Clear Sky Science · pt
Modelo de linguagem grande com base em conhecimento para geração de planos de treinamento esportivo personalizados
Planos de treino mais inteligentes para pessoas comuns
A maioria dos aplicativos de fitness promete treinamento personalizado, mas muitos ainda dependem de modelos genéricos que ignoram como seu corpo realmente está. Este artigo apresenta o LLM-SPTRec, um novo sistema que usa o mesmo tipo de modelos de linguagem grandes por trás dos chatbots modernos, combinado com conhecimento científico esportivo verificado e dados de wearables, para construir planos de treino mais seguros e eficazes. Para quem já se perguntou por que o app continua sugerindo exercícios inadequados — ou ficou preocupado se conselhos de saúde gerados por IA são realmente seguros — este trabalho mostra como tornar o coaching digital mais pessoal e mais científico.
Por que os aplicativos tradicionais de fitness ficam aquém
Mecanismos de recomendação convencionais, como os que sugerem filmes ou produtos, enfrentam dificuldades quando aplicados ao exercício. Frequentemente copiam e reutilizam modelos padrão, têm problemas para lidar com dados limitados de usuários novos e raramente consideram como seu corpo muda de um dia para o outro. Pior, não são projetados para decisões de alto risco nas quais a segurança importa. Modelos de linguagem de uso geral são bons em falar sobre treinos, mas como são treinados em textos amplos da internet, podem “alucinar” conselhos arriscados ou ignorar dias de descanso importantes. Os autores argumentam que, para o planejamento de exercícios — onde orientações inadequadas podem causar lesões ou overtraining — a IA precisa estar fundamentada em ciência do esporte verificada e deve acompanhar a condição em mudança da pessoa ao longo do tempo.
Construindo um retrato rico do indivíduo
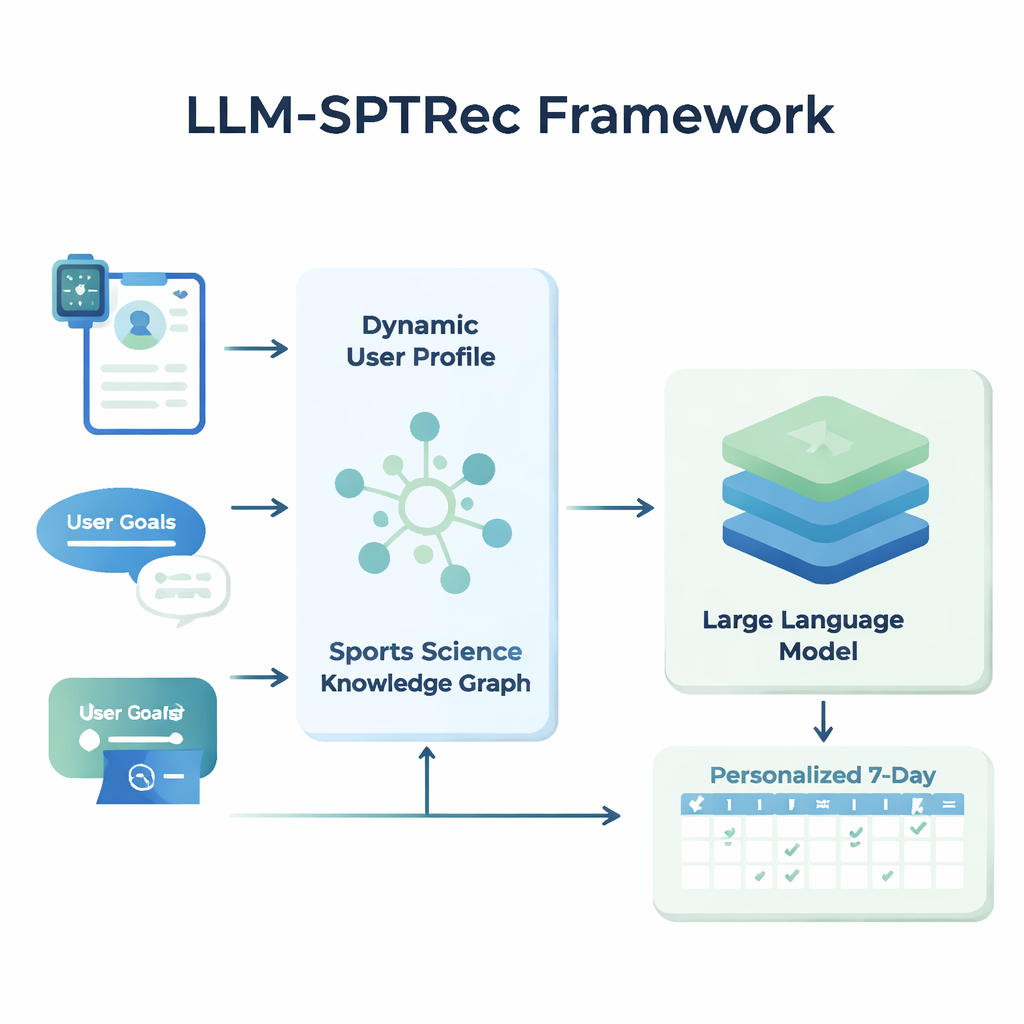
No centro do LLM-SPTRec está um módulo que cria um instantâneo detalhado de cada usuário. Em vez de apenas armazenar idade, gênero ou nível de experiência, o sistema funde três tipos de informação: traços estáticos (como histórico de treinamento), sinais dinâmicos (como frequência cardíaca, variabilidade da frequência cardíaca, pontuação do sono e treinos anteriores de wearables e registros) e objetivos em texto livre escritos pelo usuário. Um modelo baseado em transformer — relacionado à tecnologia por trás dos modelos de linguagem modernos — aprende padrões nesses dados em séries temporais, como o impacto de um treino intenso ontem na prontidão de hoje. Um mecanismo de atenção então pondera quais sinais importam mais em um dado momento, combinando-os em uma única representação numérica do estado atual do usuário.
Ensinando à IA a ciência do esporte real
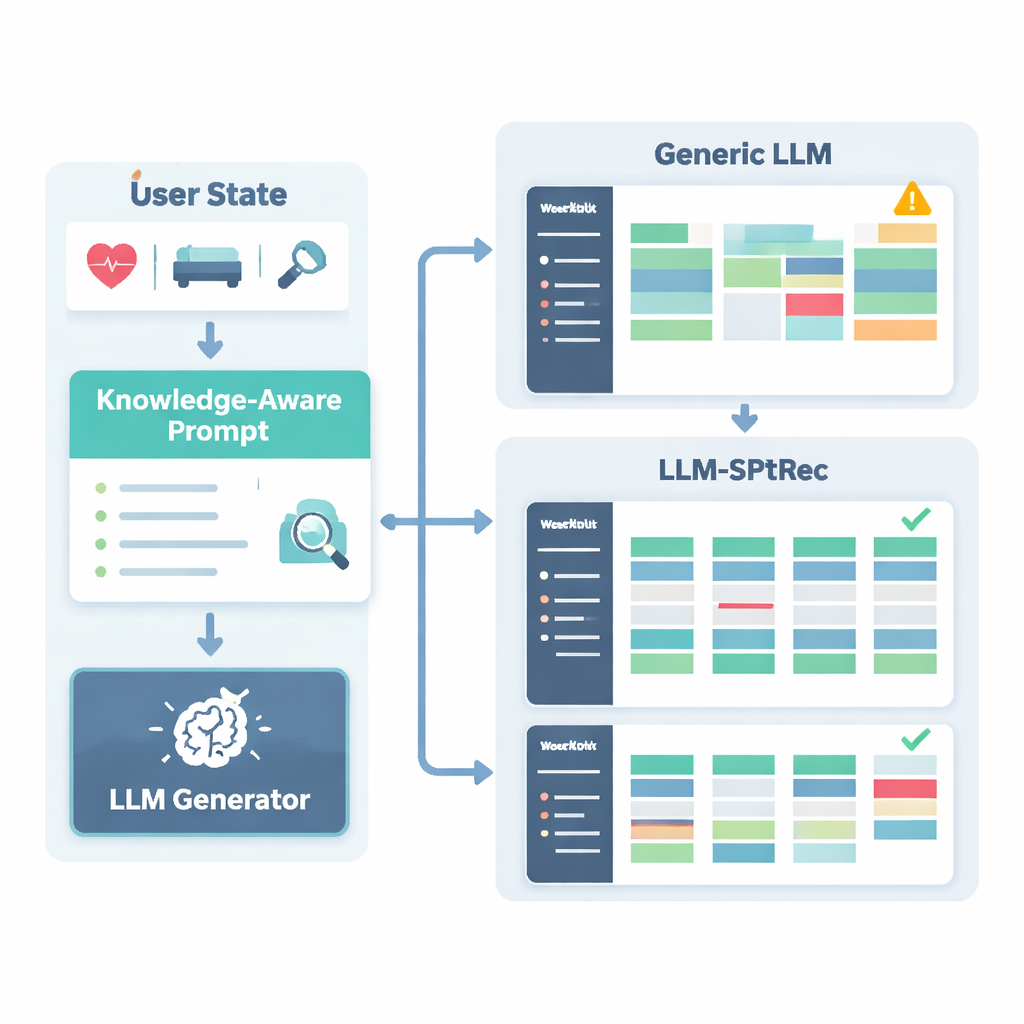
Para prevenir recomendações inseguras ou não científicas, os pesquisadores construíram um Grafo de Conhecimento em Ciência do Esporte, essencialmente um mapa estruturado de fatos aprovados por especialistas. Ele inclui milhares de entradas que relacionam exercícios a músculos, tipos de movimento, equipamentos, lesões comuns e princípios de treinamento como sobrecarga progressiva e especificidade. Para cada usuário, o sistema extrai as partes mais relevantes desse grafo — como quais músculos são ativados pelo supino e quais movimentos são prejudiciais para problemas no ombro — e as transforma em texto legível que é fornecido ao modelo de linguagem junto com o perfil do usuário. O modelo de linguagem é então solicitado, por meio de um prompt cuidadosamente elaborado, a gerar um plano de treinamento de vários dias em um formato estruturado, obedecendo a regras como alternância de grupos musculares entre os dias e evitando contraindicações conhecidas.
Mantendo os planos estruturados, seguros e em melhoria contínua
O LLM-SPTRec faz mais do que gerar texto. Um módulo de validação verifica cada plano contra regras rígidas, como não sobrecarregar os mesmos músculos primários em dias consecutivos, e sinaliza conflitos com riscos de lesão armazenados no grafo de conhecimento. Se um plano falhar nessas checagens, o sistema solicita ao modelo que gere novamente, apontando explicitamente o que deu errado, até que um plano seguro seja produzido. O treinamento do sistema também ocorre em duas etapas. Primeiro, ele aprende a partir de uma grande coleção de planos projetados por especialistas. Em seguida, é refinado usando feedback, onde avaliações simuladas ou reais de usuários recompensam planos coerentes, alinhados com objetivos e satisfatórios de seguir, enquanto punem fortemente sugestões inseguras. Esse ciclo de feedback orienta o modelo para recomendações que funcionam melhor na prática.
Desempenho do sistema na prática
Os autores testaram o LLM-SPTRec em um grande conjunto de dados do mundo real chamado SportFit-1M, que combina dados anonimizados de aplicativos de fitness e dispositivos wearables, cobrindo dezenas de milhares de usuários e milhões de registros de treino e dados fisiológicos. Compararam seu sistema com fortes linhas de base: filtragem colaborativa clássica, um modelo de sequência que olha apenas para escolhas passadas, um recomendador baseado em grafo de conhecimento de ponta e uma estrutura baseada em modelo de linguagem de uso geral. O LLM-SPTRec superou todos eles não apenas na seleção de exercícios apropriados, mas — mais importante — na produção de planos completos que especialistas julgaram mais coerentes e mais alinhados com os objetivos dos usuários. As pontuações previstas de satisfação do usuário também foram mais altas, e um pequeno estudo humano com treinadores certificados avaliou sua segurança muito melhor do que a de um modelo de linguagem geral sem fundamentação esportiva.
O que isso significa para o coaching digital futuro
Para leigos, a conclusão é que um coaching por IA mais inteligente e seguro é possível quando três ingredientes se combinam: dados ricos dos seus dispositivos, ciência do esporte especializada codificada como conhecimento estruturado e modelos de linguagem poderosos cuja criatividade é cuidadosamente guiada e verificada. O LLM-SPTRec mostra que essa combinação pode gerar planos de treinamento adaptativos, dia a dia, que respeitam o estado mutável do seu corpo e seus objetivos pessoais, enquanto reduzem o risco de conselhos prejudiciais ou sem sentido. Olhando adiante, a mesma receita poderia se estender além dos treinos para nutrição, reabilitação de lesões ou mesmo bem-estar mental, apontando para um futuro em que assistentes de IA atuem menos como chatbots genéricos e mais como treinadores digitais informados e conscientes da segurança.
Citação: He, Z., Wang, J., Zhang, B. et al. Knowledge-grounded large language model for personalized sports training plan generation. Sci Rep 16, 6793 (2026). https://doi.org/10.1038/s41598-026-37075-z
Palavras-chave: treinamento personalizado, IA em ciência do esporte, recomendação de fitness, dados de wearables, grafo de conhecimento