Clear Sky Science · pt
Kernel mean matching melhora a estimativa de risco sob deslocamentos espaciais de distribuição
Por que estimar risco em mapas que mudam importa
Modelos de aprendizado de máquina são cada vez mais usados para prever onde espécies vão viver, como tumores estão organizados no tecido ou como a poluição se espalha. Ainda assim, os dados usados para treinar esses modelos frequentemente são coletados em lugares muito específicos—amostragem densa perto de cidades, hospitais ou locais de campo de fácil acesso—enquanto os modelos são aplicados em regiões muito maiores e diferentes. Essa discrepância entre onde os dados foram coletados e onde as previsões são feitas pode fazer com que os modelos pareçam mais seguros e mais precisos do que realmente são. O artigo "Kernel mean matching enhances risk estimation under spatial distribution shifts" faz uma pergunta aparentemente simples: quando o mundo difere dos seus dados de treinamento, quão errado seu modelo pode estar e como você pode detectar isso?
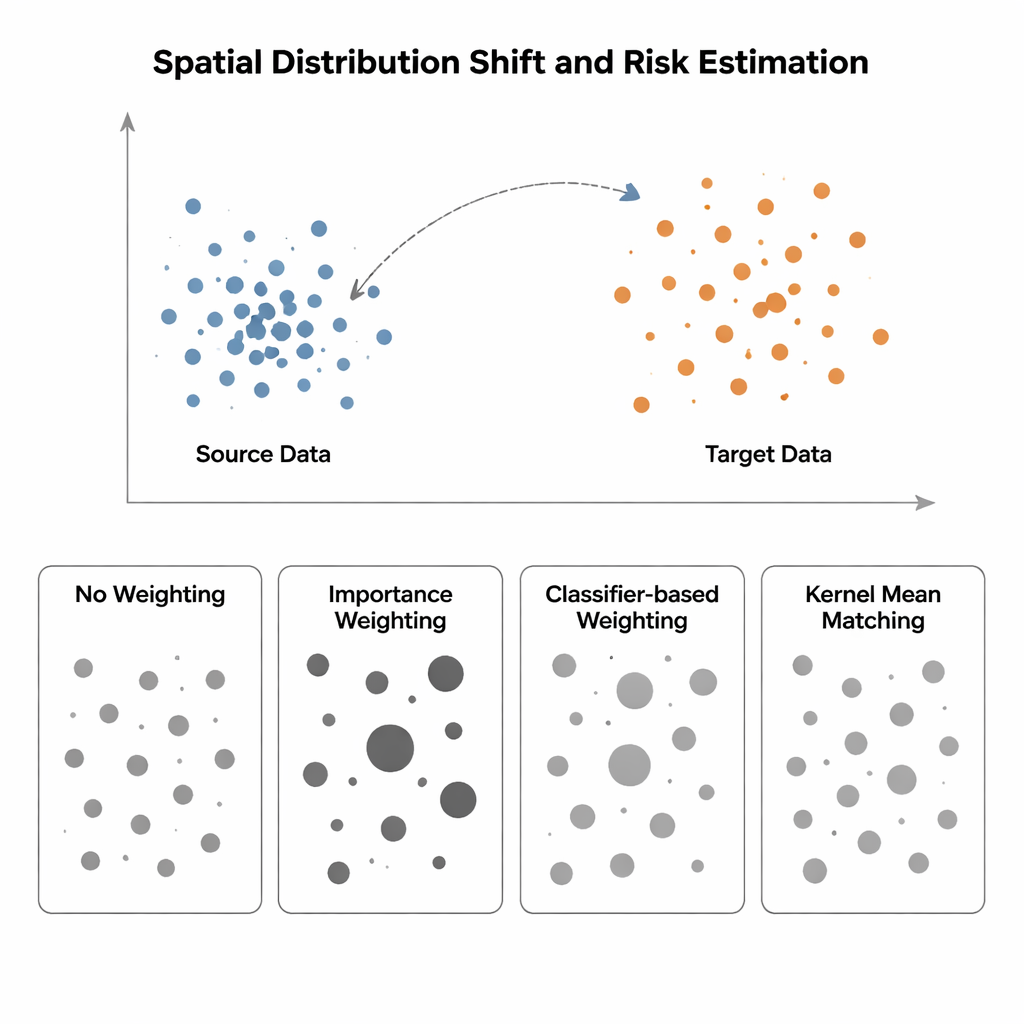
Quando treino e teste vivem em mundos diferentes
Em estatística, o "risco" de um modelo é o erro esperado em dados novos e não vistos. Truques padrão de avaliação—como validação cruzada ou reservar um conjunto de teste aleatório—supõem silenciosamente que os dados de treino e de teste vêm da mesma distribuição. Dados espaciais rompem essa suposição. Gradientes ambientais, amostragem agrupada e mudança climática significam que as condições onde treinamos um modelo podem diferir fortemente daquelas onde o implantamos. Por exemplo, observações de espécies frequentemente se concentram próximas a estradas, enquanto decisões de conservação envolvem áreas remotas; amostras de tumor podem ser coletadas de uma região de um tecido, mas previsões são necessárias em outras partes. Nesses casos, estimativas convencionais de risco tendem a ser excessivamente otimistas, escondendo o quão mal um modelo pode falhar em novas localizações.
Ferramentas antigas têm dificuldade com viés espacial
O estudo compara quatro formas de estimar o risco do modelo quando a distribuição de entrada muda de uma região "fonte" (onde os rótulos são conhecidos) para uma região "alvo" (onde os rótulos são escassos ou ausentes). O método mais simples, chamado Sem Ponderação, apenas mede o erro médio nos dados disponíveis e assume que fonte e alvo são semelhantes—uma suposição que se desfaz sob viés espacial. Pesos de Importância tenta corrigir isso escalando cada amostra da fonte de acordo com quão comum esse tipo de ponto é no alvo em relação à fonte. Na teoria isso recupera o risco correto, mas na prática exige estimar densidades de probabilidade em alta dimensão. Quando os dados de origem estão fortemente agrupados e os dados do alvo são mais dispersos—uma situação típica em ecologia espacial ou imagem médica—essas estimativas de densidade tornam-se pouco confiáveis, e algumas amostras recebem pesos enormes, tornando a estimativa de risco extremamente instável. Abordagens baseadas em classificadores, que treinam um classificador para distinguir pontos de fonte e alvo e convertem suas probabilidades em pesos, evitam a estimação explícita de densidade, mas frequentemente produzem riscos mal calibrados porque otimizam acurácia de classificação, não alinhamento das distribuições.
Uma rota diferente: combinar distribuições diretamente
Os autores defendem o Kernel Mean Matching (KMM), uma abordagem que evita a estimação de densidade por completo. Em vez de tentar calcular quão provável é cada ponto sob as distribuições de fonte e alvo, o KMM busca pesos nas amostras da fonte que façam com que sua "assinatura" média em um espaço de características flexível definido por um kernel iguale a das amostras do alvo. Intuitivamente, ele estica ou encolhe a influência de cada ponto da fonte para que, tomados em conjunto, a nuvem ponderada de fonte se pareça com a nuvem do alvo. Uma vez encontrados esses pesos, o risco é estimado como uma média ponderada dos erros da fonte. Uma ferramenta complementar, a Função de Correlação Local, quantifica o quão agrupados os dados estão no espaço; ela serve como diagnóstico para indicar quando os deslocamentos de distribuição são fortes o bastante para que reponderação seja útil.
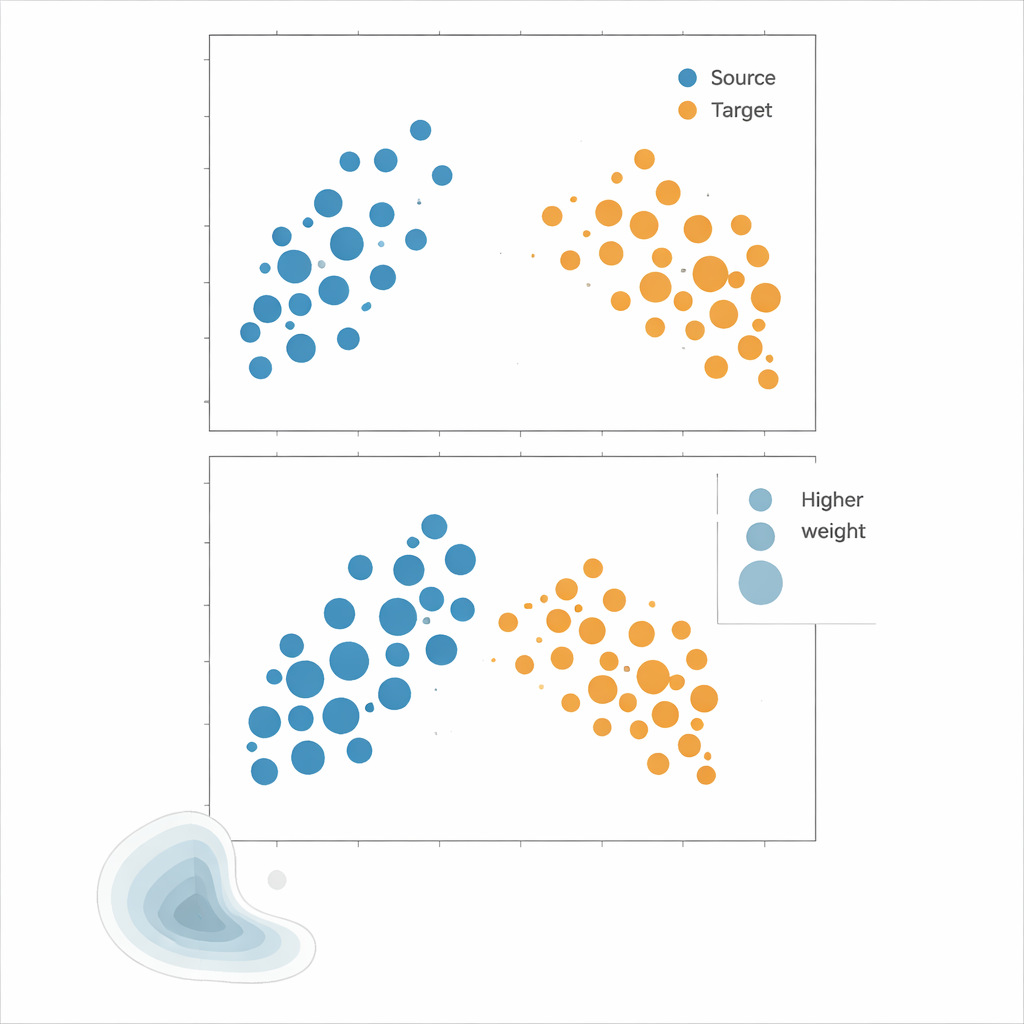
Colocando os métodos à prova
Para ver qual estratégia funciona melhor, os autores realizaram experimentos extensivos em dados sintéticos e do mundo real. "Paisagens" sintéticas são construídas a partir de misturas de aglomerados Gaussianos cuja dispersão, forma e cobertura do domínio podem ser controladas com precisão, permitindo testes estruturados como recortar parte do domínio, alterar padrões de correlação entre variáveis ou alternar entre padrões de pontos fortemente agrupados e quase uniformes. Conjuntos de dados reais incluem ocorrências de espécies de plantas nórdicas, descritas por clima e localização, e layouts espaciais de células imunes dentro de tumores. Nesses cenários, modelos são treinados em dados de fonte agrupados e avaliados em dados alvo menos agrupados, imitando vieses de amostragem comuns. O desempenho é avaliado usando várias métricas de erro, focando em quão de perto a estimativa de risco de cada método acompanha o erro verdadeiro no alvo.
Risco mais confiável em espaços bagunçados e de alta dimensão
Em quase todos os cenários sintéticos e conjuntos reais, o KMM fornece as estimativas de risco mais precisas e estáveis. Ele reduz o erro percentual absoluto médio em cerca de 12 a 87 por cento em comparação com as alternativas e, crucialmente, evita a "explosão de pesos" que atormenta a ponderação por importância em altas dimensões. Em layouts desafiadores de células tumorais, por exemplo, a ponderação por importância pode gerar erros que excedem vários milhares por cento, enquanto o KMM se mantém dentro de limites gerenciáveis. A reponderação baseada em classificadores normalmente melhora em relação aos métodos ingênuos, mas ainda fica atrás do KMM, refletindo seu foco em discriminação em vez de correspondência fiel de distribuições. Esses resultados sugerem que, para aplicações espaciais—onde os dados são agrupados, viesados e de alta dimensão—o KMM oferece uma forma fundamentada de estimar o quanto confiar nas previsões de um modelo.
O que isso significa para decisões do mundo real
Para não especialistas que usam aprendizado de máquina em ecologia, ciência ambiental ou biomedicina, a mensagem é direta: as métricas de teste padrão podem ser perigosamente enganosas quando sua região de implantação difere de onde seus dados vieram. O Kernel Mean Matching fornece uma maneira de corrigir isso reequilibrando a influência das amostras de treinamento para que elas se assemelhem estatisticamente aos locais ou tecidos que importam. O estudo mostra que essa abordagem produz consistentemente estimativas de erro de modelo mais honestas, mesmo sob viés espacial severo e com muitas variáveis de entrada. Na prática, isso significa orientação mais confiável na escolha entre modelos e uma imagem mais clara de onde as previsões são confiáveis—e onde a cautela é necessária.
Citação: Serov, E., Koldasbayeva, D. & Zaytsev, A. Kernel mean matching enhances risk estimation under spatial distribution shifts. Sci Rep 16, 6921 (2026). https://doi.org/10.1038/s41598-026-36740-7
Palavras-chave: mudança de distribuição, modelagem espacial, kernel mean matching, estimação de risco de modelo, dados ecológicos e biomédicos