Clear Sky Science · pt
Modelagem taxonômica e classificação em relatórios de falhas de hardware espacial
Encontrando Padrões em Falhas de Voo Espacial
Cada missão ao espaço depende de incontáveis peças de hardware funcionando sem falhas, desde parafusos e cabos até sistemas de suporte à vida. Quando algo dá errado, os engenheiros registram relatórios detalhados de discrepância, mas a NASA agora tem mais de 54.000 desses registros—muito mais do que pessoas conseguiriam ler uma a uma. Este estudo mostra como ferramentas modernas de linguagem e aprendizado de máquina podem transformar essa montanha de texto em conhecimento organizado, ajudando engenheiros a identificar padrões de falhas, melhorar projetos e manter astronautas mais seguros.
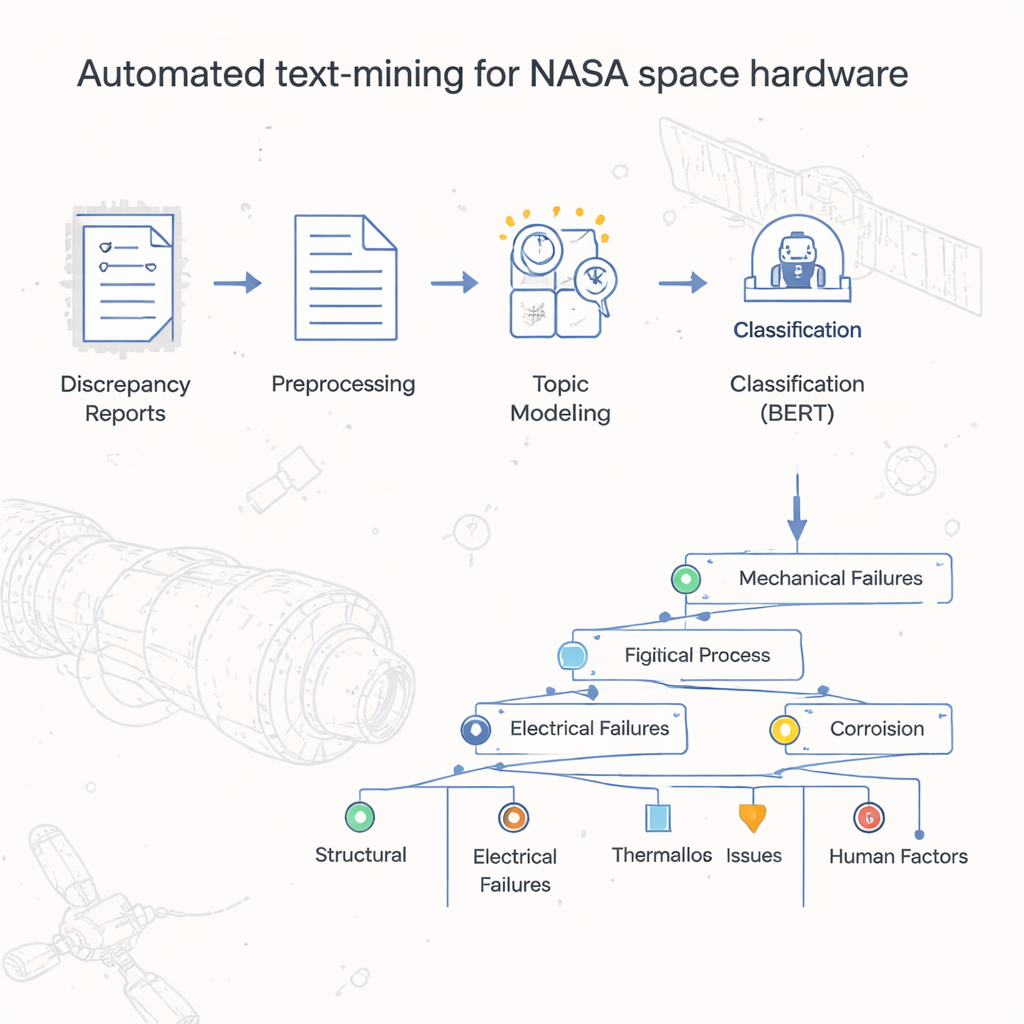
De Pilhas de Relatórios a Insights Organizados
Por décadas, o Johnson Space Center da NASA armazenou relatórios de falhas de hardware e discrepâncias como documentos digitais, muito parecidos com versões digitalizadas de formulários em papel. Contagens básicas em planilhas mostravam quais códigos oficiais de defeito apareciam com mais frequência, mas a história real—as causas específicas, os passos e as condições que levaram aos problemas—estava enterrada em campos de texto livre. Ler e categorizar mais de 54.000 registros manualmente seria proibitivamente demorado. Os autores propuseram construir um método automatizado para classificar e agrupar esses relatórios, criando uma espécie de “mapa” ou taxonomia que captura como o hardware espacial realmente falha na prática cotidiana.
Ensinando Computadores a Ler Linguagem de Engenharia
A equipe primeiro limpou o texto de cada relatório para que os computadores pudessem processá‑lo de forma eficaz. Eles removeram símbolos e dígitos dispersos que adicionavam ruído, dividiram sentenças em palavras individuais e as converteram para uma forma básica mais simples (por exemplo, transformando “vazou” e “vazando” em “vazamento”). Palavras comuns que têm pouco significado, como “o” ou “e”, foram filtradas. Com o texto padronizado, os pesquisadores o converteram em números que algoritmos de aprendizado de máquina conseguem manipular, usando técnicas consolidadas que capturam com que frequência palavras aparecem e o quanto elas caracterizam um documento. Essa base permitiu aplicar ferramentas poderosas originalmente desenvolvidas para tarefas gerais de linguagem ao mundo altamente especializado dos relatórios de hardware espacial.
Construindo uma Árvore de Tipos de Falha
No cerne do projeto está um modelo em duas etapas que os autores chamam de LDA-BERT. A primeira etapa, Latent Dirichlet Allocation (LDA), descobre automaticamente temas—chamados tópicos—buscando padrões de palavras que tendem a aparecer juntas em milhares de relatórios. Um único relatório pode misturar vários tópicos, espelhando a vida real onde um problema de hardware pode ter múltiplas causas contribuintes. A segunda etapa usa o BERT, um modelo de linguagem moderno, para verificar e refinar o quão bem esses tópicos separam os relatórios. Ao tratar os tópicos da LDA como rótulos provisórios e treinar o BERT para prevê‑los, os pesquisadores puderam identificar o número e a combinação de tópicos que proporcionavam classificações estáveis e precisas. Em seguida, dividiram cada tópico em subtópicos, usando clustering e verificações estatísticas, para construir uma taxonomia ramificada que organiza os relatórios de falha desde códigos de defeito amplos até rótulos detalhados em nível de processo.
Transformando Taxonomias em Tendências Acionáveis
Com a taxonomia em funcionamento, a equipe a visualizou por meio de painéis e ferramentas interativas. Cada ramo e sub‑ramo da árvore pôde ser vinculado a outras informações dos relatórios: quando um problema foi observado pela primeira vez, quanto tempo levou para ser encerrado, qual organização era responsável e qual decisão final foi tomada. Gráficos de séries temporais mostraram se certos tipos de problemas—como falhas de inspeção ou questões de dados de tolerância—estavam se tornando mais ou menos comuns ao longo dos anos. Mapas de palavras forneceram uma sensação rápida da linguagem usada em cada cluster sem precisar ler todo relatório. Essas visualizações ajudam gestores a focar em falhas de processo com alta tendência e alto impacto, orientando treinamentos, mudanças de procedimento ou atualizações de projeto onde terão maior efeito.
Limites da Busca Automática por Causas Raiz
Os pesquisadores também exploraram ferramentas que tentam ir além da rotulação e identificação de tendências para inferir relações diretas de causa e efeito a partir do texto. Eles testaram sistemas como INDRA‑Eidos e conjuntos de regras personalizados construídos com a biblioteca spaCy. Embora essas ferramentas pudessem extrair alguns pares de causa e efeito e visualizá‑los como redes interativas, muitos dos links sugeridos eram vagos ou confusos demais para serem úteis. Na prática, os modelos tiveram dificuldade porque os relatórios originais frequentemente não explicitavam causas raiz com clareza; os engenheiros as insinuavam ou as deixavam para investigações posteriores. O estudo conclui que automatizar de forma confiável a descoberta de causa raiz exigiria tanto uma entrada de dados mais rica—como campos explícitos para causas prováveis—quanto um treinamento de modelo mais caro e altamente personalizado, o que não é justificável para esta análise pontual.
Por Que Isso Importa para Missões Futuras
Ao transformar um grande arquivo não estruturado de relatórios de falha em uma taxonomia clara e em camadas, este trabalho oferece à NASA uma maneira prática de monitorar como e por que problemas de hardware surgem ao longo do tempo. Embora os métodos ainda não possam substituir o julgamento humano para análise profunda de causa raiz, eles se destacam em vasculhar vastas quantidades de texto para destacar onde os problemas se concentram e que tipos de processos tendem a estar envolvidos. Esse tipo de aviso antecipado e insight estruturado pode ajudar equipes de engenharia a direcionar sua atenção, refinar procedimentos e projetar sistemas mais robustos—passos concretos em direção a missões mais seguras e confiáveis para a Lua, Marte e além.
Citação: Palacios, D., Hill, T.R. Taxonomical modeling and classification in space hardware failure reporting. Sci Rep 16, 5868 (2026). https://doi.org/10.1038/s41598-026-36813-7
Palavras-chave: falhas de hardware espacial, processamento de linguagem natural, modelagem de tópicos, análise de risco em engenharia, relatórios de discrepância da NASA