Clear Sky Science · pt
Reconhecimento inteligente do comportamento dos alunos para ambientes de aprendizagem inteligentes
Por que salas de aula mais inteligentes precisam ver o que os alunos estão fazendo
Em muitas salas de aula, os professores precisam adivinhar quem está acompanhando a aula, quem está perdido e quem discretamente está fora de tarefa. Este artigo explora como a inteligência artificial pode reconhecer automaticamente o que os alunos estão fazendo — como ler, escrever ou levantar a mão — a partir de fotos comuns de sala de aula. Ao transformar imagens brutas em medidas confiáveis da atividade em sala, o sistema busca fornecer aos professores feedback em tempo real sobre o engajamento, sem depender de observação demorada ou monitoramento intrusivo.
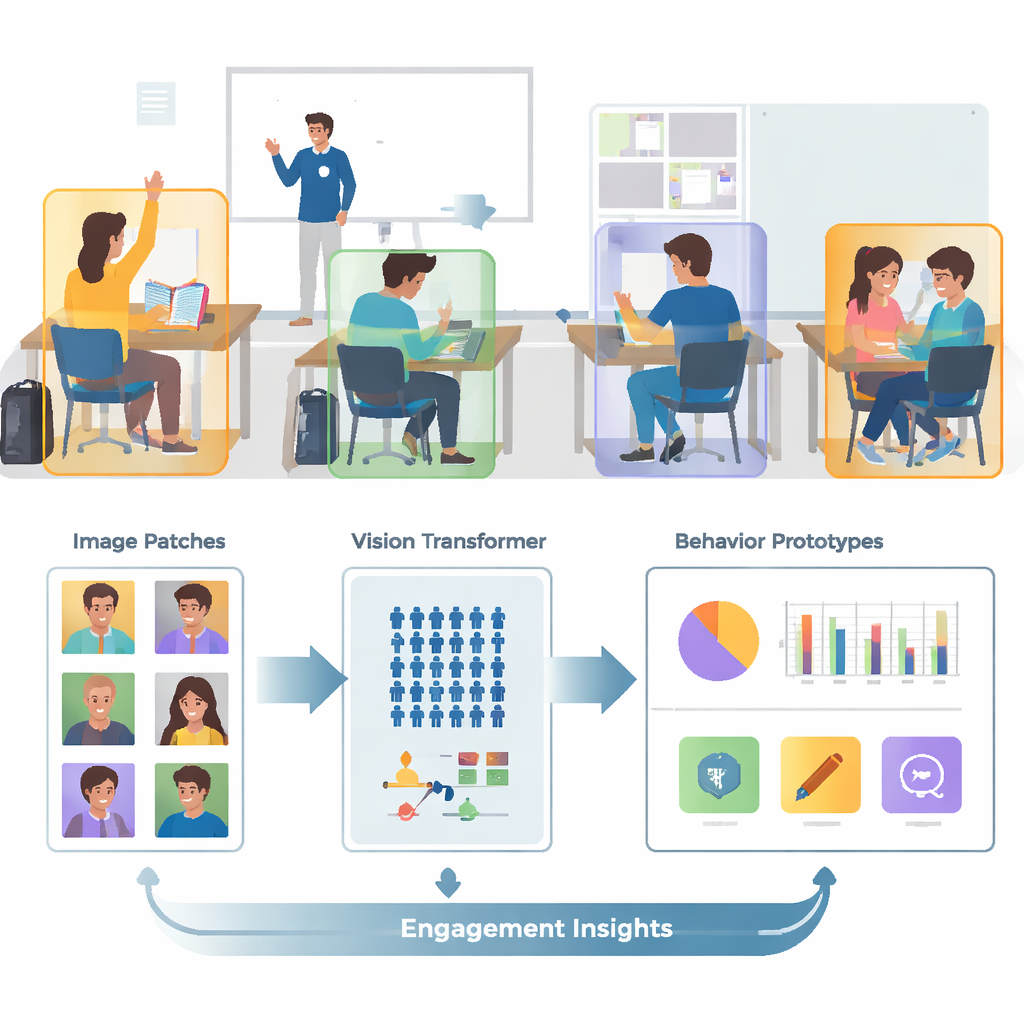
De fotos confusas a recortes focados
Salas de aula reais são cheias, movimentadas e visualmente confusas. Uma única imagem pode conter dezenas de alunos, corpos sobrepostos e detalhes de fundo que distraem, como paredes, telas e cartazes. Os autores partem de uma coleção pública de imagens chamada SCB‑05, que contém milhares de fotos de sala de aula rotuladas com comportamentos específicos — como levantar a mão, ler, escrever, ficar em pé, falar ou interagir no quadro. Em vez de alimentar cenas inteiras para o computador, o sistema usa primeiros arquivos de anotação para recortar apenas as regiões ao redor de cada aluno ou professor. Essa etapa de pré‑processamento elimina grande parte da desordem visual, permitindo que o modelo se concentre na postura, na posição das mãos e em outras pistas que distinguem um comportamento do outro.
Como a IA aprende novos comportamentos a partir de pouquíssimos exemplos
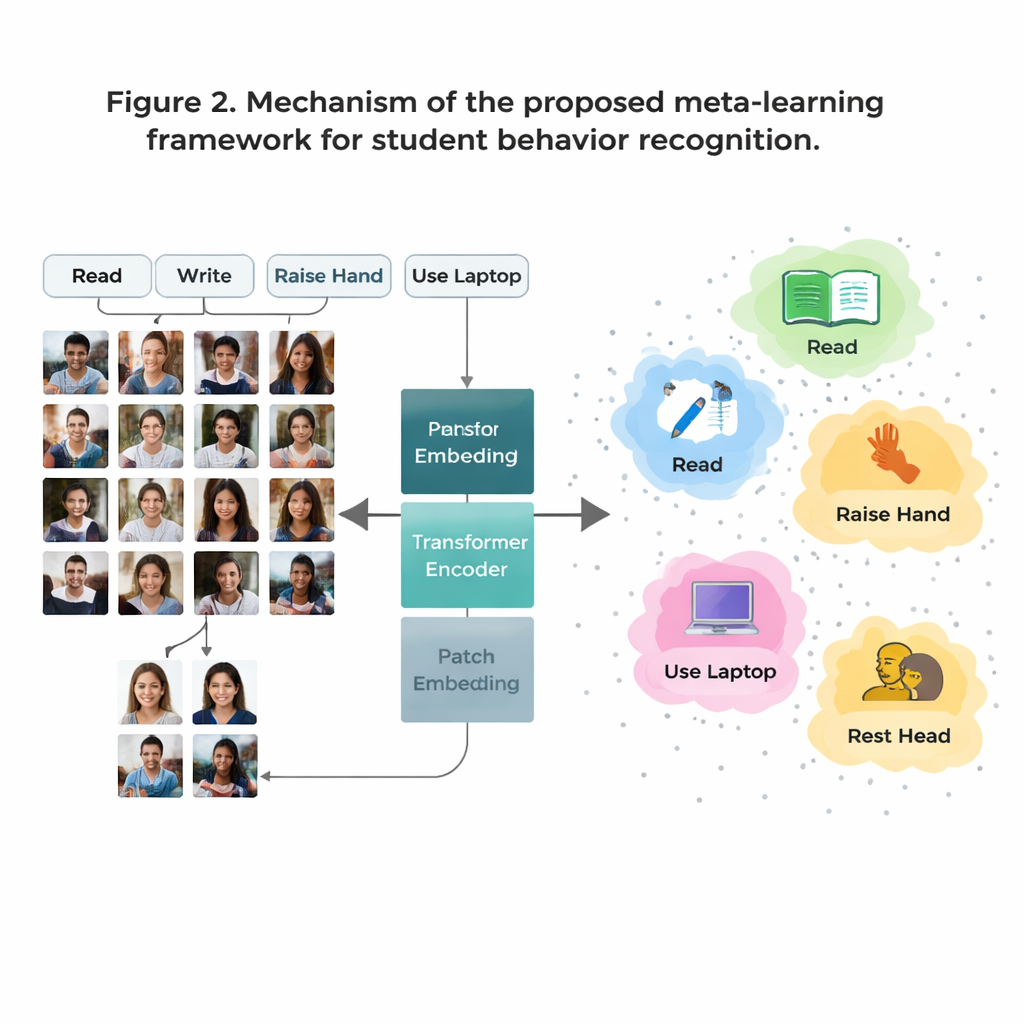
Um grande obstáculo é que alguns comportamentos em sala são comuns nos dados (como ler), enquanto outros são raros (como interações breves no palco). Coletar imagens rotuladas suficientes para cada comportamento possível é caro e levanta preocupações de privacidade. Para superar isso, os autores utilizam uma estratégia chamada "few‑shot learning", na qual o modelo é treinado para reconhecer classes novas a partir de apenas alguns exemplos. Eles organizam o treinamento como muitas tarefas pequenas, cada uma contendo apenas alguns comportamentos e poucas imagens de amostra por comportamento. Para cada tarefa, o sistema forma um “protótipo” simples para cada comportamento, calculado pela média de sua representação interna dessas amostras. Novas imagens são então classificadas verificando a qual protótipo estão mais próximas, permitindo que o modelo se adapte rapidamente mesmo quando os dados são escassos.
Vendo a sala inteira, não apenas pequenos detalhes
Sistemas de imagem tradicionais chamados redes neurais convolucionais tendem a focar em padrões locais pequenos, como bordas ou texturas. Isso pode ser limitador quando dois comportamentos, como ler e escrever, parecem muito semelhantes de perto. Este trabalho substitui essas redes antigas por um Vision Transformer, um modelo que divide cada imagem em patches e aprende como todos os patches se relacionam entre si. Essa visão global ajuda o sistema a entender diferenças sutis de postura e pistas de longo alcance — como a relação entre uma mão levantada e um professor na frente da sala. A equipe ainda aprimora o modelo treinando-o para agrupar imagens do mesmo comportamento enquanto separa comportamentos parecidos mas distintos, com ênfase extra em casos “difíceis” e confusos. Isso torna o mapa interno dos comportamentos mais limpo e mais fácil de separar.
Quão bem funciona e por que isso importa
No benchmark SCB‑05, o método proposto alcança cerca de 91% de acurácia geral e pontuações fortes em métricas mais exigentes que levam em conta dados desbalanceados. Comportamentos comuns como leitura e levantar a mão são reconhecidos especialmente bem, enquanto comportamentos mais raros, como escrever no quadro, continuam mais desafiadores, mas ainda apresentam desempenho superior ao de sistemas anteriores. Inspeções visuais dos agrupamentos internos do modelo mostram que comportamentos distintos formam grupos compactos e bem separados, indicando que a IA aprendeu “assinaturas” distintas das ações em sala. Quando testado em um conjunto de dados de outra sala de aula com ângulos de câmera e disposições diferentes, o desempenho caiu apenas ligeiramente, sugerindo que a representação aprendida não está vinculada a uma única sala ou escola.
O que isso significa para o ensino e a aprendizagem
Em termos práticos, o estudo mostra que computadores podem identificar com confiabilidade muitos comportamentos-chave dos alunos a partir de imagens estáticas, mesmo quando viram apenas alguns exemplos de cada um. Em vez de substituir professores, esses sistemas poderiam resumir discretamente quem está engajado, quem busca ajuda com frequência ou quais atividades tendem a perder atenção — tudo isso sem rastrear identidades dos alunos. Com trabalho adicional em privacidade, equidade e análise em vídeo ao longo do tempo, esse tipo de IA sensível ao comportamento pode tornar‑se um aliado poderoso para educadores que buscam projetar ambientes de aprendizagem mais responsivos e inclusivos.
Citação: Abozeid, A., Alrashdi, I. & Al-Makhlasawy, R.M. Intelligent recognition of students’ behavior for smart learning environments. Sci Rep 16, 5674 (2026). https://doi.org/10.1038/s41598-026-36633-9
Palavras-chave: sala de aula inteligente, comportamento do aluno, visão computacional, few-shot learning, vision transformer