Clear Sky Science · pt
Detecção de objetos em SoCs de baixa capacidade computacional na borda: um benchmark reprodutível e diretrizes de implantação
Por que chips minúsculos importam para câmeras inteligentes
Muitos dos dispositivos “inteligentes” ao nosso redor — câmeras de segurança, drones, sensores industriais e campainhas — precisam identificar pessoas e objetos em tempo real, mas dependem de chips muito pequenos e de baixo consumo em vez de hardware pesado de data center. Empresas frequentemente escolhem modelos populares de detecção YOLO, porém a velocidade anunciada desses chips diz pouco sobre o desempenho real em campo. Este artigo faz uma avaliação experimental rigorosa de como nove variantes modernas do YOLO se comportam em três processadores Rockchip de baixo custo amplamente usados, revelando o que realmente controla velocidade, consumo de energia e confiabilidade quando a inteligência é levada para a borda.
Três chips do dia a dia no microscópio
Os autores concentram-se em três system-on-chips (SoCs) comerciais que impulsionam discretamente muitos sistemas de visão embarcada: o pequeno RV1106, o intermediário RK3568 e o mais capaz RK3588. Cada um combina núcleos de processador comuns com uma unidade de processamento neural (NPU) dedicada e memória externa. Nessas plataformas, a equipe implanta nove modelos YOLO — três gerações (YOLOv5, YOLOv8, YOLO11) em três tamanhos (Nano, Small, Medium) — todos treinados no mesmo conjunto de dados de benchmark. Eles convertem cuidadosamente os modelos para um formato comum, quantizam-nos para aritmética de 8 bits, compilam com as ferramentas da Rockchip e então executam centenas de testes cronometrados para obter medições estáveis de latência, potência e energia por quadro processado.
Velocidade não é o que a folha de especificações sugere
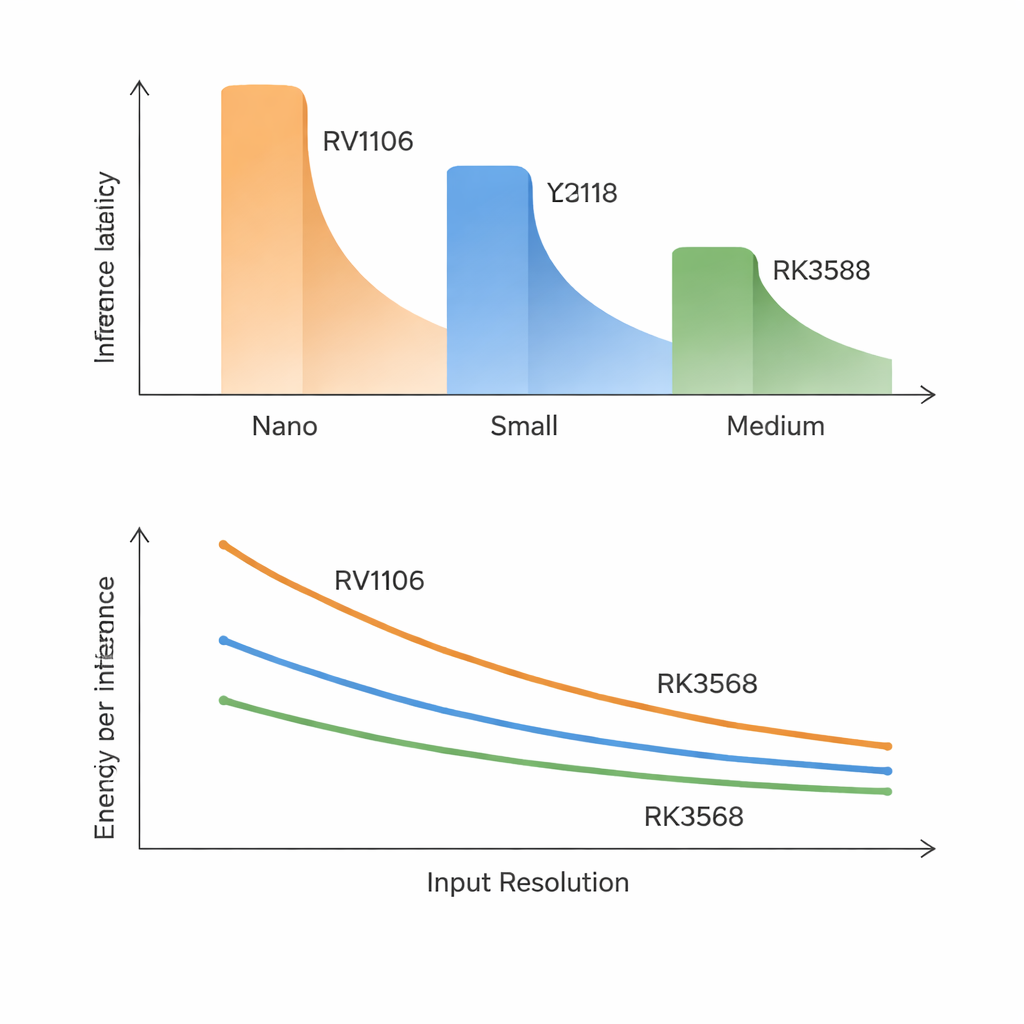
Uma das lições mais claras é que os números tradicionais de modelo e chip são fracos preditores da velocidade real. No chip mais lento, mesmo os modelos menores levam cerca de 70–100 milissegundos por quadro e os de tamanho médio são muito lentos para uso em tempo real. O chip mais rápido pode rodar modelos Nano e muitos Small perto da marca de 30 quadros por segundo, mas modelos maiores ainda ficam aquém de metas de taxa de quadros muito altas. Surpreendentemente, a latência se alinha mais com a precisão do modelo do que com o número de operações matemáticas ou parâmetros. Projetos YOLO mais novos e mais precisos adicionam blocos internos que favorecem a precisão, mas são difíceis de executar nessas NPUs, de modo que “mais inteligente” frequentemente significa “visivelmente mais lento” nesse tipo de hardware.
Quando imagens maiores e memória compartilhada cobram seu preço
O estudo mostra que aumentar o tamanho das imagens de entrada não aumenta o trabalho de forma suave. Em teoria, dobrar largura e altura deveria quadruplicar o custo, mas em chips com baixa largura de banda isso pode crescer ainda mais rápido. À medida que as imagens aumentam, os dados intermediários deixam de caber confortavelmente e precisam ser transferidos repetidamente para a memória externa. Nos SoCs menores e intermediários, isso se transforma em um engarrafamento: modelos médios desaceleram muito mais do que o esperado, e o uso intenso de memória por outras tarefas pode inflar as latências em 50–270%. Em contraste, o RK3588, com largura de banda de memória muito maior, lida graciosamente com aumentos de resolução e quase não se abala sob carga extra de CPU ou memória, destacando que a velocidade da memória — e não o poder de cálculo bruto — é frequentemente o verdadeiro gargalo.
Mais núcleos e mais potência não garantem eficiência
O chip mais rápido da Rockchip inclui uma NPU de três núcleos, mas executar o YOLO em múltiplos núcleos traz apenas benefícios modestos. Para a maioria dos modelos, dividir o trabalho em dois ou três núcleos reduz a latência em menos de 10%, e às vezes o desempenho até piora. A sobrecarga de coordenar os núcleos e compartilhar o mesmo pool de memória cancela grande parte do ganho teórico. As medições de potência adicionam outra nuance: os três SoCs consomem apenas alguns watts durante a execução, mas sua energia por quadro processado pode diferir por um fator de três. O RK3588 de maior desempenho usa mais potência instantaneamente, mas termina o trabalho tão rapidamente que frequentemente acaba sendo a escolha mais eficiente em termos de energia, especialmente para modelos de tamanho médio e resoluções maiores.
Conclusões práticas para dispositivos do mundo real
Para leitores pensando em câmeras inteligentes, robôs ou dispositivos IoT, a mensagem é direta. Nos chips menores, apenas os modelos YOLO mais minúsculos em tamanhos de imagem moderados são práticos, e mesmo assim vídeo em tempo real é algo difícil de alcançar. Chips intermediários podem suportar confortavelmente modelos Small e ocasionalmente Medium se as taxas de quadro ou a vida útil da bateria puderem ser relaxadas. O RK3588 de alta gama finalmente torna realista rodar variantes YOLO mais precisas e de tamanho médio mantendo a energia por quadro sob controle. Em todo o espectro, o artigo argumenta que projetistas devem escolher modelos com o hardware em mente, prestar muita atenção à largura de banda de memória e favorecer truques que economizam memória em vez de perseguir redes cada vez maiores. O que importa, no fim das contas, não é o número de tera-operações por segundo anunciado, mas se o sistema inteiro pode entregar detecção de objetos rápida, estável e econômica em energia nas condições desordenadas do mundo real.
Citação: Kong, C., Li, F., Yan, X. et al. Object detection on low-compute edge SoCs: a reproducible benchmark and deployment guidelines. Sci Rep 16, 5875 (2026). https://doi.org/10.1038/s41598-026-36862-y
Palavras-chave: IA de borda, detecção de objetos, visão embarcada, modelos YOLO, SoC de baixo consumo