Clear Sky Science · pt
Reduzindo a lacuna de desempenho: otimização sistemática de LLMs locais para extração de PHI médica em japonês
Por que isso importa para a privacidade do paciente
Hospitais acumulam enormes coleções de anotações médicas que poderiam melhorar o atendimento e a pesquisa, mas esses registros estão repletos de detalhes sensíveis como nomes, endereços e datas. Sistemas de IA baseados em nuvem são muito eficientes em ocultar essas informações, contudo muitos hospitais não têm permissão para enviar dados brutos de pacientes a servidores externos. Este estudo mostra que, com ajuste cuidadoso, modelos de IA menores executados inteiramente dentro do hospital podem se aproximar surpreendentemente do desempenho dos melhores sistemas na nuvem — oferecendo uma maneira de usar IA mantendo os dados dos pacientes em segurança no local.
O dilema privacidade versus progresso
Modelos de linguagem grandes modernos conseguem identificar e remover informações de saúde protegidas (PHI) de textos médicos com confiabilidade, frequentemente superando 90% de acurácia. No entanto, enviar notas de pacientes sem edição para serviços na nuvem levanta preocupações legais e éticas sob regulações como HIPAA, GDPR e a APPI do Japão. Muitas instituições exigem “soberania de dados” completa, isto é, que a informação nunca deixe seus próprios computadores. Até agora, modelos locais que podem rodar em hardware interno normalmente deixavam passar muito mais identificadores, forçando os hospitais a escolher: análises mais avançadas na nuvem ou privacidade mais rígida com ferramentas menos eficazes. Os autores se propuseram a verificar se essa lacuna poderia ser reduzida o suficiente para uso clínico real.
Um plano em etapas para IA local mais inteligente
A equipe concebeu um framework de otimização em cinco etapas para melhorar gradualmente o desempenho de modelos de linguagem locais na remoção de PHI em laudos de radiologia em japonês. Começaram com 14 modelos diferentes de vários tamanhos, todos executados em um computador isolado, sem acesso à internet, para imitar a segurança hospitalar. Utilizando 160 laudos sintéticos cuidadosamente elaborados — realistas, porém inteiramente fictícios —, mediram quão bem cada modelo localizava e separava oito tipos de identificadores, de nomes e números de identificação a datas e departamentos. Após um teste inicial de linha de base, criaram prompts gerais mais úteis, depois instruções ajustadas às peculiaridades de cada modelo, adicionaram um ciclo automatizado de "auto-checagem e correção" e finalmente testaram os melhores candidatos em um conjunto reservado de laudos. 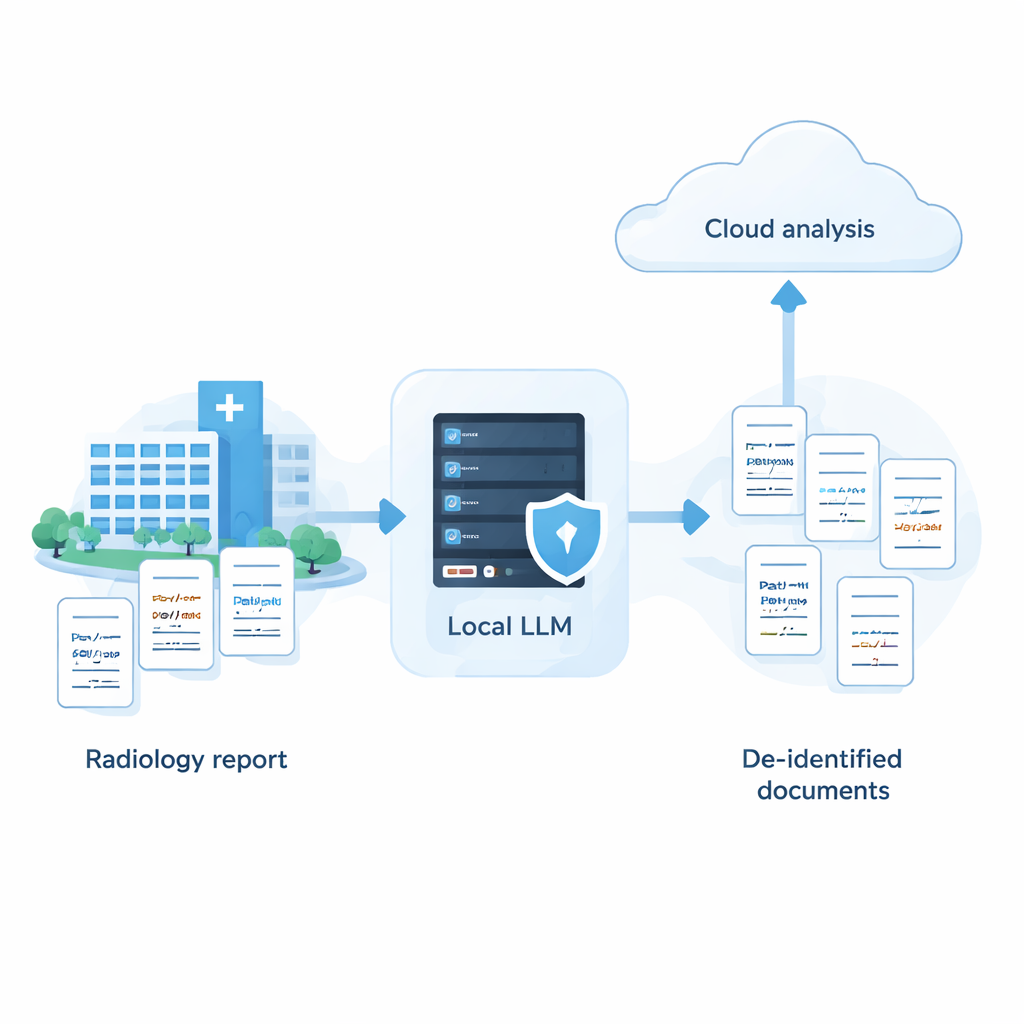
Aproximando-se do desempenho em nuvem
Por meio desse processo por etapas, os pesquisadores descobriram que o tamanho bruto do modelo não era a chave do sucesso; alguns sistemas muito grandes ainda tiveram desempenho ruim. Em vez disso, os modelos mais promissores foram aqueles que respondiam bem ao desenho cuidadoso de instruções e à análise de erros. Um sistema de porte médio, Mistral-Small-3.2, tornou-se o claro vencedor após prompts personalizados e uma etapa de autorrefinamento em que o próprio modelo revisava e corrigia seletivamente sua saída. Nos 60 casos de teste finais, essa configuração local otimizada marcou 91,54 de 100 — cerca de 97,8% dos 93,56 pontos do principal modelo em nuvem — enquanto obedecia perfeitamente às regras de formatação. Em termos práticos, a defasagem restante foi considerada clinicamente menor. O principal custo foi a velocidade: o processamento local levou cerca de 25 segundos por laudo típico, comparado a menos de 2 segundos na nuvem, mas isso foi considerado aceitável para trabalhos em lote rotineiros e não emergenciais. 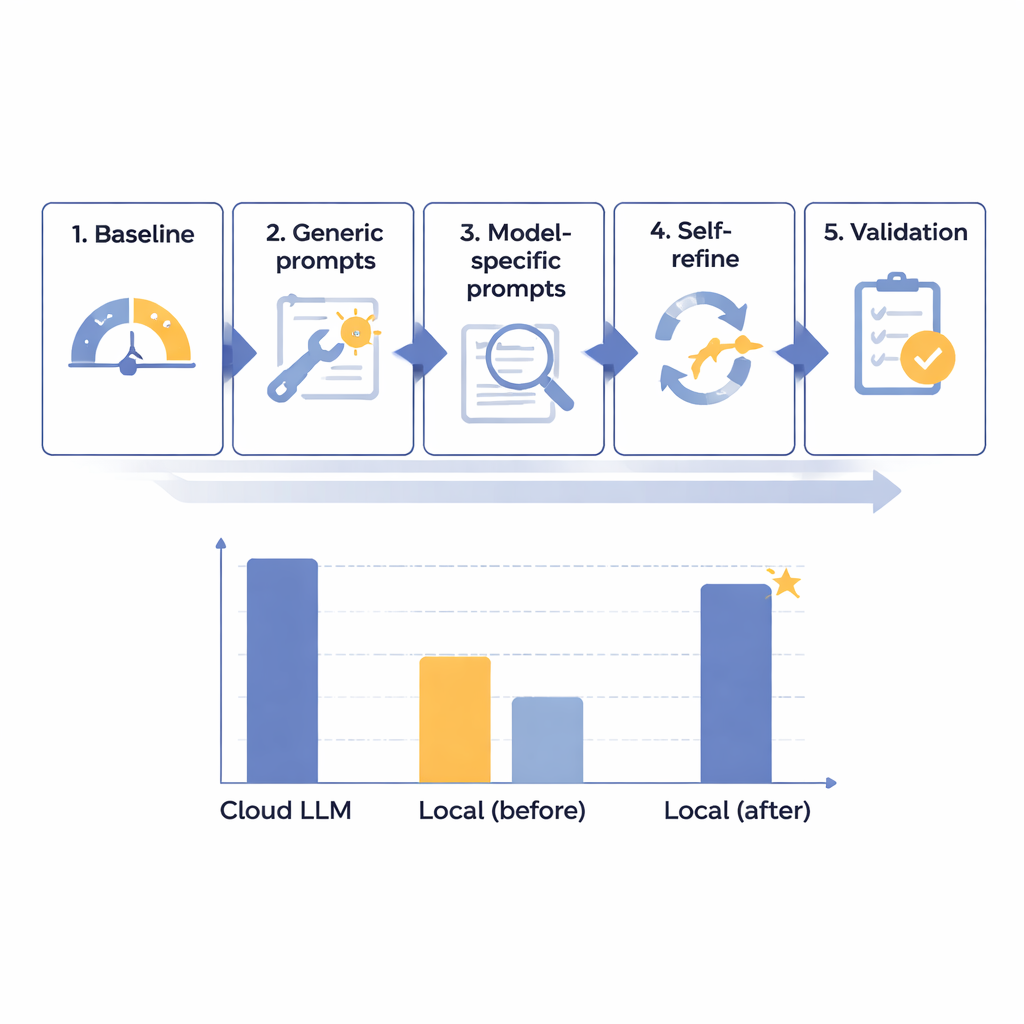
Um limiar surpreendente para autocorreção
Uma das descobertas mais intrigantes foi uma espécie de ponto de inflexão em torno de 87–88 pontos na escala de 100 pontos dos autores. Modelos que pontuaram abaixo desse nível na linha de base — como o Mistral-Small-3.2 — se beneficiaram muito do ciclo de autorrefinamento, ganhando quase sete pontos ao corrigir uma pequena fração dos próprios erros. Modelos que já começavam acima desse limiar mostraram quase nenhuma melhoria e, às vezes, desperdiçaram esforço tentando "corrigir" respostas corretas. Isso sugere que ferramentas avançadas de otimização devem ser reservadas para modelos que são bons, mas ainda não excelentes, oferecendo aos hospitais uma forma de concentrar poder de computação e tempo da equipe onde o retorno é maior. Os autores alertam que esse limiar se baseia em apenas dois modelos e precisa de confirmação, mas fornece uma regra prática inicial para planejamento de implantação.
O que isso significa para hospitais e pacientes
O estudo argumenta que hospitais não precisam escolher entre forte privacidade e IA poderosa. Com uma abordagem sistemática — avaliando muitos modelos, ajustando prompts às suas forças e fraquezas e adicionando uma etapa inteligente de autoavaliação — é possível que um sistema totalmente local se aproxime da precisão dos melhores serviços em nuvem para remover informações sensíveis de texto médico. Na prática, isso abre a porta para uma estratégia híbrida: a PHI é removida com segurança em máquinas pertencentes ao hospital, e apenas relatórios anonimizados, com nomes e outros identificadores removidos, são enviados para a nuvem para análises mais avançadas. Embora o trabalho até agora seja baseado em laudos sintéticos de radiologia em japonês e precise ser testado em dados do mundo real e em outros idiomas, oferece um roteiro acionável para instituições que desejam aproveitar a IA mantendo a confiança e a privacidade dos pacientes no centro.
Citação: Wada, A., Nishizawa, M., Yamamoto, A. et al. Bridging the performance gap: systematic optimization of local LLMs for Japanese medical PHI extraction. Sci Rep 16, 5910 (2026). https://doi.org/10.1038/s41598-026-36904-5
Palavras-chave: desidentificação médica, privacidade do paciente, modelos de linguagem locais, IA na saúde, laudos de radiologia