Clear Sky Science · pt
Estimativa de variância baseada em aprendizado de máquina sob amostragem em duas fases usando dados dos setores de saúde e educação
Por que médias mais inteligentes importam para decisões do mundo real
Quando médicos estudam pressão arterial ou educadores acompanham notas de alunos, eles não se importam apenas com a média; precisam saber o quanto as pessoas se diferenciam em torno dessa média. Essa dispersão, chamada variabilidade, orienta quantos pacientes recrutar para um ensaio, qual o tamanho adequado de um programa de tutoria ou quão confiáveis são as decisões de política pública. O artigo por trás deste resumo apresenta uma nova maneira estatisticamente fundamentada de medir essa variabilidade com mais precisão, combinando ideias clássicas de amostragem com aprendizado de máquina moderno, testada em dados de saúde e educação.
Medindo a dispersão quando a informação é incompleta
No mundo ideal, pesquisadores conheceriam detalhes extras sobre cada pessoa de uma população antes de realizar uma pesquisa: idades, hábitos de estudo, histórico médico e mais. Na realidade, essa informação costuma ser incompleta ou cara de coletar. Os autores trabalham dentro de um desenho chamado amostragem em duas fases para lidar com isso. Na primeira fase, tomam uma amostra grande e relativamente barata e registram informações básicas, como idade ou se alguém tem acesso à internet. Na segunda fase, extraem um subamostra menor e medem um desfecho mais custoso ou demorado, como pressão arterial sistólica ou nota final. O desafio é usar essas duas camadas de informação para estimar quão variável o desfecho é em toda a população.
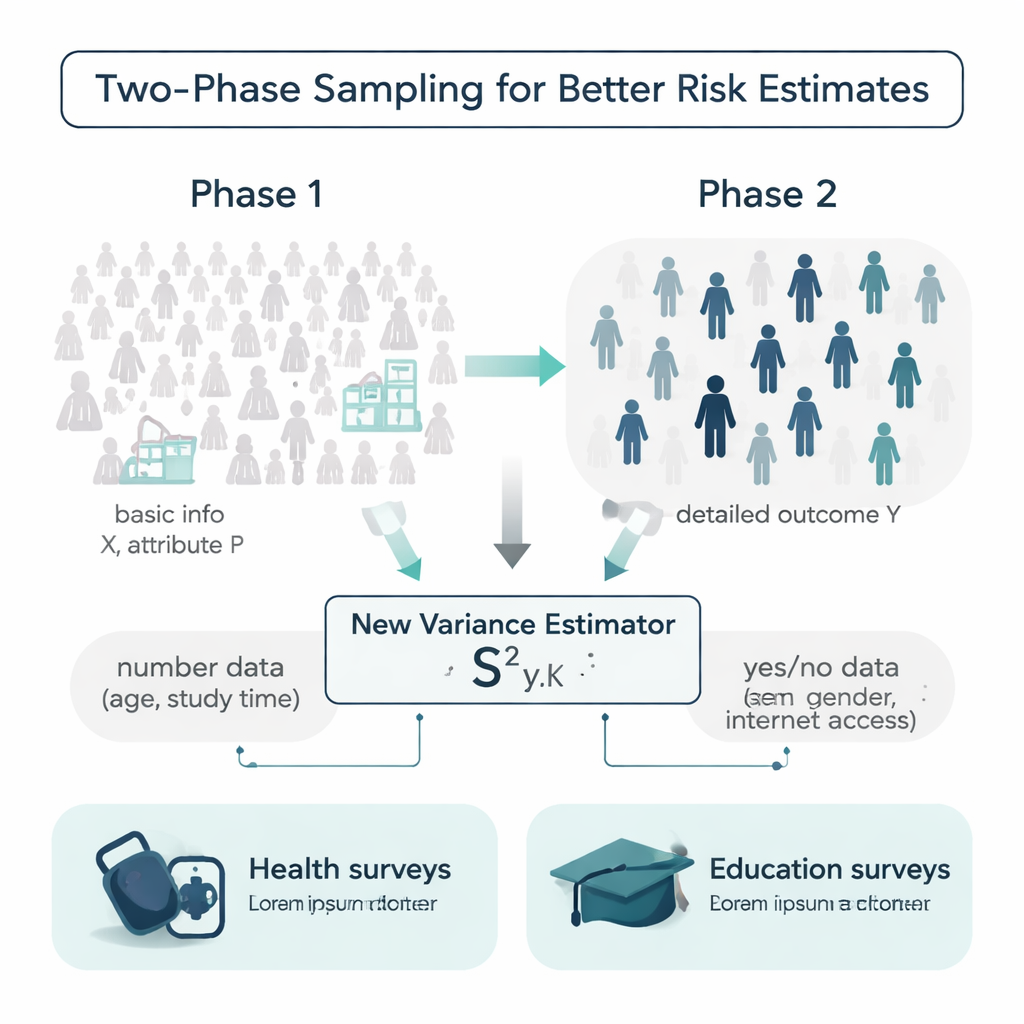
Um novo estimador que usa tanto números quanto características sim/não
A maioria das ferramentas tradicionais para medir variabilidade baseia-se apenas no próprio desfecho ou em uma única variável auxiliar, e muitas vezes assume que os dados seguem padrões em forma de sino convenientes. Os autores propõem um novo estimador de variância que usa dois tipos de informação extra ao mesmo tempo: um auxiliar numérico (por exemplo, idade ou horas de estudo semanais) e um atributo binário (como gênero ou acesso à internet). Eles mostram matematicamente como esse estimador “misto” combinado se comporta, derivando fórmulas para seu viés e erro quadrático médio — duas medidas-chave de acurácia. Sob condições razoáveis, o estimador é efetivamente não viesado e seu erro esperado é menor do que o de fórmulas concorrentes amplamente usadas, o que significa que deve fornecer estimativas de incerteza mais precisas com a mesma quantidade de dados.
Testando o desempenho em muitos cenários de dados
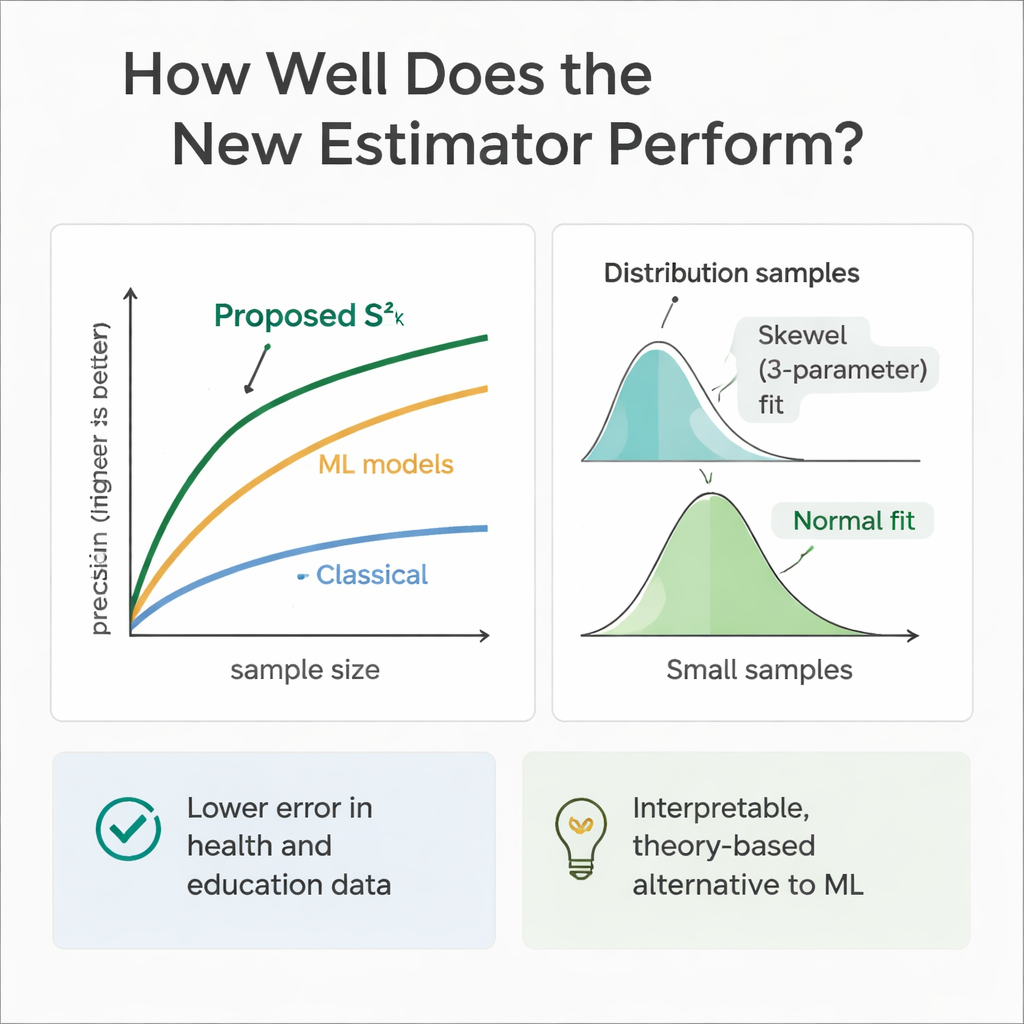
Para verificar se a teoria bate com a prática, a equipe realizou extensos experimentos computacionais. Simularam populações onde as variáveis auxiliares e o desfecho seguiam uma variedade de distribuições, desde simétricas (Normal e Uniforme) até assimétricas (Gamma e Weibull). Usando amostragem repetida, compararam o erro do novo estimador com o de vários métodos estabelecidos em múltiplos tamanhos de amostra. Em quase todos os cenários, e especialmente à medida que o tamanho amostral aumentou, a nova abordagem apresentou eficiência relativa bem maior — frequentemente reduzindo o erro em 30 a 70 por cento em comparação com o estimador clássico de variância. Os autores também examinaram como a própria distribuição amostral do estimador se comporta, constatando que uma curva Weibull de três parâmetros descreve melhor essa distribuição para amostras modestas, enquanto ela tende a uma forma Normal quando o tamanho da amostra cresce.
Dados reais de clínicas e salas de aula
O método foi então aplicado a dois estudos de caso do mundo real. Em um conjunto de dados de saúde, o desfecho foi a pressão arterial sistólica, com a idade como auxiliar numérico e o gênero como atributo binário. Em um conjunto de dados de educação, o desfecho foi a nota final do curso, o auxiliar foi o tempo de estudo semanal e o atributo foi se o aluno tinha acesso à internet. Em ambos os casos, o estimador proposto produziu o menor erro quadrático médio entre todos os competidores estatísticos testados, reduzindo substancialmente a variabilidade estimada em torno da pressão arterial média e do desempenho médio dos estudantes. Essa melhora se traduz em intervalos de confiança mais precisos e em comparações entre grupos ou intervenções mais confiáveis.
Como isso se compara ao aprendizado de máquina
Como modelos de aprendizado de máquina se destacam em predição, os autores também treinaram árvores de regressão, florestas aleatórias e regressão por vetores de suporte nos mesmos cenários simulados de saúde e educação. Esses modelos, alimentados com as mesmas variáveis auxiliares, frequentemente igualaram ou superaram ligeiramente o novo estimador em acurácia preditiva pura. Contudo, comportam-se como caixas-pretas: é difícil rastrear exatamente como combinam as informações, e eles carecem das fórmulas limpas necessárias para a inferência tradicional por inquérito. O estimador proposto, em contraste, é transparente e enraizado na teoria de amostragem, tornando-o mais fácil de justificar em contextos regulatórios, clínicos ou de políticas públicas, onde explicabilidade importa tanto quanto desempenho bruto.
O que isso significa para pesquisas na prática
Em termos simples, este trabalho mostra que pesquisadores podem obter medidas de dispersão mais confiáveis sem aumentar dramaticamente o tamanho das amostras, simplesmente fazendo uso disciplinado de informações adicionais mínimas que já coletam. Ao combinar um fator numérico (como idade ou tempo de estudo) com uma característica binária simples (como gênero ou acesso à internet) em um plano de amostragem em duas etapas, o novo estimador fornece estimativas de variância mais nítidas e estáveis do que métodos consagrados. Embora ferramentas avançadas de aprendizado de máquina continuem sendo referências úteis, esta abordagem oferece um meio-termo prático e interpretável, ajudando analistas de saúde e educação a tirar conclusões mais sólidas a partir de dados limitados.
Citação: Al-Marzouki, S., Nafisah, I.A., Dalam, M.E.E. et al. Machine learning based variance estimation under two phase sampling using health and education sector data. Sci Rep 16, 7760 (2026). https://doi.org/10.1038/s41598-026-36844-0
Palavras-chave: amostragem por inquérito, estimação de variância, aprendizado de máquina, dados de saúde, pesquisa em educação