Clear Sky Science · pt
Aprimorando a resiliência adversarial em cache semântico para sistemas seguros de geração aumentada por recuperação
Por que uma memória de IA mais inteligente importa
À medida que chatbots e assistentes de IA entram em locais de trabalho, salas de aula e até hospitais, eles passam a depender cada vez mais de um artifício chamado “lembrar” perguntas anteriores para responder a dúvidas semelhantes de forma mais rápida e barata. Essa memória, conhecida como cache semântico, pode reduzir drasticamente custos e atrasos — mas também pode abrir uma porta dos fundos para atacantes enganarem sistemas a ponto de vazar segredos ou fornecer respostas erradas. Este artigo explora esses riscos ocultos e apresenta um novo desenho, SAFE-CACHE, que pretende manter a memória da IA rápida ao mesmo tempo em que a torna muito mais difícil de ser abusada.
Como os assistentes de IA atuais reutilizam respostas passadas
Modelos de linguagem de grande porte (LLMs) modernos costumam operar dentro de uma arquitetura chamada geração aumentada por recuperação (RAG). Quando você faz uma pergunta, o sistema primeiro busca documentos relevantes e depois faz o LLM gerar uma resposta usando esse material. Como muitas pessoas formulam praticamente a mesma pergunta com palavras diferentes, empresas passaram a adicionar um cache semântico: um repositório de perguntas e respostas antigas, além de impressões matemáticas de seus significados. Quando chega uma nova consulta, o sistema verifica se sua impressão digital está “próxima o bastante” de uma já presente no cache; se estiver, simplesmente reutiliza a resposta antiga em vez de executar todo o processo de busca e geração novamente. Essa ideia, adotada por ferramentas como GPTCache e por plataformas em nuvem da Microsoft e do Google, economiza dinheiro e acelera respostas em chatbots de suporte ao cliente, ferramentas de bate-papo empresariais e outros serviços de IA com alto tráfego. 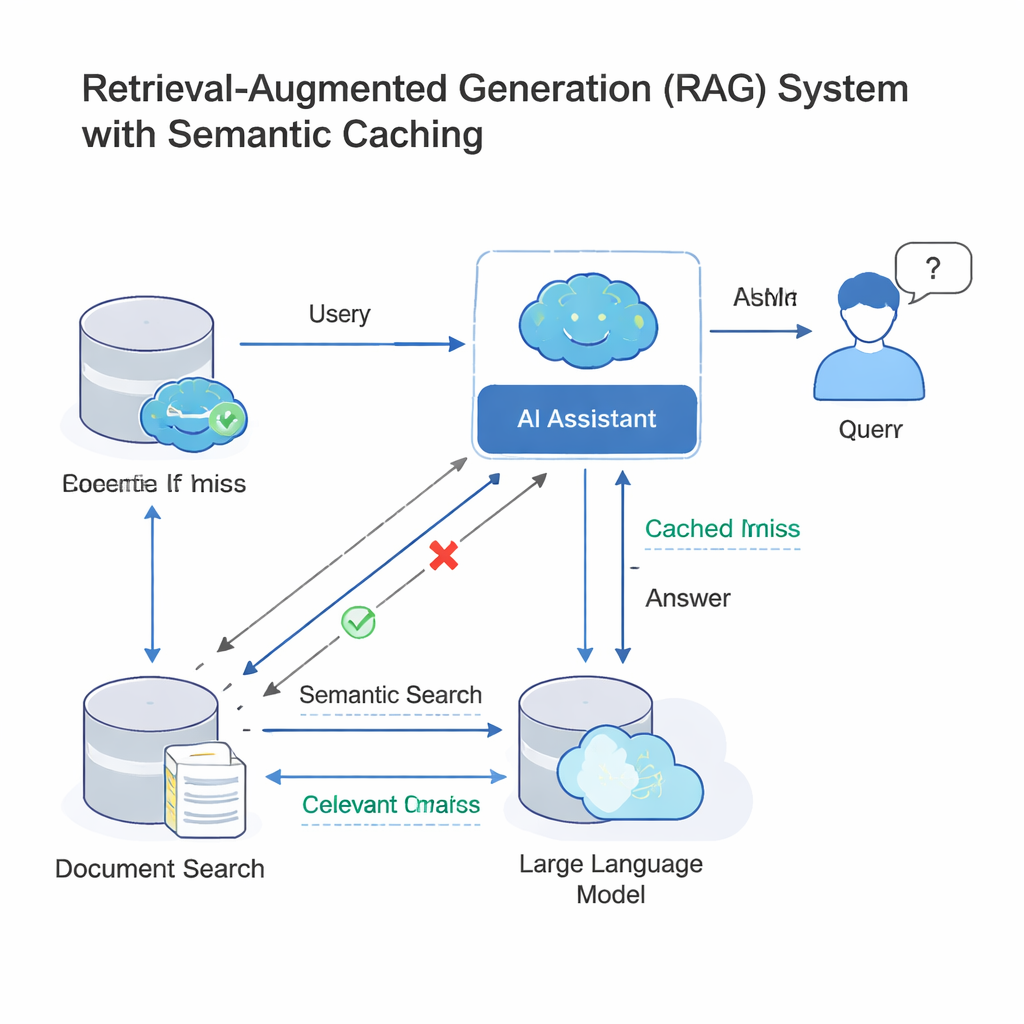
Quando uma redação astuta vira um buraco de segurança
A mesma atalho que aumenta a velocidade também pode ser usada contra o sistema. Atacantes podem elaborar consultas que pareçam semelhantes na forma, mas signifiquem algo diferente — alterando uma data, trocando uma pessoa ou lugar, ou invertendo o sentido de uma pergunta. Como os caches atuais confiam em grande parte na similaridade numérica das embeddings (essas impressões de significado), uma consulta maliciosa pode “colidir” com uma legítima nesse espaço vetorial, mesmo que a intenção tenha mudado. Essa colisão pode levar o cache a retornar a resposta errada, potencialmente expondo informações confidenciais ou permitindo que dados contaminados sejam armazenados para uso posterior. Trabalhos anteriores já demonstraram que bancos de dados de vetores e caches semânticos podem ser envenenados dessa forma, especialmente quando muitos usuários compartilham o mesmo cache subjacente em sistemas multi-tenant.
Transformando perguntas dispersas em clusters de intenção estáveis
Os autores argumentam que o problema raiz é tratar cada consulta de forma isolada. A solução deles, SAFE-CACHE, agrupa pares pergunta–resposta anteriores em clusters que representam intenções subjacentes — como “quem venceu a eleição para o Senado do Arizona em 2022?” ou “qual é o preço do software Full Self-Driving da Tesla?” Em vez de comparar novas consultas diretamente com instâncias antigas individuais, o SAFE-CACHE as compara com o centro, ou centróide, de cada cluster. Para construir esses clusters, ele primeiro gera a embedding de cada par completo de pergunta mais resposta (não apenas da pergunta) para que diferenças nas respostas — como uma recusa em revelar dados sensíveis — também moldem a agrupamento. Em seguida, usa um algoritmo de detecção de comunidades para encontrar clusters naturais e testes estatísticos para sinalizar grupos ruidosos que podem misturar intenções diferentes ou entradas adversariais. Esses clusters suspeitos são limpos e divididos usando um bi-encoder especialmente treinado que aprendeu a aproximar exemplos honestos e afastar os envenenados.
Treinando um modelo pequeno para fortalecer a memória da IA
Algumas intenções aparecem poucas vezes no tráfego real, tornando seus clusters frágeis. Para estabilizá-los, o SAFE-CACHE usa um modelo de linguagem leve ajustado (uma variante Gemma-3 de 1 bilhão de parâmetros) para gerar paráfrases que mantêm a mesma intenção enquanto variam a redação. Esses exemplos extras tornam os clusters mais densos e seus centróides mais confiáveis, sem precisar que humanos rotulem milhares de variantes. Em tempo de execução, cada nova consulta é embedada e comparada com esses centróides. Se sua similaridade com o centróide que melhor corresponde estiver acima de um limiar cuidadosamente ajustado, a resposta em cache é retornada; caso contrário, o sistema recorre ao pipeline RAG completo e decide posteriormente como agrupar o novo par. Em experimentos usando métodos de ataque fortes baseados em reescrita metamórfica e GPT‑4.1, o SAFE-CACHE reduziu tentativas de envenenamento bem-sucedidas em aproximadamente dois terços a três quartos em comparação com um desenho ao estilo GPTCache, mantendo a velocidade de resposta essencialmente inalterada. 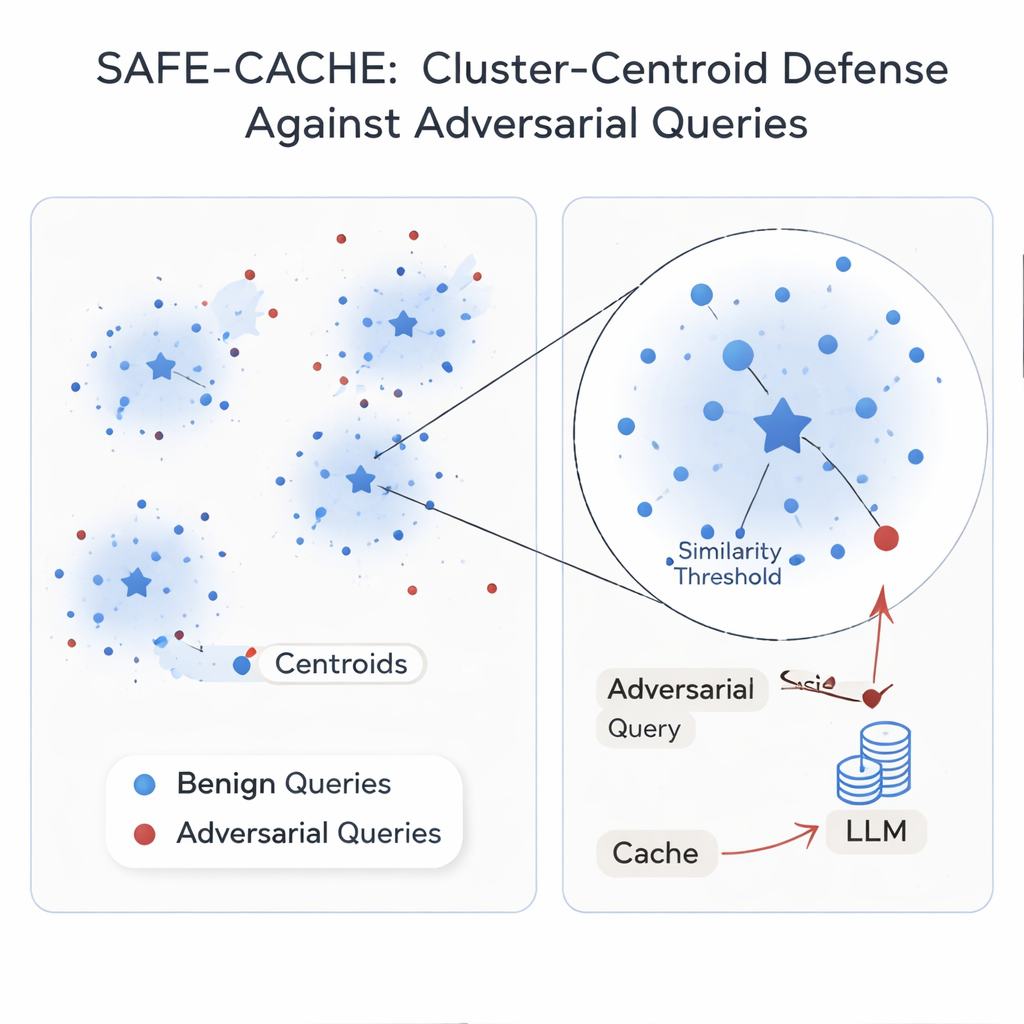
O que isso significa para usuários comuns de IA
Para não especialistas, a conclusão é que dar “memória” a sistemas de IA não é de graça: projetos ingênuos podem vazar segredos ou ser manipulados para espalhar respostas erradas. O SAFE-CACHE demonstra que, ao organizar a memória em torno de padrões mais profundos no nível de intenção e reforçar esses padrões com paráfrases direcionadas, é possível preservar os benefícios de velocidade e custo do cache semântico ao mesmo tempo em que se reduz drasticamente o risco de ataque. À medida que assistentes de IA se tornam uma porta de entrada para dados sensíveis — de registros empresariais a informações pessoais — abordagens como o SAFE-CACHE serão fundamentais para garantir que o que a IA lembra não possa ser facilmente usado contra nós.
Citação: Afiffy, M., Fakhr, M.W. & Maghraby, F.A. Enhancing adversarial resilience in semantic caching for secure retrieval augmented generation systems. Sci Rep 16, 5936 (2026). https://doi.org/10.1038/s41598-026-36721-w
Palavras-chave: cache semântico, geração aumentada por recuperação, ataques adversariais, defesa baseada em cluster, segurança de LLM