Clear Sky Science · pt
Estudo comparativo sobre previsão de metástase à distância pós-operatória do câncer de pulmão com base em modelos de aprendizado de máquina
Por que prever a disseminação do câncer é importante
O câncer de pulmão continua sendo um dos mais letais, mesmo quando os cirurgiões removem todos os tumores visíveis. Muitos pacientes desenvolvem mais tarde depósitos de câncer ocultos que surgem no cérebro, ossos, fígado ou outros órgãos. Os médicos gostariam de saber, logo após a cirurgia, quais pacientes têm maior probabilidade de apresentar esse tipo de disseminação à distância, para assim personalizar consultas de acompanhamento e tratamentos. Este estudo investiga se programas computacionais modernos, conhecidos como modelos de aprendizado de máquina, podem ajudar a prever quem está em maior risco, usando informações que os hospitais já registram na prática rotineira.
Analisando um grande número de pacientes
Os pesquisadores examinaram registros de 3.120 pessoas com câncer de pulmão em estádio I a III que tiveram seus tumores removidos em um único centro de câncer na China. Todos tiveram pelo menos dois anos de acompanhamento. Para cada paciente, a equipe coletou 52 tipos de informações, incluindo idade, sexo, peso corporal, histórico de tabagismo, achados de imagem, detalhes da operação, exames laboratoriais e se receberam tratamentos adicionais, como quimioterapia ou radioterapia, após a cirurgia. Ao longo do tempo, 596 desses pacientes desenvolveram metástases à distância, enquanto 2.524 não. Essa combinação de dados do mundo real permitiu à equipe identificar quais características estavam associadas à disseminação futura.
Ensinando computadores a reconhecer padrões de risco
Em vez de confiar em uma única fórmula, os cientistas compararam nove métodos diferentes de aprendizado de máquina, desde árvores de decisão simples até técnicas mais avançadas que combinam muitos modelos pequenos. Primeiro, usaram um filtro matemático para reduzir os 52 fatores originais a um conjunto menor e mais informativo. Depois, em rodadas repetidas, treinaram cada modelo em parte dos dados e o testaram em pacientes que ele nunca “viera a conhecer”. Como apenas cerca de um em cada cinco pacientes desenvolveu metástase, ajustaram o treinamento para que o computador não passasse a prever “baixo risco” para todos. Avaliaram o desempenho usando várias medidas, incluindo quão bem os modelos separavam pacientes de alto e baixo risco e quão próximas as probabilidades previstas estavam dos resultados observados.
Encontrando o modelo mais confiável
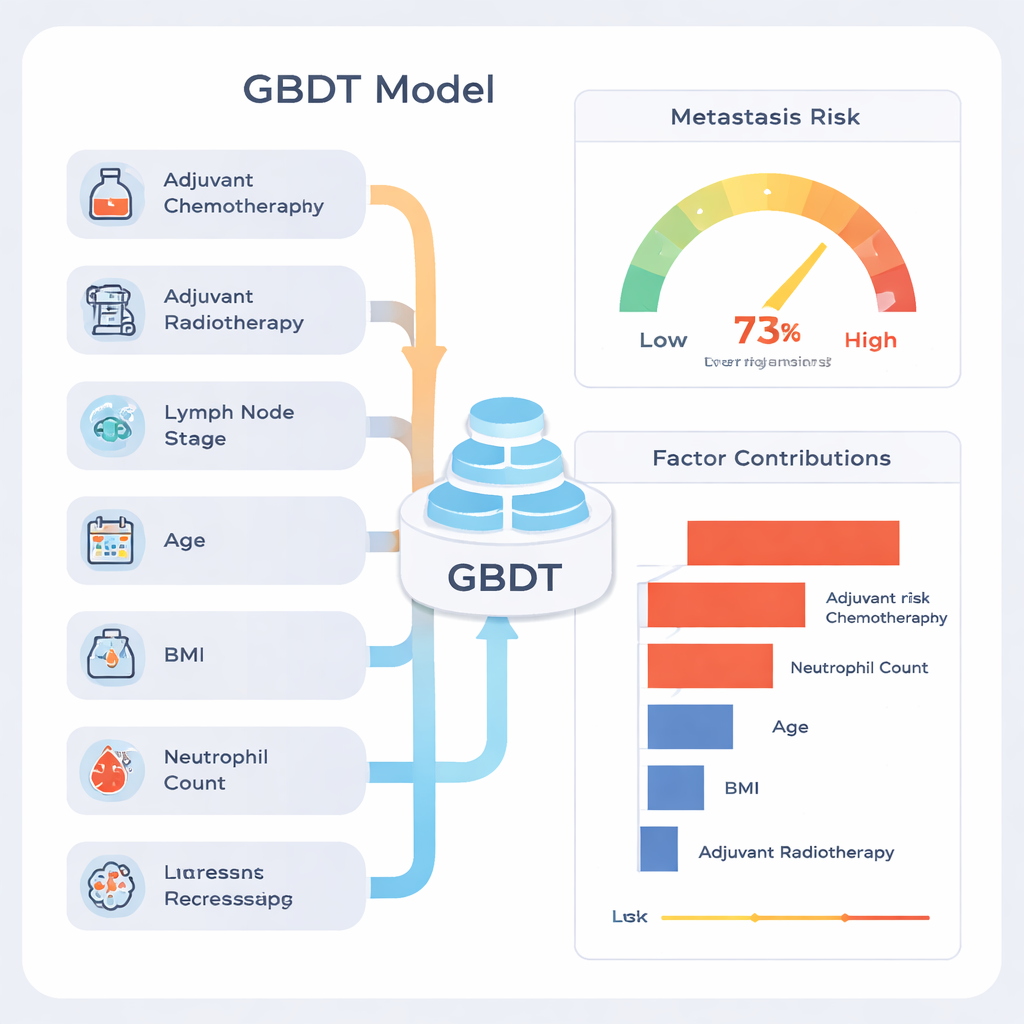
Entre as nove abordagens, uma chamada Gradient Boosting Decision Tree (GBDT) destacou-se. Em dados de teste, classificou corretamente os pacientes com uma precisão geral de cerca de 77%, e sua pontuação resumida de discriminação (a área sob a curva ROC) foi 0,81, valor considerado forte para ferramentas de predição médica. O modelo foi especialmente bom em identificar pacientes que permaneceram livres de metástase (alto “valor preditivo negativo”), o que significa que um resultado de baixo risco costumava ser tranquilizador. Quando a equipe examinou o comportamento do modelo em muitas divisões aleatórias dos dados, seu desempenho permaneceu estável, sugerindo que não estava apenas memorizando peculiaridades de um subconjunto específico.
O que orienta as decisões do modelo
Uma crítica comum ao aprendizado de máquina é que ele pode ser uma “caixa-preta”. Para remediar isso, os autores usaram um método de explicação chamado SHAP, que atribui a cada fator uma contribuição para a estimativa final de risco de cada paciente. Essa análise mostrou que os sinais mais fortes foram se o paciente recebeu quimioterapia ou radioterapia após a cirurgia, quantos linfonodos continham câncer, idade, índice de massa corporal (IMC) e a contagem pré-operatória de neutrófilos, um tipo de glóbulo branco. Pacientes com maior envolvimento de linfonodos e sinais de inflamação sistêmica tenderam a ter risco previsto mais alto. Os autores enfatizam que contribuições altas vindas de quimioterapia e radioterapia não significam que esses tratamentos causem metástase; em vez disso, são marcadores de que os médicos já haviam julgado a doença como mais agressiva, de modo que esses pacientes começaram com risco maior.
Como isso pode ajudar pacientes na prática
Como o modelo usa informações que a maioria dos centros de câncer já registra, ele poderia, após testes adicionais, ser incorporado ao software hospitalar. Para um novo paciente que acabou de passar por cirurgia pulmonar, o sistema poderia coletar seus dados e fornecer uma probabilidade personalizada de metástase à distância, junto com uma explicação simples de quais fatores aumentam ou diminuem o risco. Os clínicos poderiam então usar essa informação para decidir quem precisa de acompanhamento por imagem mais rigoroso, aconselhamento extra ou inclusão em estudos clínicos, e quem poderia evitar vigilância intensiva com segurança. O estudo foi realizado em um único hospital, portanto a ferramenta ainda precisa ser verificada e refinada em outras regiões e sistemas de saúde. Mas oferece um roteiro promissor para combinar dados clínicos de rotina com aprendizado de máquina transparente para melhorar o cuidado a longo prazo de pessoas com câncer de pulmão.
Citação: Guo, X., Xu, T., Luo, Y. et al. Comparative study on predicting postoperative distant metastasis of lung cancer based on machine learning models. Sci Rep 16, 6468 (2026). https://doi.org/10.1038/s41598-026-37113-w
Palavras-chave: câncer de pulmão, metástase à distância, aprendizado de máquina, previsão de risco, acompanhamento pós-operatório