Clear Sky Science · pt
MQADet: um paradigma plug-and-play para aprimorar a detecção de objetos de vocabulário aberto via questionamento multimodal
Por que detectores de objetos mais inteligentes importam
Telefones, carros, robôs domésticos e mecanismos de busca cada vez mais dependem de software capaz de localizar objetos em imagens: uma criança atravessando a rua, suas chaves perdidas sobre uma mesa ou um produto específico numa prateleira. Mas a maioria dos sistemas atuais entende apenas rótulos curtos e simples como “cachorro” ou “carro”. Quando você pede “o cachorrinho com coleira vermelha deitado atrás da almofada do sofá”, eles frequentemente se confundem. Este artigo apresenta o MQADet, uma forma de atualizar sistemas de detecção existentes para que entendam descrições ricas e detalhadas sem retreinar os modelos subjacentes.
De listas fixas a compreensão aberta
Detectores tradicionais são treinados em listas fixas de categorias, como os 80 itens do cotidiano no popular conjunto de dados COCO. Eles funcionam bem desde que o objeto pertença a uma dessas categorias e a solicitação seja curta e clara. No entanto, o mundo real é desordenado. As pessoas se referem a coisas usando frases longas, atributos sutis e relações, por exemplo, “o homem com colete amarelo em pé atrás do caminhão”. Detectores mais recentes de “vocabulário aberto” tentam romper com listas fixas associando imagens a texto, mas ainda têm dificuldade com formulações complexas e categorias raras ou com distribuição de cauda longa que aparecem pouco nos dados de treino. Além disso, melhorá‑los exige muito cálculo e muitos dados.
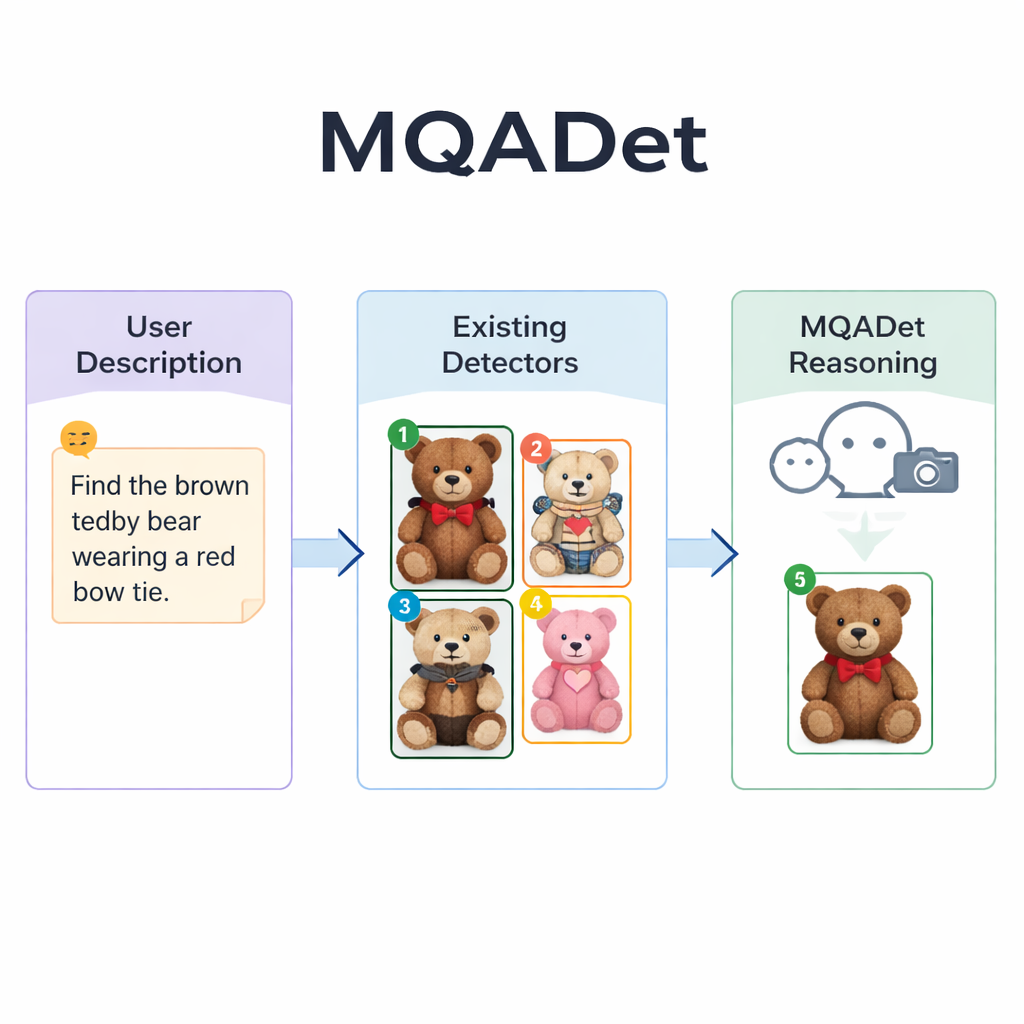
Perguntar ao modelo de linguagem para guiar a busca
MQADet enfrenta esses problemas colocando um grande modelo de linguagem multimodal — um sistema capaz de ver imagens e ler texto — por cima de detectores existentes em um processo de questionamento em três etapas. Primeiro, uma fase chamada Extração de Sujeitos Consciente de Texto lê a frase inteira do usuário e extrai os alvos reais, como “guarda‑chuva” e “pedestre” em uma descrição longa. Isso espelha como uma pessoa pode identificar rapidamente os substantivos principais antes de escanear uma cena. Crucialmente, essa etapa usa a forte compreensão da linguagem natural do modelo, permitindo lidar com frases descritivas longas em vez de apenas palavras isoladas.
Marcando candidatos na imagem
Na segunda etapa, Posicionamento Multimodal de Objetos Guiado por Texto, o MQADet entrega esses sujeitos extraídos junto com a imagem a um detector de vocabulário aberto existente — como Grounding DINO, YOLO‑World ou OmDet‑Turbo. O detector propõe várias localizações possíveis na imagem para cada sujeito, desenhando um retângulo ao redor de cada candidato e colocando um número simples dentro do retângulo. O resultado é uma “imagem marcada” mostrando todas as opções plausíveis. Importante: o MQADet não reentreina esses detectores; ele apenas os utiliza como estão. Isso torna a abordagem plug‑and‑play: sempre que surgir um detector melhor, ele pode ser inserido no pipeline sem dados ou ajuste adicionais.

Raciocinando até a melhor correspondência
A terceira etapa, chamada Seleção Ótima de Objetos Dirigida por MLLMs, transforma a escolha final em uma pergunta de múltipla escolha para o modelo de linguagem: dada a descrição original e a imagem marcada com caixas numeradas, qual número corresponde melhor ao texto? Como o modelo vê tanto a formulação detalhada quanto a disposição visual, ele pode ponderar pistas finas — padrões, cores, relações espaciais como “à esquerda” e interações entre objetos. Os autores mostram que remover essa etapa de raciocínio reduz fortemente a precisão, ressaltando sua importância. Usando esse design em três etapas, o MQADet melhorou a acurácia em quatro benchmarks exigentes com sentenças longas e naturais, frequentemente ampliando o desempenho de detectores existentes em 10–40 pontos percentuais sem alterar seus pesos internos.
O que isso significa para a tecnologia cotidiana
Para quem não é especialista, a mensagem principal é que não precisamos mais reconstruir detectores de objetos do zero para torná‑los mais inteligentes. O MQADet funciona como um assistente inteligente sobreposto aos sistemas atuais, ajudando‑os a interpretar descrições humanas ricas e a escolher o objeto correto em cenas complexas. Isso pode tornar a busca visual, ferramentas assistivas e máquinas autônomas mais confiáveis ao lidar com a forma natural como as pessoas falam — cheia de detalhes, nuances e contexto — abrindo caminho para uma interação com o mundo visual mais intuitiva e guiada por linguagem.
Citação: Li, C., Zhao, X., Zhang, J. et al. MQADet: a plug-and-play paradigm for enhancing open-vocabulary object detection via multimodal question answering. Sci Rep 16, 6286 (2026). https://doi.org/10.1038/s41598-026-36936-x
Palavras-chave: detecção de objetos de vocabulário aberto, grandes modelos de linguagem multimodais, resposta a perguntas visuais, visão computacional, compreensão de imagens