Clear Sky Science · pt
Diagnóstico e classificação da doença hepática esteatótica por meio de dados clínicos e laboratoriais usando aprendizado de máquina
Por que a doença hepática gordurosa importa para pessoas comuns
A doença hepática gordurosa tornou-se silenciosamente um dos problemas crônicos do fígado mais comuns no mundo, afetando aproximadamente um terço dos adultos e até muitas pessoas que se sentem perfeitamente saudáveis. Se gordura demais se acumula no fígado e não é detectada precocemente, pode progredir lentamente para fibrose, insuficiência hepática e até câncer de fígado. Ainda assim, os melhores exames que temos hoje são ou invasivos, como a biópsia com agulha, ou dependem de aparelhos caros que muitas clínicas não possuem. Este estudo investiga se exames de sangue simples e rotineiros e medidas corporais, combinados com técnicas computacionais modernas, podem oferecer uma maneira mais fácil de identificar quem tem doença hepática gordurosa e quão avançada ela está.
Uma doença silenciosa que pode tornar-se séria
A doença hepática esteatótica, frequentemente chamada de fígado gorduroso, começa quando a gordura se acumula dentro das células do fígado. A princípio, esse acúmulo (esteatose simples) pode não causar sintomas e costuma ser descoberto por acaso. Com o tempo, entretanto, a gordura pode desencadear inflamação e dano no fígado, levando à formação de cicatrizes (fibrose), endurecimento do tecido e, nos piores casos, cirrose e insuficiência hepática. Como os estágios iniciais são silenciosos, mas reversíveis, detectar a doença antes que ocorram cicatrizes graves é crucial. O problema é que muitas ferramentas amplamente usadas para avaliar o dano hepático — como máquinas de ultrassom especializadas e sistemas de pontuação baseados em sangue — são ou muito caras, ou não estão amplamente disponíveis, ou são menos confiáveis em pessoas com obesidade, que estão entre as de maior risco.
Transformando exames de rotina em um teste de saúde do fígado
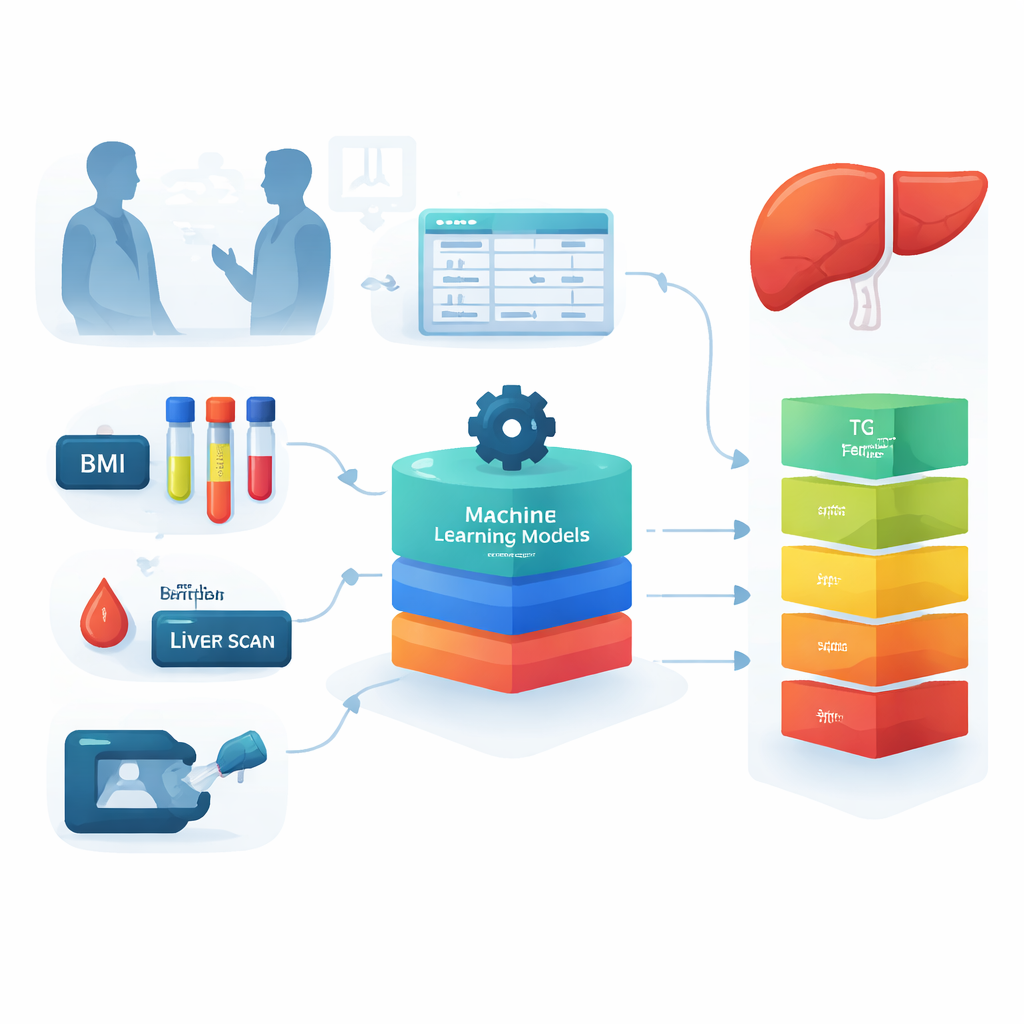
Os pesquisadores perguntaram se informações clínicas cotidianas poderiam ser transformadas em uma ferramenta de triagem poderosa. Eles utilizaram prontuários de 210 adultos que visitaram uma clínica de doenças digestivas em Teerã, Irã. Para cada pessoa, coletaram medidas básicas, como altura e peso, e exames de sangue padrão, como colesterol, triglicerídeos, glicemia de jejum, enzimas hepáticas e marcadores relacionados ao ferro. A gravidade do acúmulo de gordura e das cicatrizes no fígado já havia sido medida com um dispositivo especializado chamado FibroScan, que permitiu à equipe classificar os participantes em cinco grupos: de fígados saudáveis, passando por acúmulos leves, moderados e graves de gordura, até aqueles com fibrose avançada. Esses grupos serviram como a “verdade de referência” para treinar e testar os modelos computacionais.
Ampliando os dados e treinando as máquinas
Como 210 pacientes é um número relativamente pequeno para aprendizado de máquina, a equipe criou registros adicionais de pacientes “sintéticos” ao adicionar variação aleatória cuidadosamente controlada aos dados reais. Eles verificaram se esses registros simulados ainda seguiam os mesmos padrões gerais do conjunto original e expandiram o conjunto de dados para 1.500 amostras. Em seguida, testaram oito abordagens diferentes de aprendizado de máquina, incluindo árvores de decisão, florestas aleatórias, máquinas de vetor de suporte e redes neurais, além de combinações desses métodos. Cada modelo foi solicitado a prever a qual dos cinco grupos de saúde do fígado uma pessoa pertencia, com base apenas nos dados clínicos e laboratoriais. O desempenho foi avaliado não apenas pela precisão geral, mas também por quão raramente o modelo rotulava erroneamente uma pessoa doente como saudável — uma preocupação crítica para qualquer ferramenta de triagem.
Encontrando os poucos números que mais importam
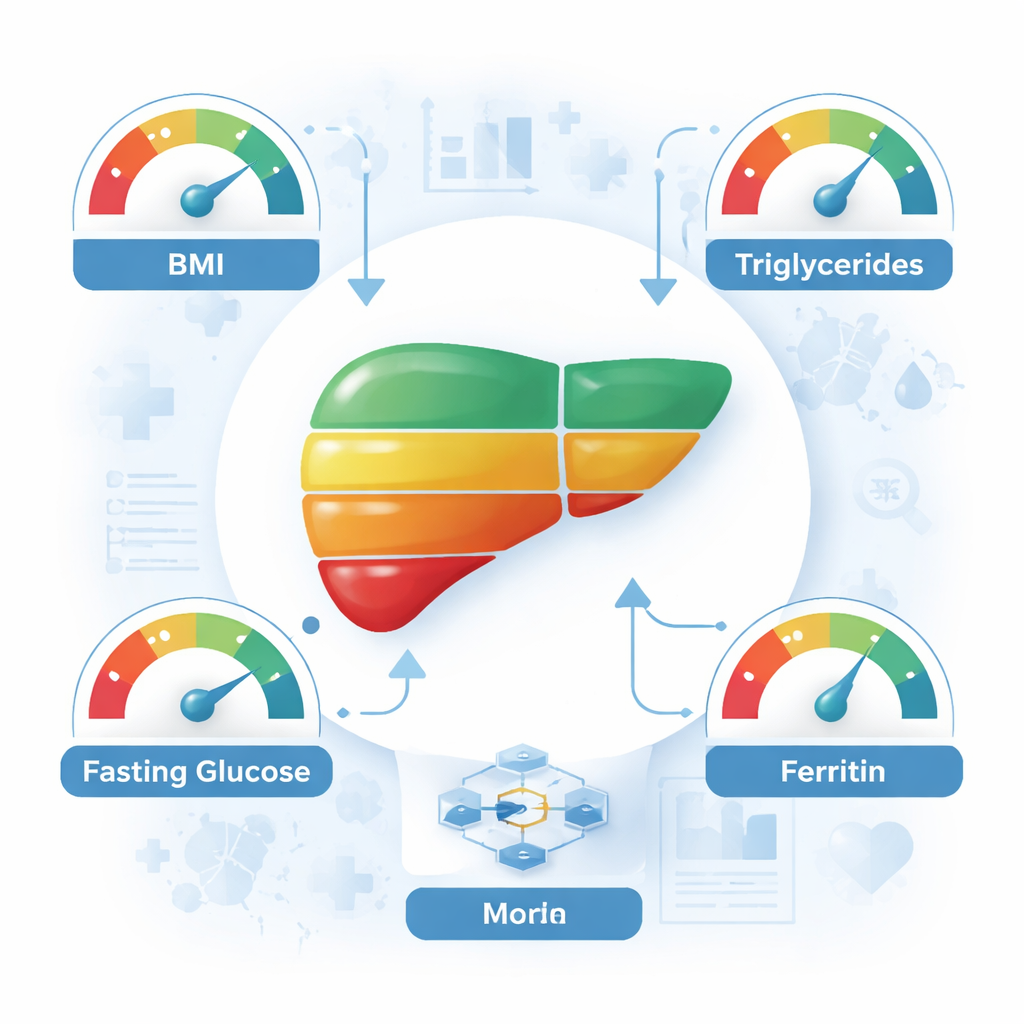
Alguns dos modelos, especialmente um híbrido que combinou máquinas de vetor de suporte com um método de boosting (SVM–XGBoost), alcançaram cerca de 93% de precisão ao usar as 26 características disponíveis. Para tornar a ferramenta mais simples e fácil de usar, os pesquisadores examinaram em seguida quais medidas mais contribuíam para as previsões. Técnicas estatísticas destacaram primeiro oito características particularmente importantes, incluindo índice de massa corporal (IMC), triglicerídeos, glicemia de jejum, ferritina (uma proteína de armazenamento de ferro), plaquetas, fosfatase alcalina, creatinina e uma medida de coagulação sanguínea. Especialistas em fígado então revisaram esses resultados e selecionaram quatro medidas que eram ao mesmo tempo fortemente relacionadas à biologia da doença e práticas no cuidado cotidiano: IMC, triglicerídeos, glicemia de jejum e ferritina. Notavelmente, quando os modelos foram re-treinados usando apenas essas quatro entradas, ainda classificaram corretamente os pacientes em cerca de 70% das vezes, e até 76% com o melhor método.
O que isso significa para pacientes e clínicas
Para o leigo, a principal mensagem é que um punhado de números rotineiros de um check-up padrão — peso e altura para calcular o IMC, juntamente com exames de sangue simples para gorduras, açúcar e estoques de ferro — pode oferecer uma imagem surpreendentemente detalhada da saúde do fígado quando interpretados por modelos computacionais bem projetados. Embora essas ferramentas não substituam o julgamento médico especializado ou exames de imagem especializados quando disponíveis, elas oferecem uma maneira promissora de identificar pessoas em risco, especialmente em clínicas com recursos limitados e em regiões onde a doença hepática gordurosa é comum. A detecção mais precoce pode motivar mudanças no estilo de vida, como perda de peso, alimentação mais saudável e aumento da atividade física, medidas conhecidas por melhorar a saúde do fígado. Este estudo sugere que, em um futuro próximo, seus resultados de laboratório rotineiros podem funcionar também como um sistema de alerta precoce para uma doença silenciosa, mas séria.
Citação: Sadeghi, B., Zarrinbal, M., Poustchi, H. et al. Diagnosis and grading of steatotic liver disease via clinical and laboratory data using machine learning. Sci Rep 16, 6866 (2026). https://doi.org/10.1038/s41598-026-36834-2
Palavras-chave: doença hepática gordurosa, aprendizado de máquina, exames de sangue, IMC e triglicerídeos, diagnóstico não invasivo