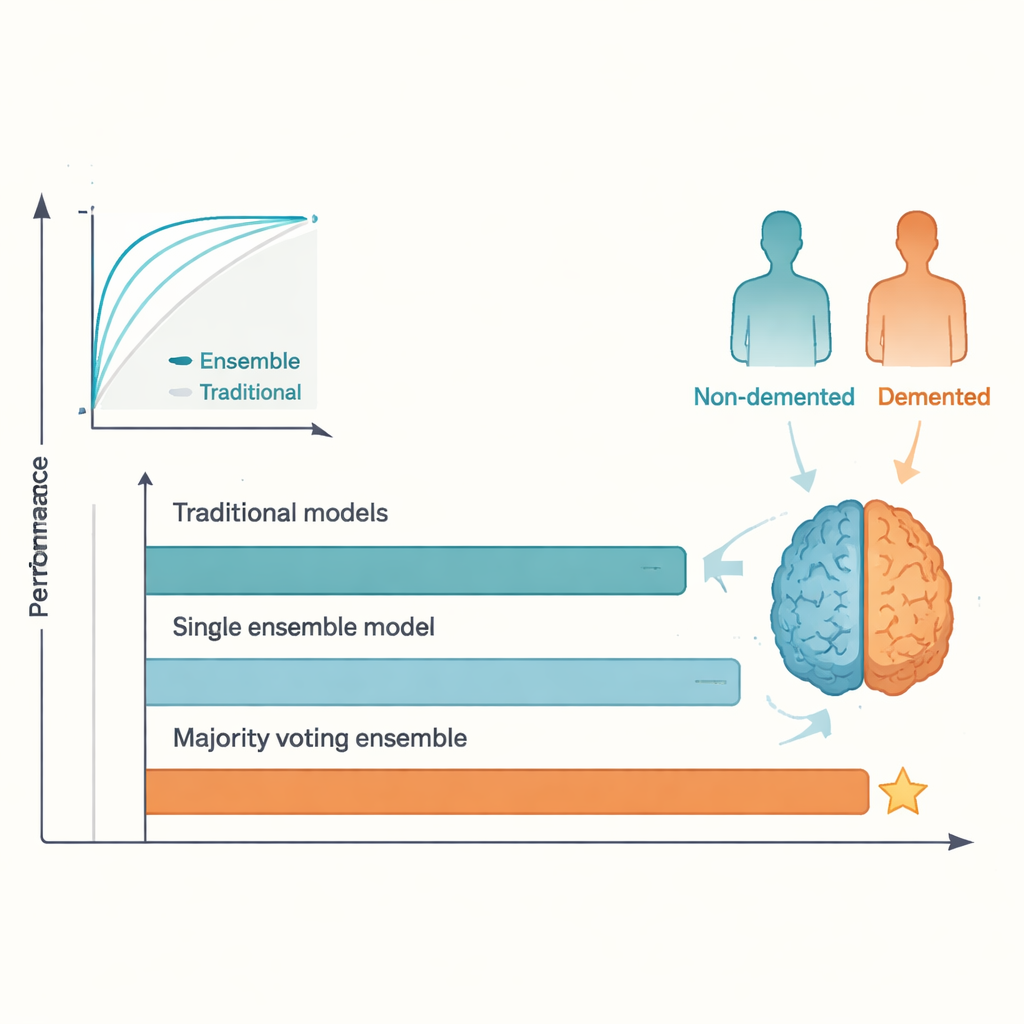
Procurando agrupamentos naturais nos dados
Além de perguntar quem tem demência, os pesquisadores também investigaram como os pacientes se agrupam naturalmente, independentemente dos rótulos de diagnóstico. Para isso, transformaram todas as variáveis contínuas em categorias ordenadas — como faixas de idade ou de volume cerebral — e aplicaram uma técnica chamada análise de correspondência múltipla para comprimir essa informação rica em um punhado de dimensões subjacentes. Em seguida, usaram clustering k-means para particionar esses pontos em um pequeno número de grupos coerentes. Alguns clusters foram dominados por pessoas com volume cerebral preservado e pontuações cognitivas normais, enquanto outros continham indivíduos com baixo volume cerebral, resultados de testes ruins e avaliações de demência mais severas. O fato de esses clusters não supervisionados se alinharem bem com o status clínico sugere que os dados carregam um sinal forte e consistente sobre o risco e a progressão da doença.
O que isso significa para pacientes e clínicos
Para um público leigo, a conclusão é simples: quando bem projetadas, equipes de modelos de aprendizado de máquina podem identificar demência relacionada ao Alzheimer em dados clínicos estruturados com mais precisão do que métodos mais antigos, e podem fazê-lo usando informações que muitas clínicas já coletam. Ao mesmo tempo, técnicas exploratórias revelam que as pessoas se enquadram em perfis distintos de saúde cerebral e função cognitiva, sugerindo diferentes trajetórias que a doença pode seguir. Embora o estudo seja limitado pelo tamanho modesto da amostra e pela complexidade de interpretar modelos em conjunto, ele mostra que combinar predição poderosa com análise exploratória cuidadosa pode tanto aprimorar a detecção precoce quanto aprofundar nossa compreensão de como o Alzheimer se instala.
Citação: Amr, Y., Gad, W., Leiva, V. et al. Comparative analysis of supervised and ensemble models with unsupervised exploration for alzheimer’s disease prediction. Sci Rep 16, 7322 (2026). https://doi.org/10.1038/s41598-026-37122-9
Palavras-chave: Doença de Alzheimer, previsão de demência, aprendizado de máquina, modelos em conjunto, imagem cerebral