No leito marinho, veículos subaquáticos autônomos atuam como nossos olhos e ouvidos para pesquisas climáticas, inspeção de infraestrutura e busca e salvamento. Ainda assim, esses submarinos robóticos enfrentam um problema básico: comunicar-se e raciocinar com clareza em um ambiente hostil onde os sinais são lentos, ruidosos e a energia é escassa. Este artigo apresenta uma nova forma de ajudar robôs subaquáticos a se comunicar, detectar objetos e manter a segurança, combinando realidade aumentada e virtual com um ramo da inteligência artificial chamado aprendizado por reforço.
Por que a comunicação subaquática é tão difícil
Enviar dados debaixo d’água é muito mais difícil do que enviá-los pelo ar. Ondas de rádio, que alimentam Wi‑Fi e 5G, são rapidamente absorvidas pela água do mar. Sinais acústicos (baseados em som) viajam mais longe, mas oferecem taxas de dados muito baixas e podem sofrer atrasos, ecos ou distorções. Indução magnética funciona apenas em algumas dezenas de metros. Sistemas de controle existentes para robôs subaquáticos frequentemente tratam esses canais separadamente e usam regras fixas para navegação e sensoriamento. Isso os torna lentos para se adaptar quando as condições mudam, desperdiça bateria e deixa os links de comunicação abertos a escutas ou ataques.
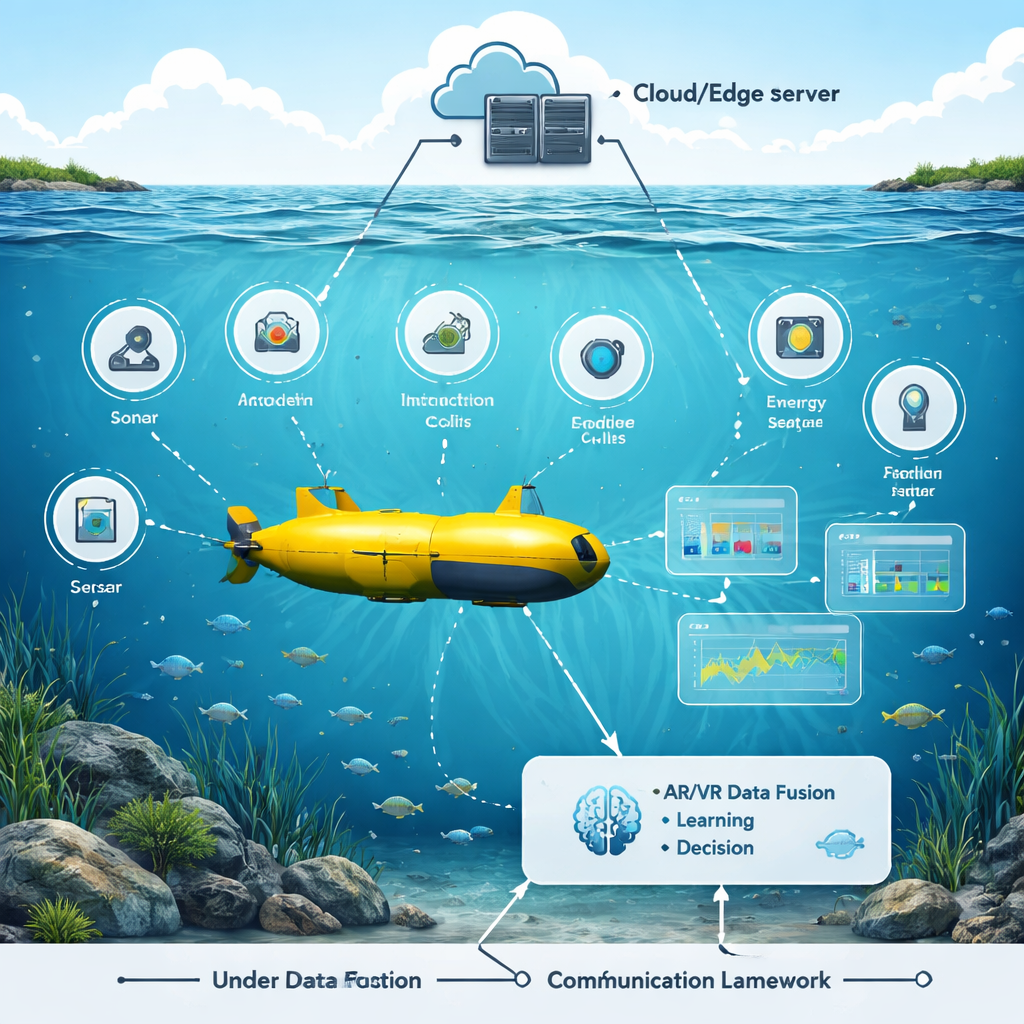
Um oceano virtual para treinar instintos melhores Figura 1.
Os autores construíram um ambiente de testes em realidade aumentada e virtual que recria um mundo subaquático movimentado: peixes em movimento, rochas, barcos e boias, junto com ruído realista e perda de sinal na água. Um veículo subaquático simulado cruza esse ambiente usando muitos sensores — sonar, câmeras, modems acústicos, medidores de energia e rastreadores de posição. Na cena virtual, os pesquisadores podem ajustar controles para alterar posições de objetos, condições da água e configurações dos sensores, e ver imediatamente como o robô responde. Essa camada de AR/VR não é apenas aparência; ela funde fluxos brutos de sensores em uma imagem 3D unificada que é mais fácil para um sistema de IA entender e agir.
Ensinando o robô a aprender por experiência
No cerne da estrutura está uma estratégia de IA que os autores chamam de Estratégia de Agendamento Adaptativo de Realidade Aumentada e Aprendizado por Reforço (AARLSS). Em vez de seguir um roteiro fixo, o robô aprende por tentativa e erro no oceano virtual. A cada momento, ele observa seu estado sensorial fusionado, escolhe uma ação (como mudar de rumo, ajustar a taxa de amostragem dos sensores ou alternar entre comunicações de curto e longo alcance) e recebe uma recompensa. Essa recompensa equilibra quatro objetivos: poupar energia, reduzir atraso, diminuir o risco de segurança e usar menos recursos de computação e rede. Uma rede profunda de Q‑learning armazena e atualiza o valor esperado de diferentes decisões, usando mini-lotes de experiências passadas guardadas em uma memória de replay para que o robô aprenda tanto de situações recentes quanto antigas.
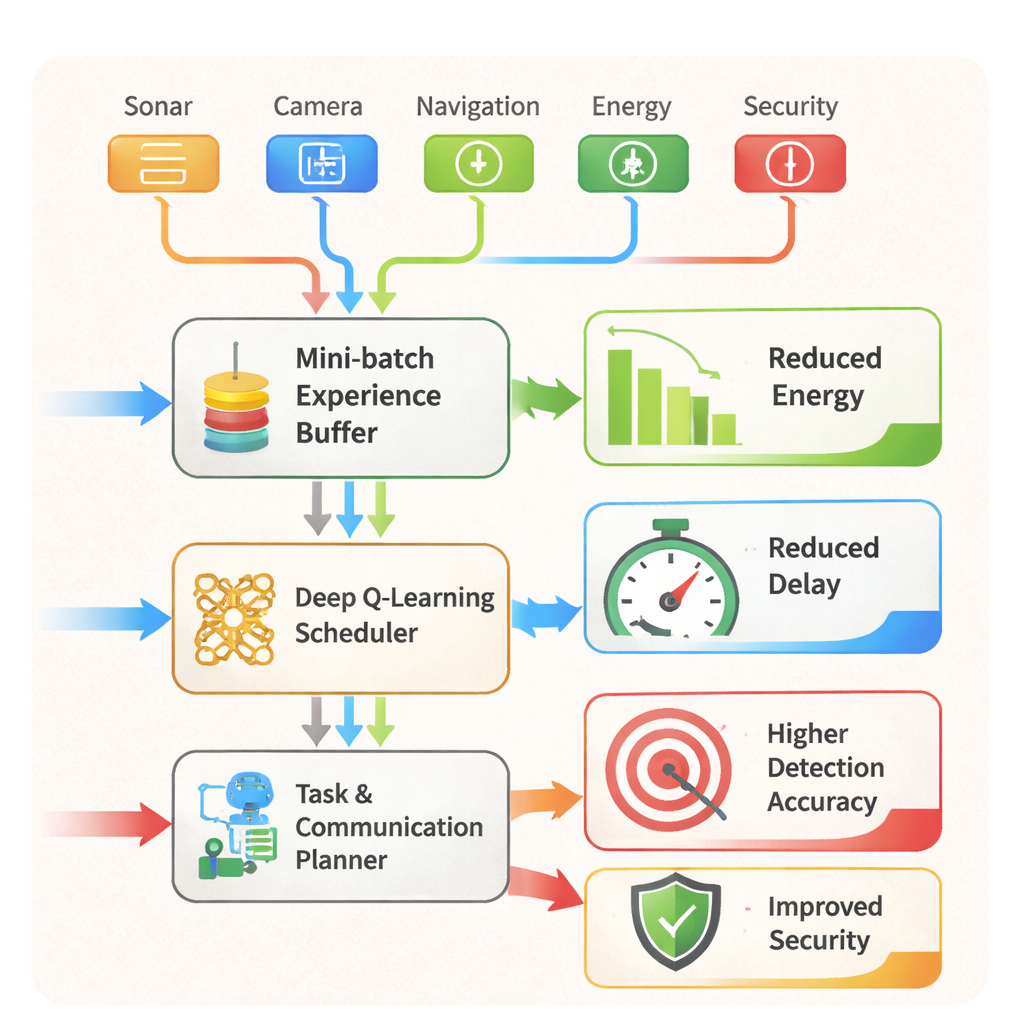
Do agendamento inteligente a missões mais seguras Figura 2.
AARLSS também atua como um escalonador em tempo real. Ele decide quais tarefas — navegação, detecção de objetos, comunicação ou verificações de segurança — devem rodar onde e quando, e se os dados devem ser processados no robô, descarregados para um servidor de edge ou adiados. Além disso, um sistema embutido de detecção de intrusões examina continuamente padrões nos dados de sensores e de rede para sinalizar anomalias que podem indicar um ataque ou mau funcionamento, e pode disparar ações protetivas, como bloquear links arriscados ou forçar computação apenas local. Em testes dentro do simulador AR/VR, a estrutura superou vários métodos estabelecidos de aprendizado por reforço. Cortou o consumo de energia do veículo subaquático em cerca de 20%, reduziu os atrasos de comunicação e de tarefas em aproximadamente 18–20%, e elevou a precisão de detecção de objetos para cerca de 97–98%, mesmo durante manobras complexas e em cenas sobrecarregadas.
O que isso significa para os oceanos do mundo real
Para não especialistas, a mensagem principal é que esta pesquisa aponta para robôs subaquáticos mais independentes, eficientes e confiáveis. Ao treinar em um oceano virtual rico e aprender a equilibrar energia, tempo, precisão e segurança ao mesmo tempo, o AARLSS permite que um veículo escolha quando falar, quando ouvir e quando ficar em silêncio para economizar energia — tudo enquanto mantém uma vigilância aguçada sobre o entorno e protege seus dados. Embora esses resultados provêm de um simulador sofisticado em vez de mar aberto, eles sugerem que futuras frotas de robôs subaquáticos poderiam realizar missões mais longas, seguras e ricas em dados com menos supervisão humana, melhorando desde a ciência marinha até inspeções da indústria offshore.
Citação: Lakhan, A., Mohammed, M.A., Ghani, M.K.A. et al. A novel augmented reality and reinforcement learning empowered communication framework for underwater unmanned autonomous vehicle.
Sci Rep16, 6241 (2026). https://doi.org/10.1038/s41598-026-36647-3