Clear Sky Science · pt
A evolução da detecção de objetos: de CNNs a transformers e fusão multimodal
Ensinando computadores a ver objetos do dia a dia
Cada vez que seu telefone marca amigos em uma foto, um carro detecta um pedestre, ou a ferramenta de um médico destaca um tumor em uma imagem, uma tecnologia discretamente poderosa está em ação: a detecção de objetos. Este artigo de revisão explica como a detecção de objetos evoluiu rapidamente na última década, desde truques iniciais de processamento de imagem até os atuais sistemas baseados em transformers e multi-sensores, e por que esses avanços importam para ruas mais seguras, robôs mais inteligentes e diagnósticos médicos mais precisos.
Dos pixels a coisas reconhecíveis
A detecção de objetos é a tarefa de localizar e rotular itens específicos em imagens ou vídeos — carros, ciclistas, animais, estruturas médicas e mais. O artigo começa mapeando como essa capacidade é amplamente usada: em direção autônoma, vigilância, imagens médicas e robótica. Sistemas iniciais dependiam de regras manuais para identificar formas e texturas, mas abordagens modernas aprendem diretamente a partir de dados usando aprendizado profundo. Duas famílias amplas dominam hoje: redes neurais convolucionais (CNNs), que são muito boas em detectar padrões locais como bordas e cantos, e transformers, que se destacam em entender a cena mais ampla e as relações entre objetos distantes. Juntas, elas definem como as máquinas atuais “veem” o mundo.
Como funcionam os motores clássicos de visão
Métodos baseados em CNN ainda alimentam muitas aplicações em tempo real. Eles varrem imagens com pequenos filtros para construir mapas de características cada vez mais ricos, então alimentam esses mapas em cabeças de detecção que desenham caixas delimitadoras e atribuem rótulos. A revisão explica duas estratégias principais. Sistemas de duas etapas como o Faster R-CNN primeiro propõem regiões prováveis de objetos e depois as refinam, frequentemente alcançando alta precisão a um custo computacional maior. Sistemas de etapa única como a família YOLO pulam a etapa de proposta e prevêem caixas e rótulos em uma única passagem, trocando um pouco de precisão por velocidade. Versões recentes como YOLOv5 e YOLOv8 foram fortemente ajustadas — adicionando pirâmides de características mais inteligentes para objetos pequenos, blocos de construção leves para dispositivos de borda e funções de perda aprimoradas — para atingir centenas de quadros por segundo enquanto se mantêm competitivas em benchmarks desafiadores.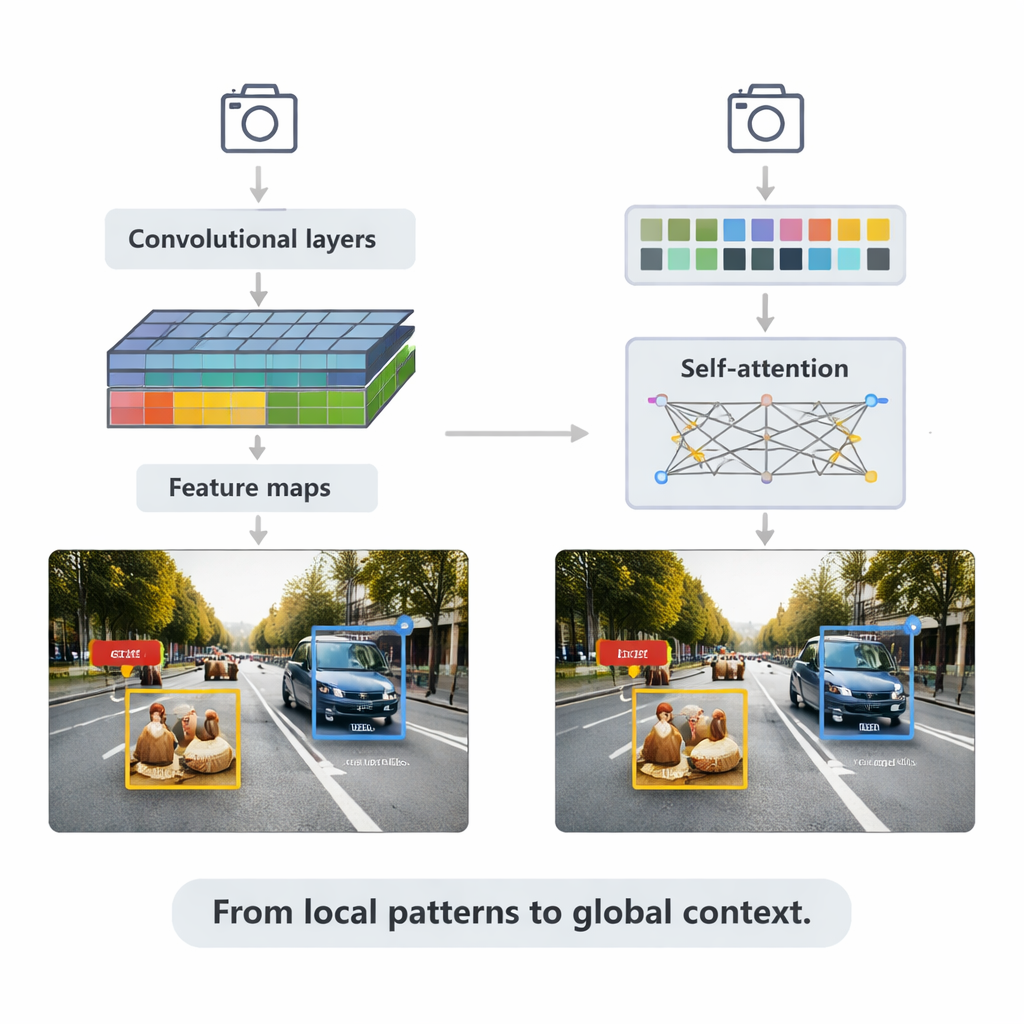
Transformers e o poder do contexto
O artigo então se volta para os transformers, uma arquitetura mais recente emprestada de modelos de linguagem. Em vez de focar apenas em vizinhanças locais, transformers usam “self-attention” para comparar cada patch da imagem com todos os outros, aprendendo quais regiões são mais relevantes para cada decisão. O Detection Transformer (DETR) e seus sucessores eliminam muitos truques feitos à mão, buscando pipelines mais limpos e de ponta a ponta. Variantes como Deformable DETR e RT-DETR reduzem o custo computacional e melhoram a velocidade de treinamento, permitindo que transformers rodem em tempo real enquanto alcançam algumas das maiores pontuações de precisão no amplamente usado benchmark COCO. Esses modelos brilham especialmente em cenas complexas com objetos sobrepostos e fundos confusos, onde o contexto global ajuda a distinguir, por exemplo, um pedestre parcialmente escondido atrás de um carro.
Combinando câmeras, lasers e linguagem
Condições do mundo real — neblina, escuridão, brilho, desordem — frequentemente derrotam sistemas de sensor único. Um foco importante da revisão é a fusão multimodal: combinar dados de câmeras regulares (RGB), sensores de profundidade como LiDAR, câmeras térmicas e até descrições em texto. Os autores apresentam uma taxonomia clara de como essa combinação pode ocorrer: fusão precoce mistura dados brutos desde o início, fusão intermediária funde características aprendidas dentro da rede, e fusão tardia combina as saídas de detectores separados ao final. “Fusion transformers” modernos usam mecanismos de atenção para alinhar esses fluxos, de modo que medidas de distância precisas do LiDAR, aparência rica das imagens RGB e pistas semânticas da linguagem se reforcem mutuamente. Essa abordagem melhora a detecção em direção autônoma, imagens médicas, compreensão de vídeo e cenas ricas em texto.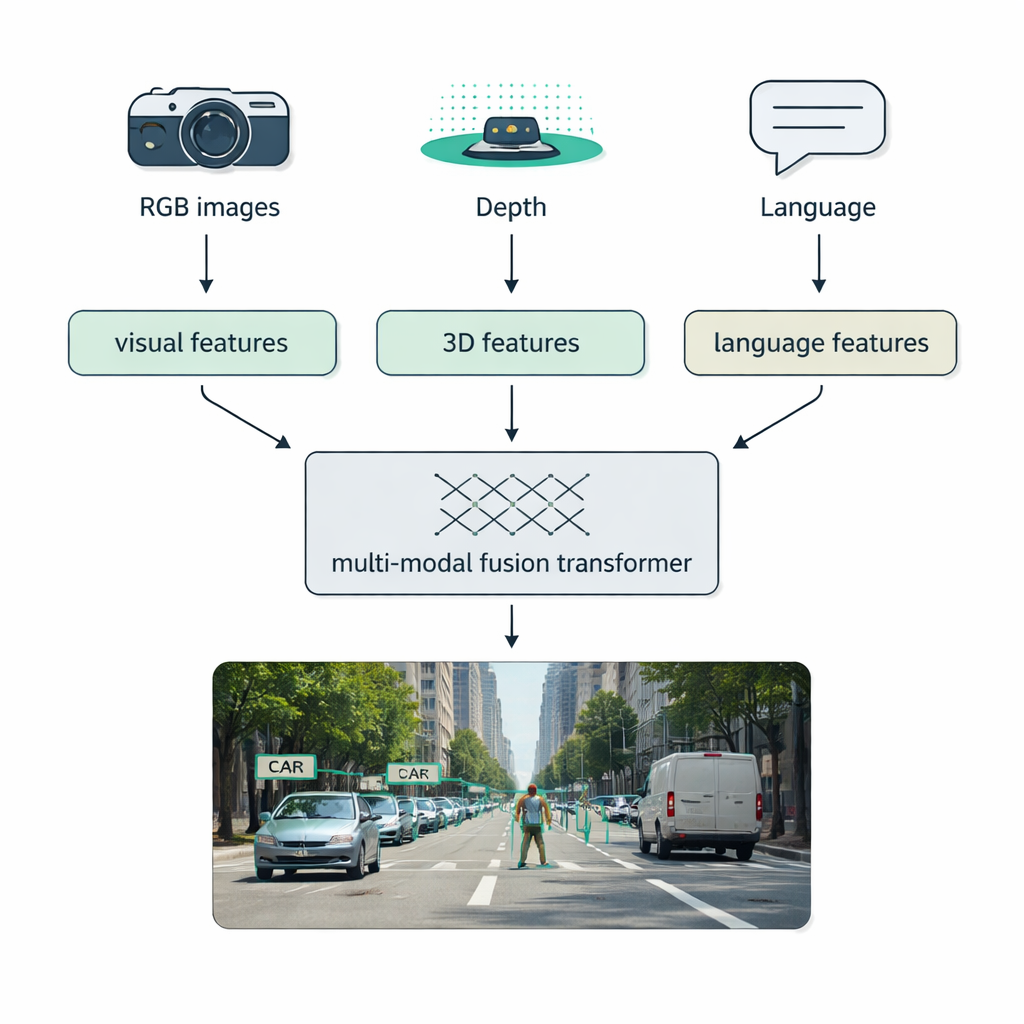
Benchmarks, limites e o que vem a seguir
Em testes padrão como o MS COCO, a revisão compara detectores baseados em CNN e transformers tanto por precisão quanto por velocidade. CNNs clássicas de duas etapas continuam fortes, mas são mais lentas; modelos ao estilo YOLO dominam em hardware leve; e sistemas baseados em transformer agora lideram em precisão enquanto reduzem a lacuna de velocidade. Métodos especializados em infravermelho atingem pontuações muito altas em condições de baixa visibilidade. Ainda assim, permanecem problemas difíceis: objetos muito pequenos ou extremamente grandes, forte oclusão, mudanças climáticas e de iluminação, e a necessidade de rodar de forma confiável em dispositivos minúsculos. Olhando adiante, os autores destacam tendências rumo a modelos de percepção unificados que lidam com detecção, segmentação e legendagem juntos, e “modelos fundação” que fundem visão e linguagem para reconhecer objetos descritos em texto simples, mesmo que nunca tenham sido rotulados nos dados de treinamento.
Por que isso importa para a vida cotidiana
Para não especialistas, a mensagem chave é que a detecção de objetos está se movendo de sistemas estreitos e ajustados manualmente para motores de visão flexíveis e de uso geral que podem se adaptar a novas tarefas, novos ambientes e novos sensores. CNNs oferecem reconhecimento de padrões rápido e eficiente; transformers adicionam um entendimento mais global e atento ao contexto; e a fusão multimodal incorpora pistas extras de profundidade, temperatura e linguagem. Juntos, esses avanços prometem carros que antecipam melhor os perigos, ferramentas que assistem médicos com mais confiança e dispositivos domésticos que interagem de forma mais segura e inteligente com o ambiente — aproximando a percepção das máquinas da riqueza da visão humana.
Citação: Wang, Z., Chen, Y., Gu, Y. et al. The evolution of object detection from CNNs to transformers and multi-modal fusion. Sci Rep 16, 7517 (2026). https://doi.org/10.1038/s41598-026-37052-6
Palavras-chave: detecção de objetos, visão computacional, aprendizado profundo, modelos transformer, fusão multimodal