Clear Sky Science · pt
Verificando a autenticidade de notícias em Urdu usando deep learning com incorporação concatenada BERT e GloVe
Por que identificar notícias falsas em Urdu é importante
No Paquistão e no mundo, mais pessoas hoje obtêm notícias por sites e redes sociais do que por jornais ou televisão. Essa mudança tornou mais fácil do que nunca a rápida circulação de histórias falsas, especialmente em línguas nacionais como o Urdu, onde as ferramentas digitais são limitadas. Este estudo aborda uma pergunta simples, porém urgente: a inteligência artificial moderna pode distinguir automaticamente notícias verdadeiras de falsas em Urdu, ajudando leitores comuns, jornalistas e plataformas a se defenderem contra informações enganosas?
O desafio crescente da desinformação online
Os autores começam descrevendo como manchetes fabricadas e histórias distorcidas podem moldar a opinião pública, alimentar tensões políticas e até prejudicar a saúde e as finanças das pessoas. Enquanto muitos sites de checagem de fatos e projetos de pesquisa se concentram no inglês, idiomas regionais como o Urdu frequentemente ficam de lado. Os recursos existentes em Urdu incluem apenas alguns milhares de itens de notícias, muitos traduzidos do inglês e focados em tópicos restritos, como política. Isso dificulta treinar sistemas computacionais confiáveis para reconhecer conteúdo suspeito na língua que a maioria dos paquistaneses realmente lê.
Construindo uma grande coleção de notícias em Urdu
Para reduzir essa lacuna, os pesquisadores reuniram o que descrevem como o maior conjunto de dados de notícias falsas em Urdu até hoje, contendo 14.178 artigos coletados entre 2017 e 2023 de sites de notícias paquistaneses respeitados e plataformas online. As matérias abrangem quinze áreas da vida cotidiana, incluindo política, saúde, educação, negócios, crime, esportes e meio ambiente. Usando fontes de verificação de fatos como PolitiFact, FactCheck e APIs de notícias especializadas, cada item foi rotulado como real ou falso; itens parcialmente verdadeiros foram agrupados com notícias reais para refletir uma cobertura mais nuanceada. A equipe então limpou os textos removendo duplicatas, endereços web e pontuação extra, separando sentenças em palavras e eliminando palavras de preenchimento muito comuns.
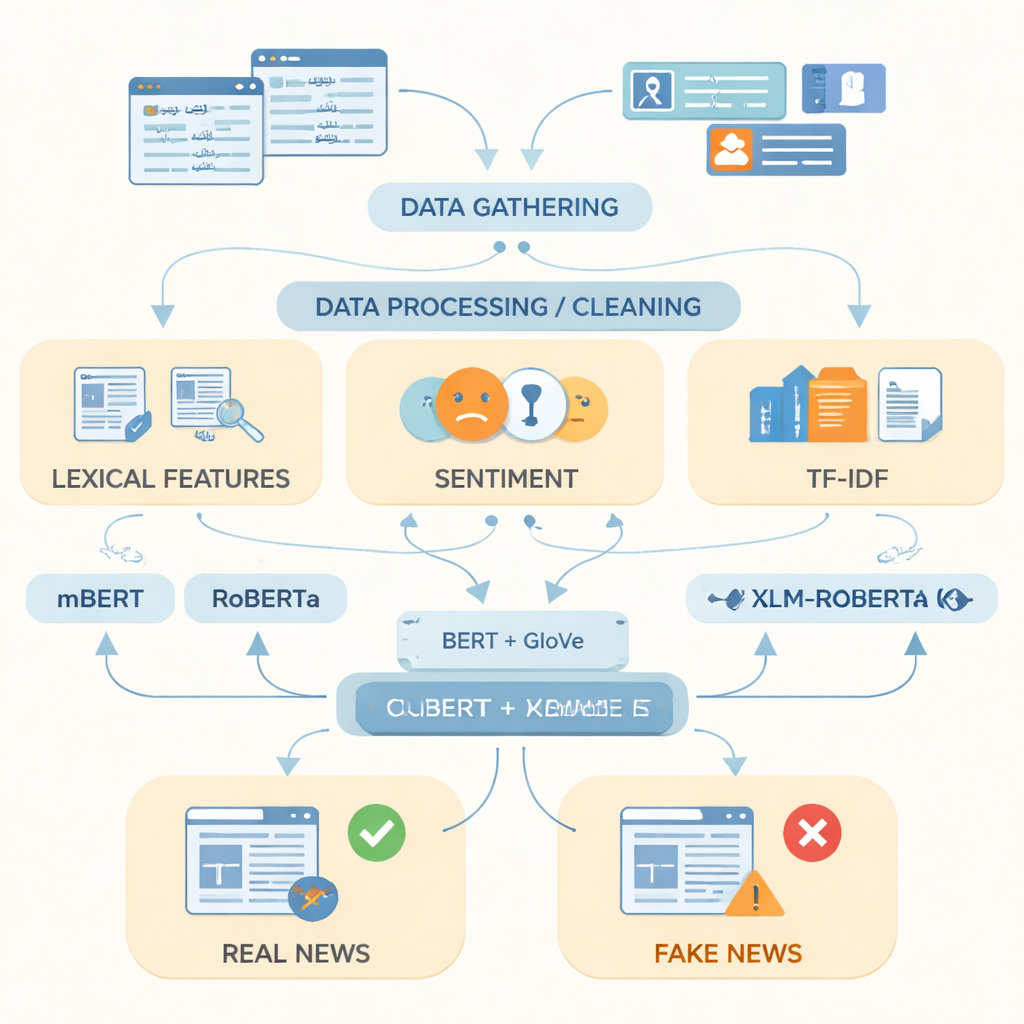
Ensinando aos computadores como é uma notícia falsa
Após preparar os dados, os autores focaram em como representar melhor o texto em Urdu para um computador. Eles combinaram indicadores simples — como palavras frequentemente usadas, o tom emocional da linguagem e pontuações de frequência de termos — com duas poderosas técnicas de representação de palavras. Uma, chamada GloVe, trata cada palavra como um vetor numérico fixo baseado em quão frequentemente aparece junto com outras palavras em toda a coleção. A outra, baseada em modelos no estilo BERT, analisa cada palavra dentro de sua frase e lhe atribui um significado sensível ao contexto. Ao unir essas duas visões da linguagem em uma única representação mais rica, o sistema consegue capturar tanto padrões gerais quanto mudanças sutis na redação que muitas vezes distinguem histórias falsas das verdadeiras.
Testando modelos avançados de linguagem
Os pesquisadores então alimentaram essas representações em três modelos modernos de deep learning treinados em textos de muitas línguas: mBERT, RoBERTa e XLM-RoBERTa. Todos os três foram ajustados (fine-tuned) no conjunto de dados em Urdu para predizer se cada artigo era real ou falso. O desempenho foi avaliado com medidas padrão: acurácia (com que frequência estavam corretos), precisão (com que frequência os falsos sinalizados eram realmente falsos), recall (quantos de todos os artigos falsos foram capturados) e a pontuação F1, que equilibra precisão e recall. Embora todos os modelos tenham apresentado desempenho forte, o XLM-RoBERTa combinado com a representação fundida de BERT e GloVe obteve o melhor resultado, classificando corretamente cerca de 96% dos artigos de teste e atingindo uma F1-score de 0,956 — superior a sistemas anteriores de detecção de notícias falsas em Urdu que usaram conjuntos de dados menores ou métodos mais simples.
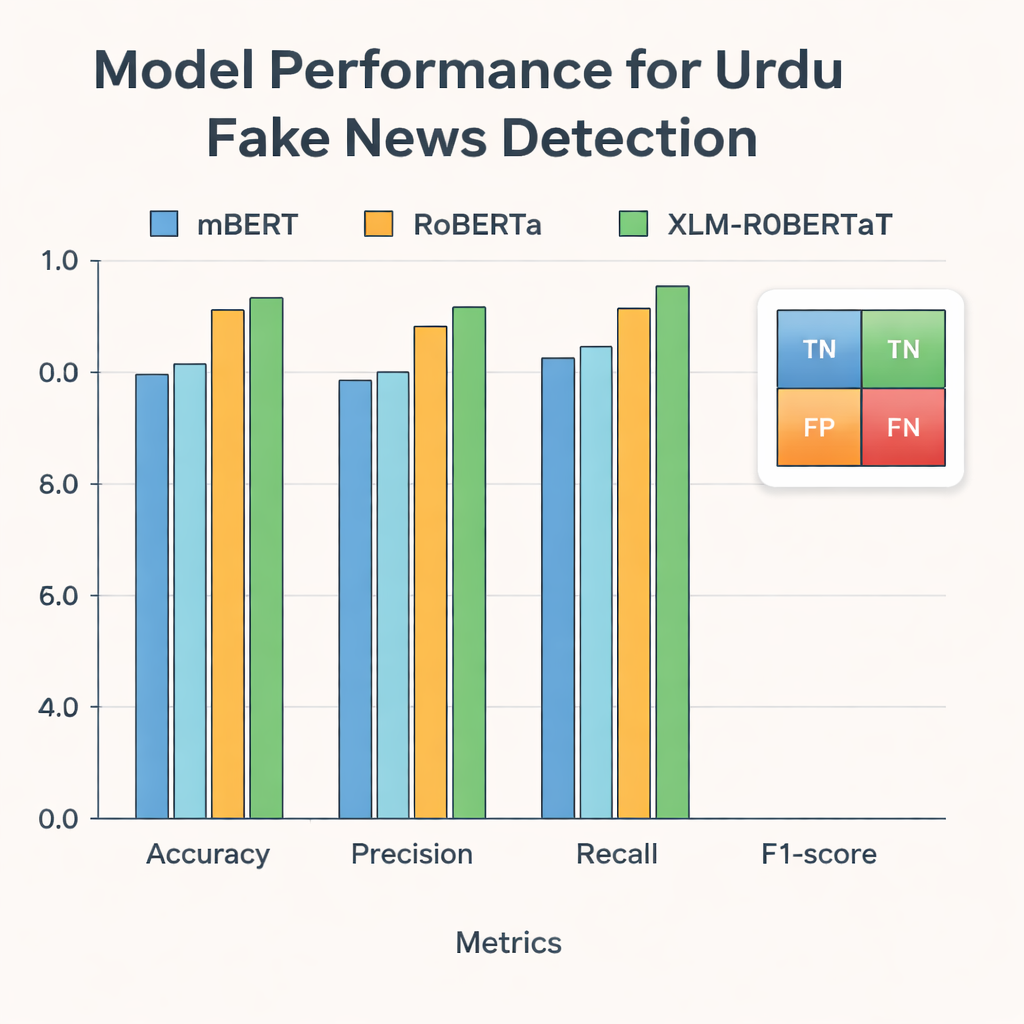
O que isso significa para leitores comuns
Para não especialistas, a mensagem é direta: com dados de notícias em Urdu em quantidade e qualidade suficientes e o tipo certo de IA, hoje é possível construir ferramentas que sinalizam automaticamente histórias provavelmente falsas com alta confiabilidade. O estudo mostra que representações linguísticas mais ricas e modelos multilíngues dão aos computadores uma compreensão muito melhor de como o Urdu é realmente escrito em diferentes regiões e tópicos. Embora o trabalho atual se concentre apenas em texto e ainda não analise imagens ou comportamento em redes sociais, ele lança uma base sólida para sistemas futuros que possam atuar entre línguas e tipos de mídia. Em termos práticos, esta pesquisa aproxima o Paquistão de recursos como extensões de navegador, painéis para redações ou filtros de redes sociais que ajudam as pessoas a separar fato de ficção na língua que usam todos os dias.
Citação: Feroz, A., Abbasi, W., Babar, M.Z. et al. Verifying Urdu news authenticity using deep learning with concatenated BERT and GloVe embedding. Sci Rep 16, 7352 (2026). https://doi.org/10.1038/s41598-026-36771-0
Palavras-chave: detecção de notícias falsas, idioma Urdu, deep learning, BERT e GloVe, desinformação online