Clear Sky Science · pt
Autoencoder guiado por importância de features para redução de dimensionalidade em sistemas de detecção de intrusões
Por que defesas cibernéticas mais inteligentes importam
Cada e-mail que você envia, vídeo que você transmite e compra que realiza viaja por redes que estão continuamente sob ataque. Sistemas de Detecção de Intrusões (IDS) atuam como alarmes para essas redes, identificando comportamentos suspeitos antes que se tornem uma violação. Mas os dados de redes modernas são enormes e complexos, e vasculhar todos esses detalhes pode sobrecarregar os sistemas ou levá-los a perder ataques sutis. Este artigo explora uma nova forma de reduzir esses dados de modo inteligente para que as ferramentas de IDS fiquem mais rápidas e melhores em detectar até ataques cibernéticos raros e difíceis de perceber. 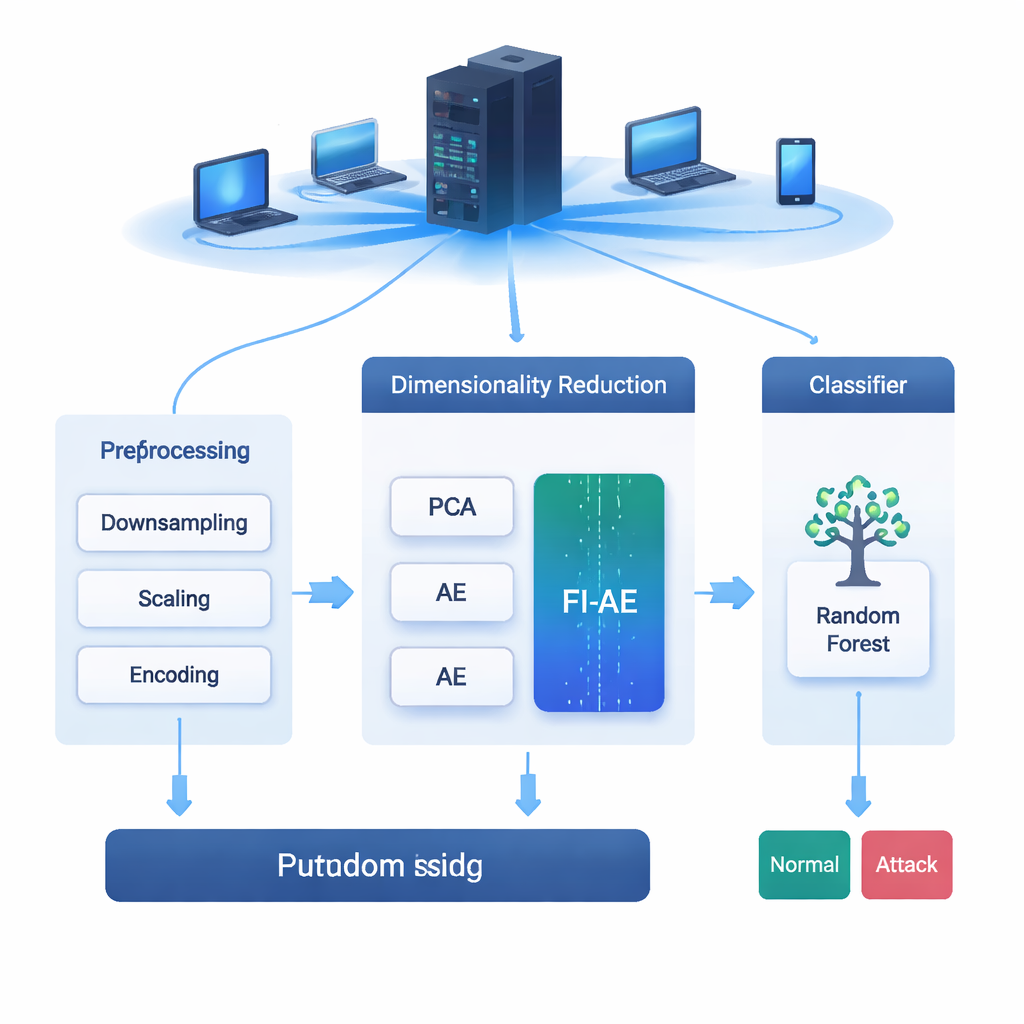
O problema de ter dados de rede demais
Registros de tráfego de rede contêm dezenas a centenas de medidas para cada conexão — como duração, número de bytes e taxas de erro. Modelos de IDS baseados em aprendizado de máquina dependem dessas medidas para decidir se o tráfego é normal ou malicioso. No entanto, usar todas elas pode retardar a detecção e às vezes até prejudicar a precisão, especialmente quando alguns ataques são muito mais raros que outros. Métodos comuns de redução de dimensionalidade, como Análise de Componentes Principais (PCA) e autoencoders padrão, comprimem os dados mas concentram-se principalmente em reconstruir o tráfego geral. Isso significa que podem dar mais atenção à maioria das conexões do dia a dia e negligenciar os padrões tênues e distintivos que caracterizam tipos de ataque minoritários.
Uma nova forma de ranquear o que realmente importa
Os autores apresentam um esquema de ranqueamento de features chamado importância one-versus-all (OVA) para lidar com esse desequilíbrio. Em vez de perguntar “Quais medidas são mais úteis no geral?”, o OVA faz essa pergunta separadamente para cada tipo de ataque. Para cada classe (por exemplo, tráfego normal, negação de serviço ou tentativa de adivinhação de senha), é treinado um modelo de random forest para distinguir essa classe de todas as outras. As pontuações de importância incorporadas no modelo revelam então quais medidas são especialmente úteis para aquela classe específica. Repetindo esse processo para cada classe e depois, para cada medida, tomando a maior importância que ela atinge em qualquer classe, o método constrói um único vetor de pesos que destaca features relevantes para pelo menos um tipo de ataque — mesmo que esse ataque seja raro nos dados.
Ensinando um autoencoder a focar nos sinais-chave
Para usar esses pesos, os pesquisadores desenvolvem um autoencoder baseado na importância de features (FI-AE). Como um autoencoder convencional, o FI-AE comprime a entrada em uma representação de baixa dimensão (gargalo) e depois reconstrói os dados originais. A diferença está no objetivo de treinamento: em vez de tratar todos os erros de reconstrução igualmente, o modelo usa um erro quadrático médio ponderado que multiplica o erro de cada feature pela sua importância baseada em OVA. Em termos simples, o FI-AE é mais penalizado por representar mal medidas que são cruciais para distinguir ataques, e menos penalizado por detalhes menos informativos. A própria arquitetura é compacta, reduzindo registros de rede a apenas 16 números enquanto utiliza técnicas padrão como normalização por lotes, dropout e o otimizador Adam para manter o treinamento estável.
Colocando o método à prova
A equipe avalia o FI-AE em três conjuntos de dados amplamente usados para detecção de intrusões: NSL-KDD, UNSW-NB15 e CIC-IDS2017, que juntos cobrem milhões de conexões e uma ampla gama de tipos de ataque. Antes do treinamento, eles limpam os dados balanceando distribuições de classes extremamente enviesadas, escalando features numéricos e codificando categorias de forma que preserve sua relação com os rótulos alvo. Em seguida, comparam três pipelines que terminam todos com um classificador random forest: um usando PCA, outro usando um autoencoder padrão e outro usando FI-AE para redução de dimensionalidade. Em todos os três conjuntos de dados, o FI-AE consistentemente entrega maior acurácia e pontuações F1, com ganhos particularmente notáveis em ataques minoritários e raros onde métodos tradicionais tendem a ter dificuldades. 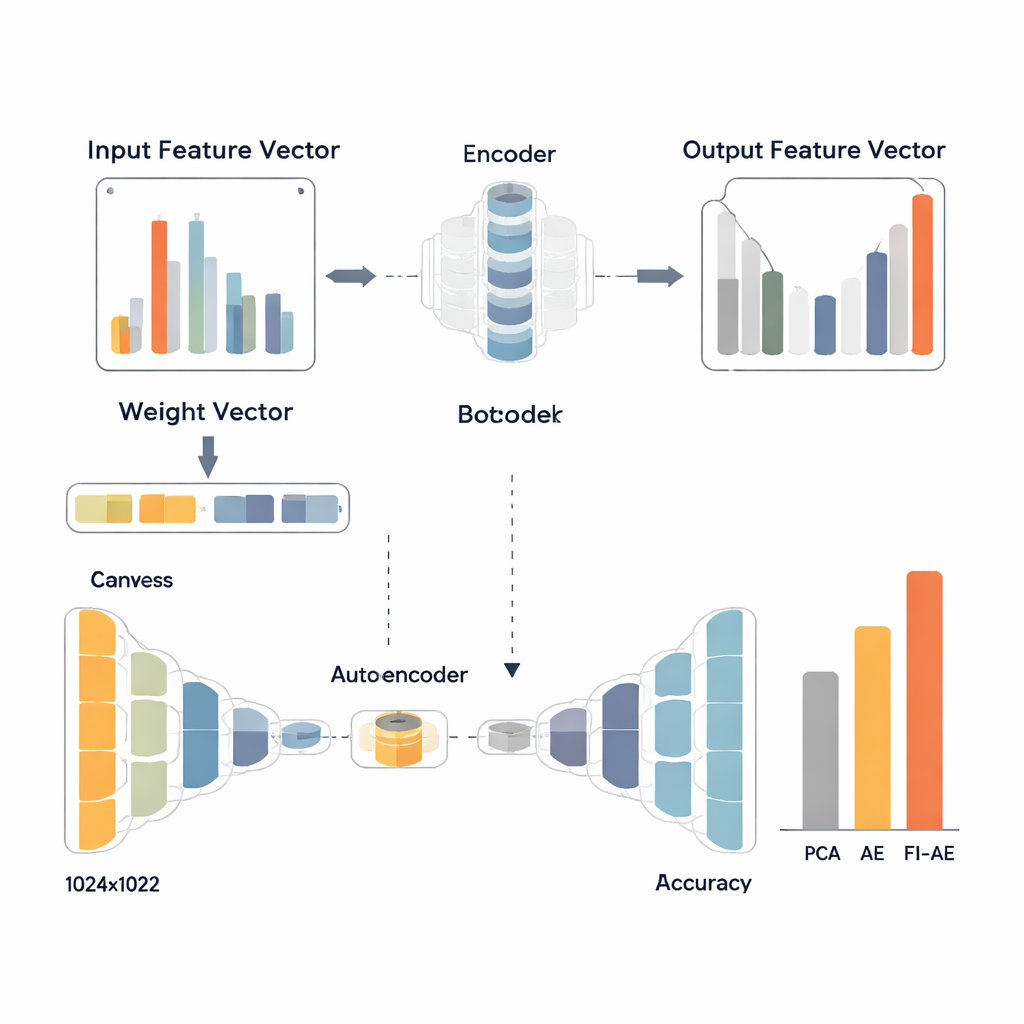
O que isso significa para a segurança do dia a dia
Para não especialistas, a mensagem principal é que este trabalho oferece uma lente mais criteriosa para monitoramento de redes. Em vez de simplesmente comprimir dados para torná-los menores, o FI-AE aprende a preservar as medidas que realmente importam para detectar diferentes tipos de ataque, incluindo os raros que podem ser os mais danosos. Com apenas 16 features destiladas, sistemas de detecção de intrusões baseados nessa abordagem podem rodar com mais eficiência ao mesmo tempo em que alcançam ou superam a precisão de detecção de ponta. Na prática, isso significa que ferramentas de segurança podem vasculhar mais tráfego, reagir mais rapidamente e fornecer melhor proteção aos serviços digitais dos quais as pessoas dependem diariamente.
Citação: Abdel-Rahman, M.A., Alluhaidan, A.S., El-Rahman, S.A. et al. Feature importance guided autoencoder for dimensionality reduction in intrusion detection systems. Sci Rep 16, 5013 (2026). https://doi.org/10.1038/s41598-026-36695-9
Palavras-chave: detecção de intrusão, segurança de rede, redução de dimensionalidade, autoencoder, importância de atributos