Clear Sky Science · pt
Resumo temporal inovador para classificação complexa de vídeos
Por que resumos de vídeo mais inteligentes importam
De câmeras de segurança a plataformas de streaming, o mundo está gravando mais vídeo do que humanos ou computadores conseguem processar confortavelmente. Cada segundo de filmagem contém dezenas de quadros, mas muitos desses quadros são quase idênticos. Este artigo explora uma forma de reduzir vídeos longos aos momentos mais reveladores, para que os computadores ainda consigam reconhecer ações como cozinhar, praticar esportes ou passear com um cachorro — usando bem menos tempo, memória e energia. Avanços assim podem ajudar a levar análise de vídeo poderosa para dispositivos do dia a dia, desde robôs domésticos até câmeras vestíveis.

De quadros intermináveis a momentos-chave
Sistemas tradicionais de classificação de vídeo tentam reconhecer o que está acontecendo em um clipe — por exemplo, cortar legumes ou arremessar uma bola — alimentando longas sequências de quadros em modelos pesados de deep learning. Esses modelos precisam lidar tanto com aparência (como as coisas parecem) quanto com temporalidade (como elas se movem ao longo do tempo). Processar todos os quadros leva a conjuntos de dados grandes, alta demanda de armazenamento e computação lenta e com alto consumo de energia. Os autores defendem que muitos desses quadros são redundantes: se nada significativo muda de um quadro para o outro, o sistema ganha pouco ao analisar ambos. A ideia central do artigo é selecionar um conjunto muito menor de “quadros-chave” que ainda capture as mudanças importantes na cena.
Medindo mudança entre quadros
Para encontrar esses momentos-chave, os pesquisadores concebem e comparam várias formas de medir o quanto um quadro difere de outro. Em vez de depender apenas da clássica distância euclidiana, que compara todos os pixels de forma uniforme, eles testam alternativas mais sensíveis a mudanças estruturais. A principal proposta, chamada distância “Norma das Linhas” (Norm of Rows), foca na maior diferença ao longo de cada linha de pixels e então toma a linha mais pronunciada como medida de mudança entre dois quadros. Eles também exploram distâncias baseadas em colunas e métodos fundamentados nos autovalores de matrizes que resumem como as diferenças de pixels se distribuem. Todas essas abordagens visam detectar melhor movimentos ou mudanças de cena significativas, como uma mão alcançando um utensílio ou um jogador saltando.
Como funciona o pipeline de sumarização
O processo de sumarização começa com o primeiro quadro do vídeo, que é tratado como o quadro-chave inicial. O sistema então compara esse quadro-chave com cada quadro subsequente usando uma das medidas de distância. Sempre que a distância ultrapassa um limiar escolhido, o quadro correspondente é marcado como um novo quadro-chave, indicando que algo visualmente importante mudou. O procedimento repete-se usando esse novo quadro-chave como referência, avançando pelo vídeo e coletando uma cadeia de instantâneos representativos. Ao ajustar o limiar, o método pode manter tão pouco quanto 20% ou até 80% dos quadros originais, trocando compactação por detalhe. Essas sequências resumidas são então passadas para um classificador padrão de deep learning que combina uma poderosa rede de imagens (ResNet-50) com um módulo LSTM sensível ao tempo.
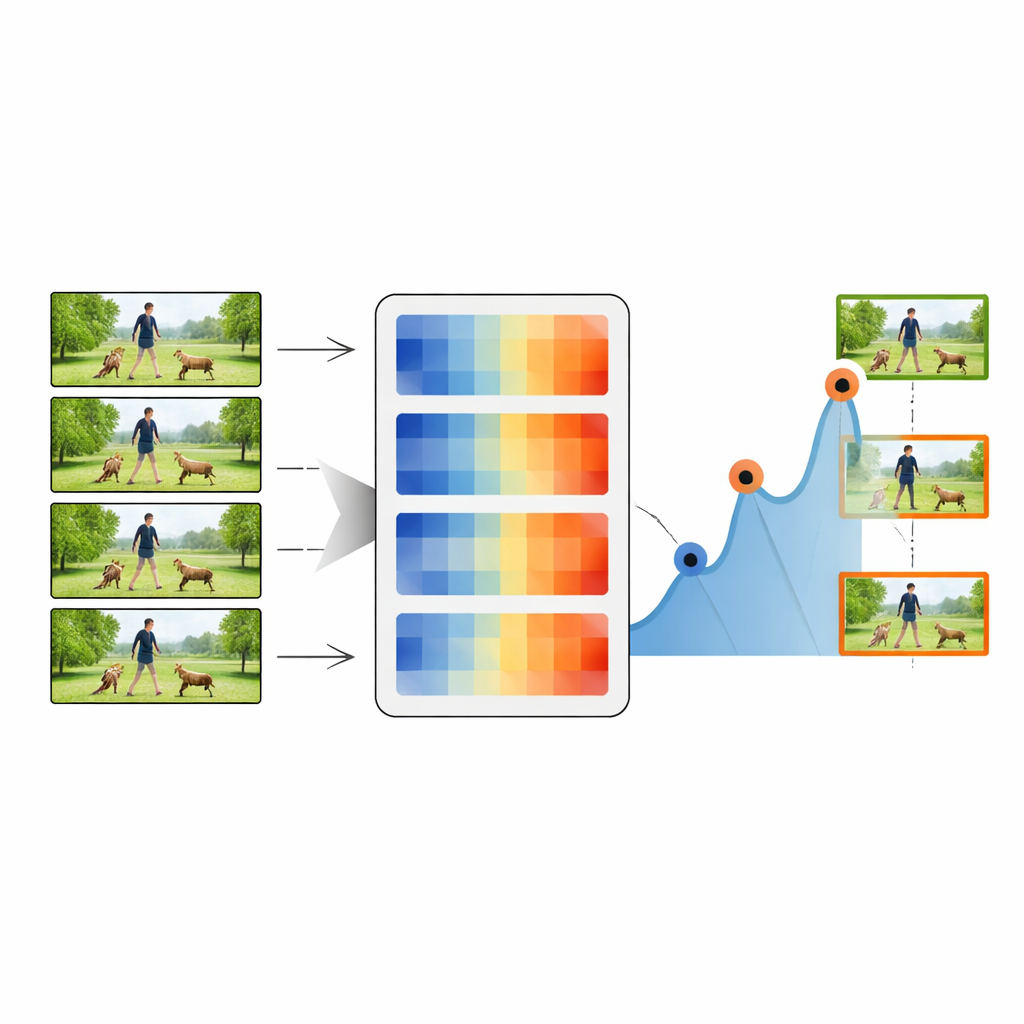
Colocando o método à prova
Os autores avaliam rigorosamente sua abordagem em quatro coleções de vídeo bem conhecidas: atividades domésticas na cozinha (MMAC), esportes e ações gerais (UCF101 e UCF11) e clipes mais variados e desafiadores (HMDB51). Nesses benchmarks, a distância Norma das Linhas consistentemente oferece o melhor equilíbrio entre velocidade e precisão. Com apenas cerca de metade dos quadros retidos, seu sistema alcança precisões de classificação superiores a 90% em vários conjuntos de dados — muitas vezes igualando ou superando métodos mais complexos que usam vídeos completos e não resumidos. Eles também medem quão bem os resumos cobrem o conteúdo original, quão redundantes são os quadros selecionados e quão diversas se tornam as cenas capturadas. A métrica proposta atinge alta cobertura com baixa redundância, o que significa que preserva a narrativa do vídeo sem repetir quadros semelhantes.
Decisões mais rápidas para vídeo no mundo real
Ao reduzir o número de quadros aproximadamente pela metade, o método quase reduz pela metade o tempo de processamento em hardware de computador padrão e ainda proporciona acelerações perceptíveis mesmo em placas gráficas modernas. Para sistemas do mundo real que precisam reagir em tempo real — como vigilância, robôs autônomos ou aplicativos móveis — essa redução de carga de trabalho é crucial. O estudo mostra que uma medida de distância cuidadosamente desenhada pode atuar como um guardião inteligente, escolhendo quais quadros merecem atenção e quais podem ser descartados com segurança.
Conclusão para o uso cotidiano
Em termos simples, este trabalho mostra que computadores não precisam assistir a cada quadro para entender o que está acontecendo em um vídeo. Ao focar nos momentos em que a imagem realmente muda e ignorar quase-duplicatas, a técnica proposta preserva a essência de uma ação enquanto reduz drasticamente a quantidade de dados. Isso torna o entendimento de vídeo de alta qualidade mais prático em hardware limitado e abre caminho para ferramentas mais rápidas e eficientes para analisar o crescente volume de informação visual em nossa vida diária.
Citação: Khan, A., Rahnama, A., Islam, A. et al. Innovative temporal summarization for complex video classification. Sci Rep 16, 7970 (2026). https://doi.org/10.1038/s41598-026-37111-y
Palavras-chave: classificação de vídeo, resumo de vídeo, seleção de quadros-chave, reconhecimento de ação, eficiência em visão computacional