Clear Sky Science · pt
Avaliação detalhada de modelos de linguagem grandes em medicina usando modelagem diagnóstica cognitiva não paramétrica
Por que isso importa para futuras consultas médicas
Sistemas de inteligência artificial que conversam e escrevem, conhecidos como modelos de linguagem grandes, estão rapidamente saindo dos laboratórios de pesquisa e entrando em hospitais. Eles já podem ajudar médicos a interpretar prontuários complexos, sugerir tratamentos e responder a perguntas médicas. Mas a maioria dos testes desses sistemas fornece apenas uma pontuação geral, semelhante a uma nota final, que pode ocultar pontos cegos perigosos. Este estudo apresenta uma nova maneira de analisar essas pontuações e revelar exatamente quais áreas da medicina esses modelos realmente compreendem — e onde eles ainda podem representar risco para os pacientes.
Indo além de uma única nota de prova
Hoje, a maioria das IAs médicas é avaliada pelo número de perguntas respondidas corretamente em exames modelados a partir de provas de licenciamento médico. Essa abordagem é simples, porém grosseira. Um modelo pode obter uma pontuação geral alta e ainda ser fraco em um campo crítico, como interpretação de ritmo cardíaco ou doenças hepáticas. Em clínicas reais, essas lacunas podem ter consequências de vida ou morte. Os autores defendem que o uso seguro de IA na medicina exige uma avaliação mais profunda e detalhada — capaz de mapear um perfil de habilidades, em vez de fornecer uma única nota possivelmente enganosa.

Uma forma mais inteligente de testar o conhecimento médico
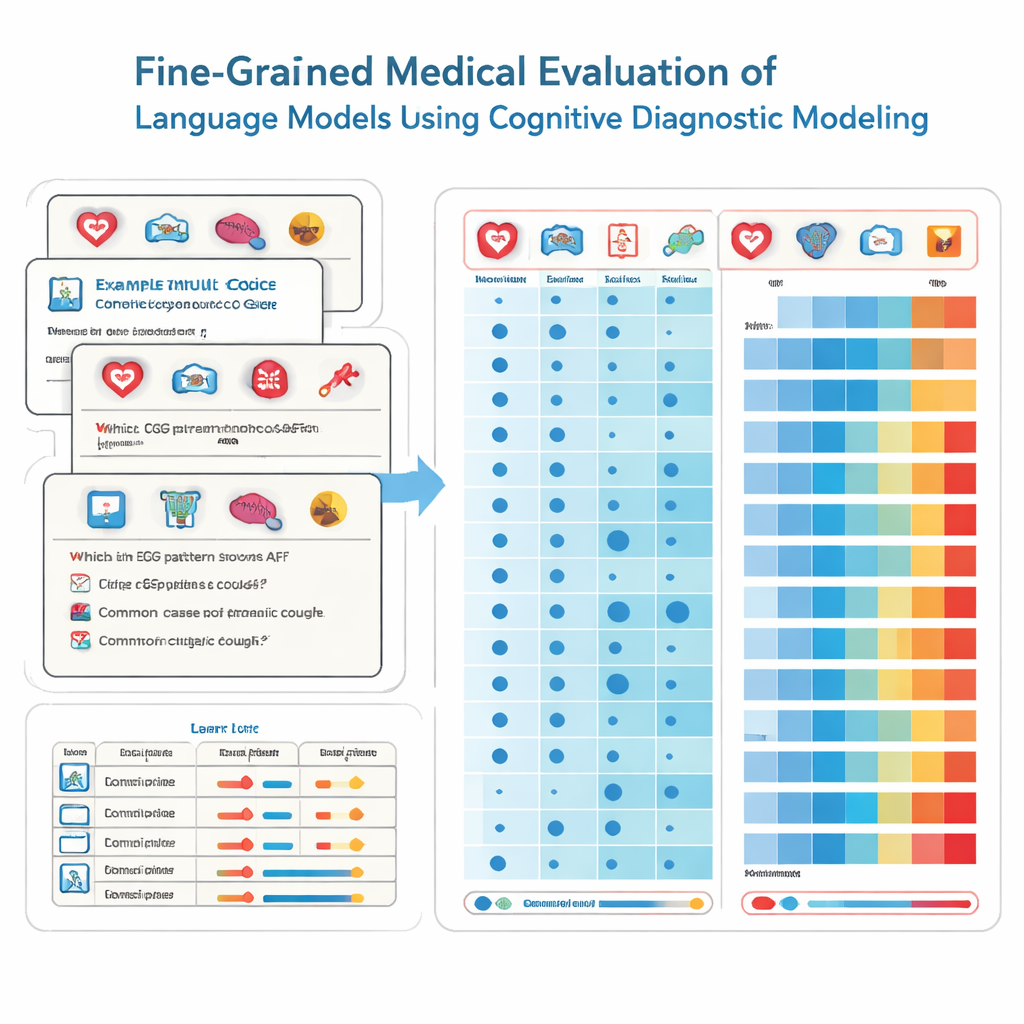
Para alcançar isso, os pesquisadores emprestam ferramentas da psicologia educacional chamadas avaliação diagnóstica cognitiva. Em vez de tratar cada questão de exame como se medisse a mesma habilidade vaga, esse método divide o conhecimento médico em blocos específicos, como cardiologia, radiologia ou atendimento de emergência. Cada questão de múltipla escolha é marcada com a combinação exata de habilidades que ela exige. Usando uma técnica estatística não paramétrica, a equipe compara como um modelo responde a milhares de questões com padrões de resposta ideais. A partir disso, inferem se o modelo “dominou” cada habilidade subjacente, de modo semelhante a um boletim detalhado que mostra pontos fortes e fracos por disciplina.
Submetendo 41 modelos de IA a um exame médico
A equipe testou 41 modelos de linguagem amplamente utilizados, incluindo sistemas comerciais e modelos de código aberto, em 2.809 questões cuidadosamente verificadas retiradas de um banco de provas nacional chinês. Essas questões abrangem 22 subdomínios médicos e são destinadas a estudantes prestes a realizar o exame de licenciamento de médicos. Cada questão tem uma resposta correta e é rotulada por especialistas para indicar quais especialidades ela envolve. Usando seu método diagnóstico, os pesquisadores estimaram, para cada modelo, quantos desses 22 atributos médicos ele efetivamente dominava, e não apenas quantas questões respondeu corretamente por acaso.
Bom conhecimento geral, mas lacunas acentuadas
Os resultados são tanto impressionantes quanto preocupantes. Os modelos com melhor desempenho, como vários sistemas comerciais líderes, acertaram a maioria das questões e demonstraram domínio de 20 dos 22 domínios médicos. Entre todos os modelos, o desempenho foi excelente em muitas especialidades comuns, alcançando domínio completo em 15 áreas, incluindo cardiologia, dermatologia e endocrinologia. Ainda assim, a análise detalhada expôs lacunas marcantes em outros campos. A radiologia ficou atrás, com taxas de domínio muito mais baixas, e dois subdomínios — ECG & hipertensão & lipídios e distúrbios hepáticos — não foram dominados por nenhum modelo. Importante notar que alguns modelos menores apresentaram as mesmas habilidades dominadas que modelos muito maiores, revelando que o simples tamanho não garante conhecimento médico amplo e confiável.
Escolhendo a ferramenta certa para a tarefa certa
Esses perfis detalhados importam porque modelos com pontuações gerais muito semelhantes podem ter padrões de pontos fortes e fracos muito diferentes. Um sistema pode ser forte em neurologia e fraco em farmacologia, enquanto outro mostra o padrão oposto. Para gestores hospitalares, isso significa que não é seguro selecionar um assistente de IA apenas com base na sua nota de prova ou no número de parâmetros. Em vez disso, eles precisam de resultados diagnósticos como os deste estudo para alinhar cada modelo a tarefas clínicas específicas e projetar fluxos de trabalho nos quais especialistas humanos revisem as saídas de IA em áreas de alto risco onde o modelo é conhecido por ser fraco.
O que isso significa para pacientes e clínicos
Em termos simples, o estudo conclui que uma “nota” alta em testes médicos não garante que um sistema de IA seja seguro de usar em todas as áreas da medicina. A nova abordagem funciona mais como um check-up completo para a própria IA, revelando quais “órgãos” — no caso, especialidades médicas — estão saudáveis e quais precisam de atenção. Ao descobrir lacunas ocultas em áreas críticas, como interpretação de ECG e doenças hepáticas, o método oferece a hospitais, reguladores e desenvolvedores um roteiro prático: use modelos apenas onde eles demonstraram ser fortes, mantenha humanos firmemente no circuito onde persistem fraquezas e concentre treinamentos futuros nos pontos cegos mais arriscados. Esse tipo de avaliação detalhada, argumentam os autores, não é apenas útil — é essencial antes de confiar cuidados de pacientes à IA.
Citação: Zheng, T., Liu, J., Feng, S. et al. Fine-grained evaluation of large language models in medicine using non-parametric cognitive diagnostic modeling. Sci Rep 16, 6460 (2026). https://doi.org/10.1038/s41598-026-36627-7
Palavras-chave: IA médica, modelos de linguagem grandes, segurança clínica, avaliação de modelos, testes diagnósticos