Clear Sky Science · pt
Um benchmark para avaliar a eficiência de questionamento diagnóstico de LLMs em conversas com pacientes
Por que perguntas médicas mais inteligentes importam
Quando você consulta um médico, o primeiro diagnóstico que ouve raramente vem de um único sintoma que menciona. Em vez disso, os médicos fazem uma série de perguntas de seguimento — sobre tempo, intensidade, problemas associados — para, aos poucos, restringir o que pode estar errado. Por mais poderosos que sejam os sistemas de IA atuais, a maioria ainda é testada como se estivesse fazendo exames de múltipla‑escolha, e não conversando com pessoas reais. Este artigo apresenta o Q4Dx, uma nova forma de avaliar quão bem modelos de linguagem grande (LLMs) podem desempenhar o papel do “médico curioso”: escolher as perguntas certas, na ordem certa, para chegar ao diagnóstico apropriado de maneira eficiente.
De questões de prova para conversas reais
A maioria dos testes de IA médica existentes apresenta aos modelos casos bem definidos e totalmente especificados — como um problema de livro‑texto — e pede que escolham um diagnóstico. Isso mostra o que o sistema “sabe”, mas não como ele se comportaria em uma conversa fora do laboratório com um paciente que esquece detalhes ou descreve sintomas em linguagem cotidiana. Os autores sustentam que isso é uma falha séria. Em clínicas, a informação surge lentamente e muitas vezes de forma imprecisa; a habilidade de um bom clínico reside tanto no que ele pergunta quanto no que já sabe. O Q4Dx foi concebido para fechar essa lacuna ao deslocar o foco de respostas estáticas para a estratégia de fazer perguntas ao longo do tempo.
Construindo relatos de pacientes verossímeis
Para criar esse novo ambiente de teste, os pesquisadores partem de um recurso médico curado que associa doenças específicas a conjuntos característicos de sintomas. Eles selecionam aleatoriamente 100 desses pares doença–sintoma e então usam um modelo de IA para transformar listas estéreis de sintomas em autodescrições naturais de pacientes — histórias como as que uma pessoa realmente contaria em uma clínica. A partir de cada caso completo, geram versões mais curtas onde apenas cerca de 80% ou 50% dos sintomas-chave são mencionados. Esse “ocultamento” controlado de informação permite estudar como diferentes modelos se adaptam quando pistas importantes estão ausentes ou apenas sugeridas. Verificações de sobreposição de sintomas confirmam que as versões mais curtas realmente contêm menos informação útil, e não apenas menos palavras.
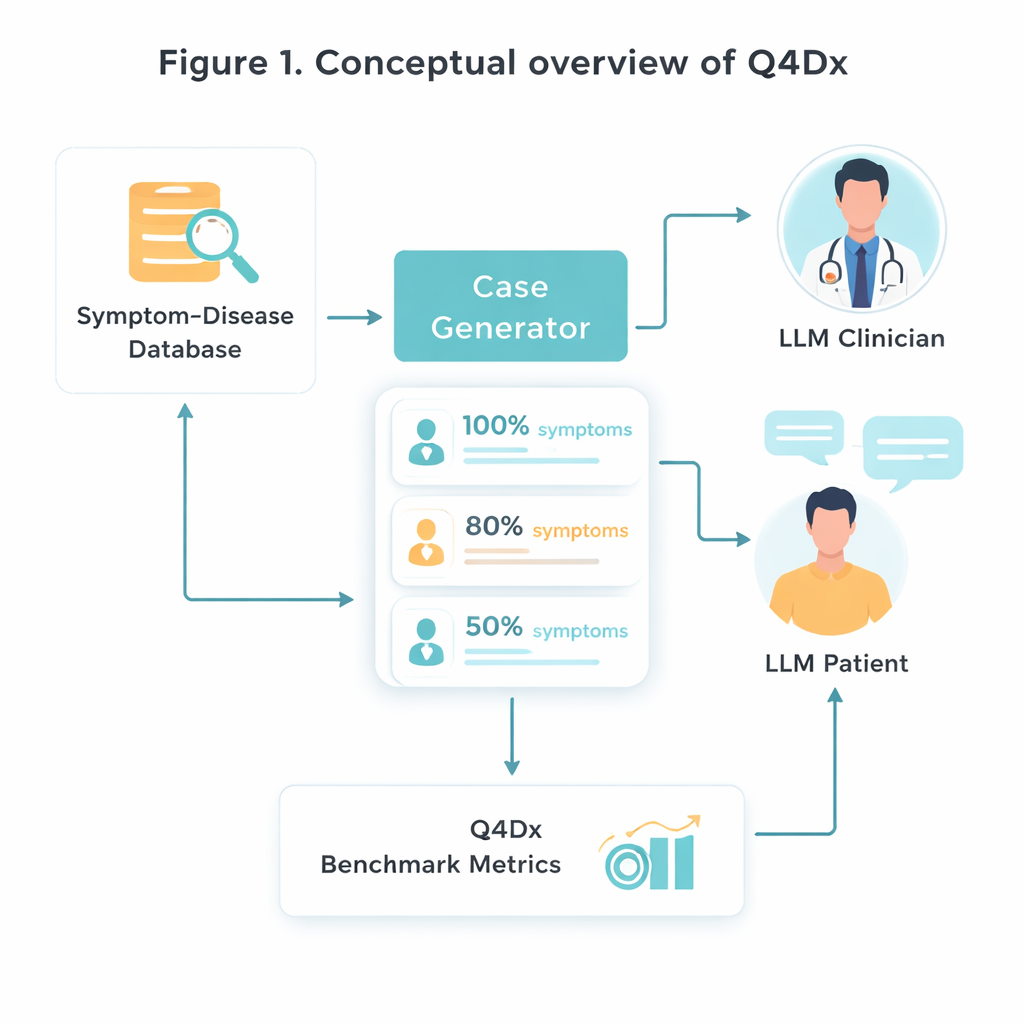
Diálogos simulados entre médico e paciente
O núcleo do Q4Dx é uma grande coleção de conversas simuladas entre dois agentes de IA. Um assume o papel do paciente, com acesso total à doença subjacente e ao conjunto completo de sintomas. O outro atua como médico: vê apenas uma descrição parcial e possivelmente vaga do caso no início e deve decidir qual pergunta fazer a seguir. Após cada resposta do paciente, o agente médico faz um diagnóstico provisório, criando um rastro passo a passo de como seu raciocínio evolui. Ao registrar todas as perguntas, respostas e palpites intermediários, o benchmark captura não só se o modelo está certo, mas como ele chega lá. Essas sequências de perguntas geradas por IA são usadas como estratégias de referência — não como a verdade médica perfeita, mas como um padrão consistente contra o qual futuros modelos e até estagiários humanos podem ser comparados.
Medindo boas perguntas, não apenas respostas corretas
Para avaliar o desempenho, os autores definem três medidas simples, porém complementares. Precisão Diagnóstica Zero‑Shot (ZDA) pergunta: se você der ao modelo o caso completo de antemão, ele consegue nomear imediatamente a doença correta? Média de Perguntas até o Diagnóstico Correto (MQD) reflete eficiência: em média, quantas perguntas ao paciente o modelo precisa antes de acertar o diagnóstico pela primeira vez, com um limite de cinco? Finalmente, Eficiência da Sequência de Interrogação (ISE) avalia a qualidade do próprio caminho de questionamento — quão semelhantes, em significado, são as perguntas escolhidas pelo modelo em relação à sequência de referência. Usando essas métricas, a equipe mostra que um modelo forte de uso geral (GPT‑4.1) diagnostica corretamente cerca de metade das vezes com informação completa, mas sua precisão cai conforme sintomas são ocultados. Ao mesmo tempo, suas sessões interativas tipicamente alcançam sucesso após apenas algumas perguntas bem escolhidas, e suas perguntas tornam‑se mais alinhadas com estratégias de especialistas ao longo das interações.

O que isso significa para a IA médica do futuro
Para não‑especialistas, a mensagem deste trabalho é direta: na medicina, fazer perguntas inteligentes é tão importante quanto ter as respostas corretas, e a IA precisa ser avaliada em ambos. O Q4Dx oferece um arcabouço reutilizável e publicamente disponível para fazer exatamente isso. Ao fornecer relatos realistas de pacientes com diferentes quantidades de informação faltante, traços detalhados de conversação e medidas claras tanto de precisão quanto de eficiência, o benchmark permite que pesquisadores comparem diferentes sistemas de IA e até os confrontem com clínicos humanos em condições controladas. Com o tempo, ferramentas como o Q4Dx podem ajudar a treinar assistentes clínicos mais seguros e confiáveis e melhorar a forma como médicos e estudantes aprendem a entrevista diagnóstica — apoiando, em última instância, um cuidado melhor para pacientes reais.
Citação: Werthaim, M., Kimhi, M., Apartsin, A. et al. A benchmark for evaluating diagnostic questioning efficiency of LLMs in patient conversations. Sci Rep 16, 6121 (2026). https://doi.org/10.1038/s41598-026-37022-y
Palavras-chave: IA médica, raciocínio diagnóstico, diálogo clínico, modelos de linguagem grande, estratégia de questionamento