Clear Sky Science · pt
Generalizabilidade e transferibilidade de modelos de aprendizado de máquina usando dados de reflectância hiperespectral para características do milho
Por que escanear folhas de plantas importa para nosso futuro alimentar
Alimentar uma população em crescimento sob um clima em mudança exige culturas capazes de prosperar em calor, seca e outros estresses. Melhoristas querem saber quais plantas têm a combinação certa de estrutura foliar, química e desempenho fotossintético — mas medir diretamente essas características em milhares de plantas é lento e destrutivo. Este estudo investiga se simplesmente escanear folhas de milho com um sensor hiperespectral e usar aprendizado de máquina pode substituir de forma confiável as medições laboratoriais trabalhosas, mesmo quando as plantas são cultivadas em anos diferentes e sob condições de campo variáveis.
Impressões digitais de luz das folhas do milho
Cada folha reflete a luz em um padrão que depende de seus pigmentos, teor hídrico e estrutura interna. Sensores hiperespectrais capturam esse padrão ao longo de centenas de comprimentos de onda do visível ao infravermelho de ondas curtas, criando uma “impressão digital” detalhada de cada folha. Os pesquisadores coletaram essas impressões de uma população diversa de milho cultivada em três safras de campo consecutivas, junto com 25 características que descrevem a anatomia da folha (como área foliar específica e balanço carbono–nitrogênio), trocas gasosas (como as folhas absorvem CO2 e perdem água) e fluorescência da clorofila (uma janela para a eficiência e regulação da fotossíntese). Esse conjunto de dados rico permitiu testar o quão bem diferentes modelos estatísticos podiam transformar espectros de luz em estimativas de características.
Ensinando máquinas a ler folhas
A equipe focou em duas abordagens de aprendizado de máquina amplamente usadas e relativamente simples: regressão por mínimos quadrados parciais (PLSR) e regressão por vetor de suporte linear (SVR linear). Ambos os métodos comprimem os espectros altamente detalhados em um conjunto menor de características informativas antes de vinculá-las às características medidas. Os cientistas compararam cuidadosamente maneiras de ajustar os modelos, especialmente quantos componentes o PLSR deveria usar, e como evitar overfitting. Também examinaram se é melhor alimentar os modelos com medições de folhas individuais, médias de um único talhão ou médias de todas as plantas do mesmo genótipo. Um rigoroso esquema de validação cruzada aninhada — essencialmente ciclos repetidos de treino–teste — foi usado para verificar desempenho e incerteza.
Quais características são mais fáceis de prever
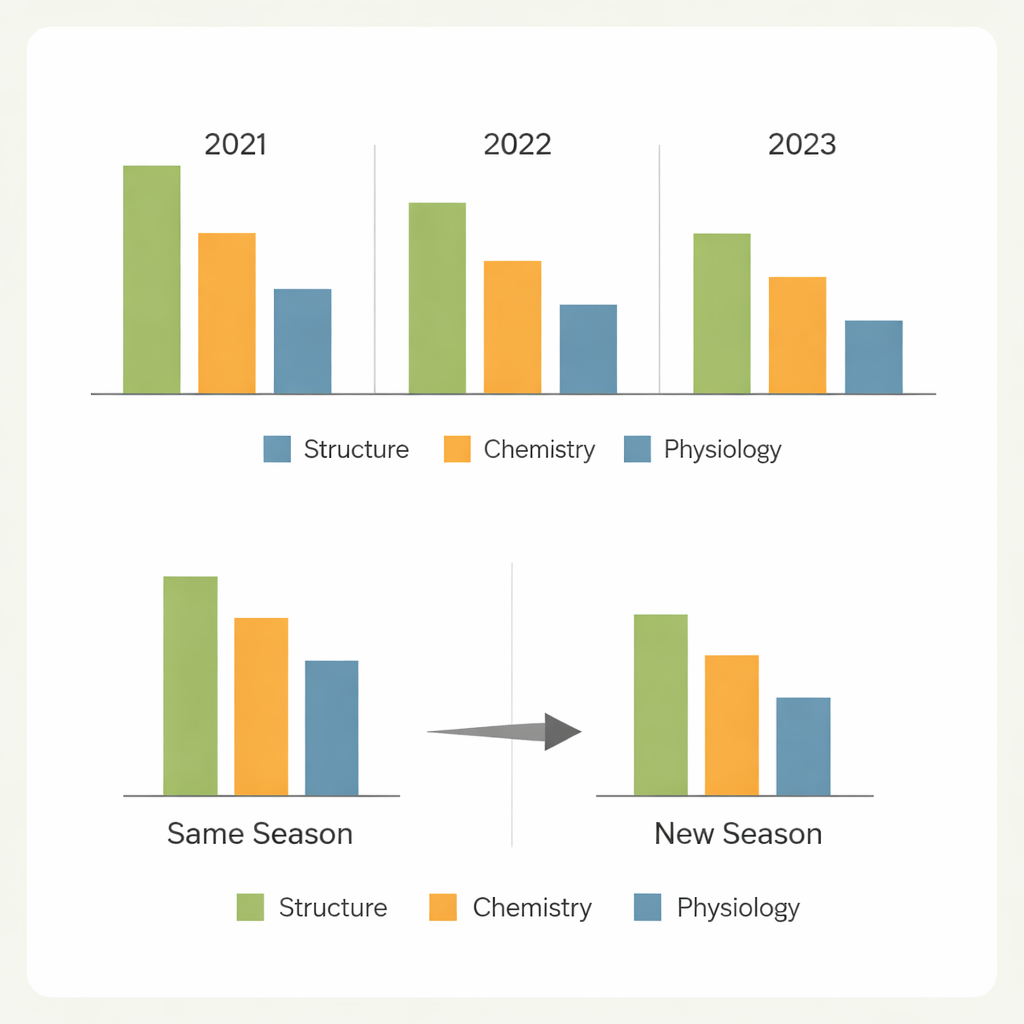
De uma safra para a outra
Uma questão central para o melhoramento no mundo real é se um modelo treinado em um conjunto de condições pode ser confiável em outro. Quando os modelos previram plantas aleatórias dentro da mesma safra, o desempenho foi geralmente forte para as características mais fáceis. Prever genótipos inteiramente novos cultivados na mesma safra levou a quedas apenas moderadas para características estruturais e relacionadas ao nitrogênio, mas declínios muito mais acentuados para traços de trocas gasosas. O teste mais severo — prever novos genótipos em um ano diferente — revelou grandes perdas de precisão, particularmente para características fortemente moldadas pelo ambiente. Diferenças no clima, nas condições do campo e na composição dos genótipos alteraram os padrões espectrais o suficiente para limitar a transferibilidade, com uma das safras destacando-se como especialmente difícil de prever a partir das outras.
O que isso significa para melhoramento e sensoriamento remoto
Para melhoristas e cientistas de culturas, o estudo oferece tanto encorajamento quanto cautela. A varredura hiperespectral combinada com aprendizado de máquina relativamente simples já é uma ferramenta poderosa para estimativa de alta produtividade de características estáveis e integrativas, como estrutura foliar e status de nitrogênio, e pode generalizar razoavelmente bem entre genótipos e anos para esses alvos. Contudo, a mesma abordagem é bem menos confiável para traços fisiológicos rápidos e sensíveis ao ambiente quando os modelos são aplicados além das condições em que foram treinados. Os autores concluem que os métodos hiperespectrais estão prontos para apoiar a triagem em grande escala de algumas características-chave do milho, mas que prever comportamento fisiológico dinâmico através de ambientes exigirá dados de treinamento mais ricos, modelagem mais avançada e talvez tipos adicionais de medições.
Citação: Xu, R., Ferguson, J., Breil-Aubert, M. et al. Generalizability and transferability of machine learning models using hyperspectral reflectance data for maize traits. Sci Rep 16, 5865 (2026). https://doi.org/10.1038/s41598-026-36819-1
Palavras-chave: reflectância hiperespectral, milho, aprendizado de máquina, fenotipagem de plantas, fotossíntese