Clear Sky Science · pt
Construção e aplicação de um grafo de conhecimento para documentos de normas de qualidade de sementes
Por que as regras de sementes importam para a alimentação de todos
Por trás de cada saco de arroz ou de cada pacote de sementes de hortaliças está um labirinto de normas técnicas que protegem de forma discreta a produtividade das culturas e a segurança alimentar. Ainda assim, essas regras de qualidade das sementes geralmente ficam enterradas em documentos PDF densos, difíceis de pesquisar ou interpretar por agricultores, reguladores e empresas. Este estudo mostra como transformar esses documentos estáticos em um “mapa” vivo de fatos conectados — um grafo de conhecimento — pode tornar as normas agrícolas mais transparentes, pesquisáveis e preparadas para a era da agricultura digital. 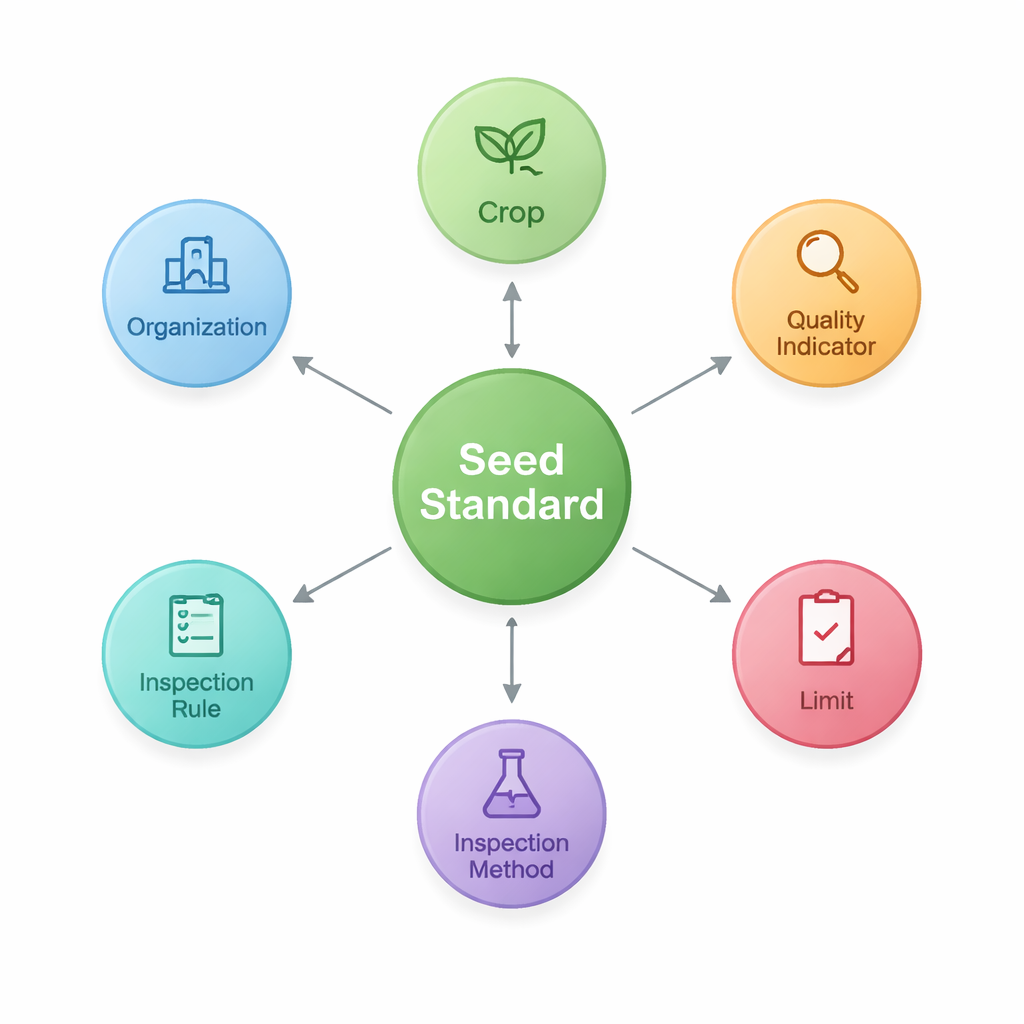
Das normas em papel à informação inteligente
As normas de qualidade de sementes definem o que conta como semente aceitável: quão puro deve ser o lote, quantas sementes devem germinar, qual é a umidade permitida e os métodos usados para testar essas características. Na China, o número desses documentos explodiu, e muitos ainda existem apenas como páginas escaneadas ou texto não estruturado. A busca por palavras-chave simples tem dificuldade em responder perguntas práticas como “Quais são os limites de pureza para essa cultura?” ou “Qual regra substituiu uma anterior?”. Os autores afirmam que, para acompanhar as rápidas mudanças na agricultura, essas normas precisam passar de páginas legíveis por humanos para conhecimento compreensível por máquinas que possa suportar consultas rápidas, comparações e verificações automatizadas.
Construindo um mapa do conhecimento sobre sementes
Para isso, os pesquisadores primeiro projetam uma “ontologia” — um roteiro compartilhado que define os principais blocos das normas de sementes e como eles se conectam. Identificam sete tipos centrais de entidades, incluindo a própria norma, a cultura que ela cobre, indicadores de qualidade como pureza ou taxa de germinação, os limites numéricos para esses indicadores, os métodos e regras de inspeção, e as organizações que elaboram ou publicam os documentos. Essa estrutura captura padrões como “Cultura–Indicador de Qualidade–Limite”, especialmente importantes na agricultura. Usando esse roteiro, eles então armazenam os fatos extraídos como nós e ligações em um banco de dados em grafo (Neo4j), criando uma teia de 2.436 entidades conectadas por 3.011 relacionamentos.
Combinando regras e aprendizado de máquina
O desafio real está em extrair fatos limpos e confiáveis de documentos-fonte confusos. As normas de sementes misturam tabelas bem formatadas, metadados rígidos na página de rosto e longas cláusulas de texto livre. Nenhuma técnica única lida bem com tudo isso. A equipe, portanto, constrói um sistema híbrido de extração. Usam padrões de regra precisos (expressões regulares) para ler tabelas estruturadas e informações básicas do documento, que tendem a seguir formatos estritos. Para o texto narrativo mais complexo — como regras detalhadas de inspeção — treinam uma cadeia de modelos modernos chamada BERT–BiLSTM–CRF para reconhecer nomes-chave, códigos e termos técnicos. Esse modelo aprende a partir de exemplos cuidadosamente rotulados e consegue identificar entidades mesmo quando aparecem com redações variadas e em frases longas. 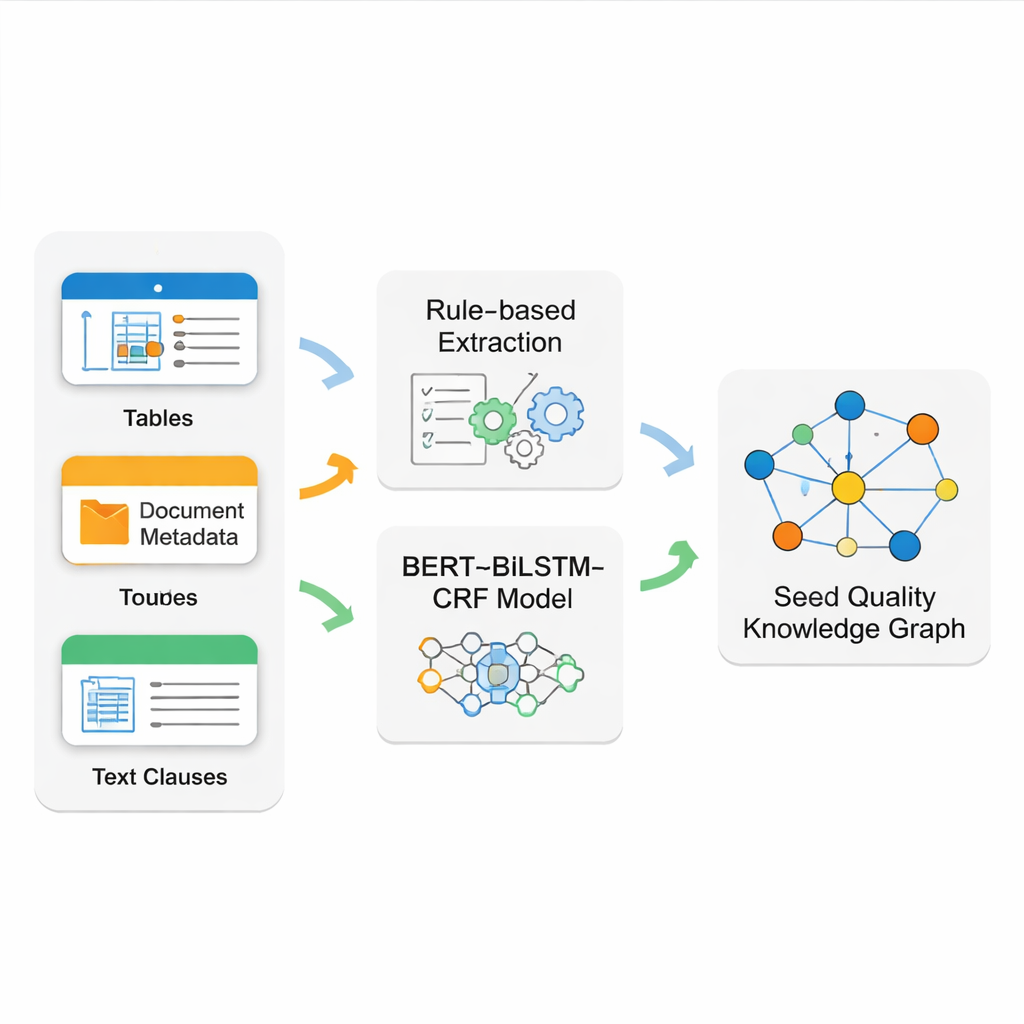
Desempenho do sistema na prática
Ao ser testada, a abordagem híbrida apresenta bom desempenho. O modelo de linguagem alcança uma pontuação F1 geral (um equilíbrio entre precisão e completude) de cerca de 91,6%, superando dois modelos de referência comumente usados. É particularmente eficaz na identificação de elementos estruturados como códigos de norma e mantém desempenho robusto mesmo em tarefas mais difíceis, como regras de inspeção longas. Uma vez que todas essas informações são carregadas no grafo de conhecimento, os usuários podem explorar visualmente como uma norma se relaciona a versões anteriores, quais organizações a redigiram, quais culturas e indicadores ela cobre e quais métodos de teste prescreve. Em vez de folhear PDFs extensos, reguladores e empresas de sementes podem executar buscas direcionadas e ver resultados conectados em segundos.
O que isso significa para agricultores e sistemas alimentares
Para não especialistas, o resultado é uma forma mais inteligente de gerenciar as regras que mantêm as sementes confiáveis e as culturas produtivas. O estudo mostra que, combinando um projeto conceitual claro com extração baseada em regras e baseada em aprendizado, é possível converter normas de sementes dispersas em uma base de conhecimento coerente e pesquisável. Isso estabelece alicerces técnicos para normas “INTELIGENTES” que os computadores podem ler, cruzar e atualizar conforme as regulações mudam. A longo prazo, tais ferramentas poderiam ajudar agricultores e empresas agropecuárias a confirmar rapidamente se sementes atendem aos requisitos atuais de qualidade, apoiar reguladores no acompanhamento de revisões e lacunas e contribuir para colheitas mais estáveis e para a segurança alimentar.
Citação: Yang, Z., He, Q. & Zhang, J. Construction and application of knowledge graph for seed quality standard documents. Sci Rep 16, 5997 (2026). https://doi.org/10.1038/s41598-026-37084-y
Palavras-chave: normas de qualidade de sementes, grafo de conhecimento, digitalização agrícola, reconhecimento de entidades nomeadas, normas inteligentes