Clear Sky Science · pt
Otimização multitarefa e estabilidade de convergência com aprendizado hierárquico de características para otimização auto-orientada
IA mais inteligente que consegue conciliar muitas funções ao mesmo tempo
Aplicativos modernos dependem cada vez mais de inteligência artificial que precisa realizar várias tarefas simultaneamente — como compreender imagens e textos juntos, apoiar decisões médicas ou ajudar veículos a perceber a estrada. Mas quando um mesmo modelo de IA aprende muitas habilidades ao mesmo tempo, seu treinamento pode ficar instável e as habilidades podem interferir entre si. Este artigo apresenta uma nova arquitetura de deep learning, chamada Arquitetura Profunda Unificada Multitarefa e Multivista (UMDA), projetada para permitir que um único modelo aprenda a partir de muitos tipos de dados e resolva múltiplas tarefas sem se confundir ou perder estabilidade.
Por que a IA multitarefa atual frequentemente encontra dificuldades
A maior parte dos sistemas atuais que aprendem várias tarefas (aprendizado multitarefa) ou combinam vários tipos de dado, como imagens e texto (aprendizado multivista), sofrem com três problemas principais. Primeiro, tarefas diferentes podem entrar em conflito durante o treinamento: melhorar o desempenho em uma tarefa pode prejudicar silenciosamente outra, um problema conhecido como transferência negativa. Segundo, simplesmente empilhar ou fazer a média das informações oriundas de fontes diferentes frequentemente perde relações sutis porém importantes entre elas. Terceiro, o próprio processo de treinamento pode ficar instável, com grandes oscilações na direção em que os parâmetros do modelo são atualizados. Esses problemas são especialmente críticos em cenários do mundo real, como diagnóstico médico ou inspeção industrial, onde os dados são complexos e as decisões precisam ser confiáveis.
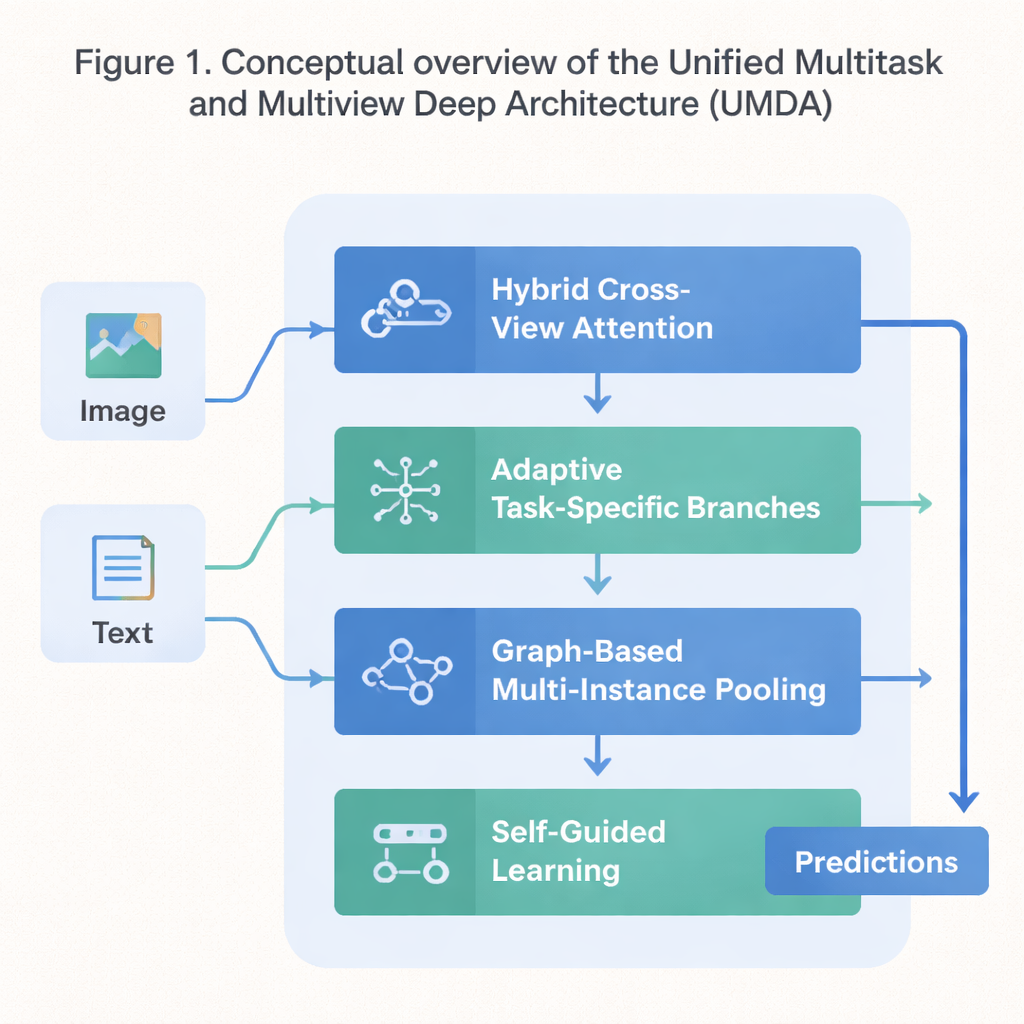
Um plano em quatro partes para aprendizado cooperativo
UMDA enfrenta essas fraquezas dividindo o processo de aprendizado em quatro partes fortemente conectadas que compartilham informações de forma controlada. A primeira parte, chamada Atenção Híbrida Cruzada entre Vistas, observa diferentes vistas do mesmo dado — como texto e imagens que descrevem um filme — e aprende qual vista deve influenciar outra em cada etapa. Ela usa ferramentas matemáticas que incentivam o modelo a evitar depender demais de uma única vista, a manter cada vista distinta e, ao mesmo tempo, a mantê‑las em acordo geral. Em termos simples, ensina o modelo a escutar todos os seus “sentidos” sem deixar que um ofusque os outros.
Manter as tarefas distintas, mas ainda cooperativas
A segunda parte, Ramificações Específicas de Tarefa Adaptativas, separa o conhecimento genérico que muitas tarefas compartilham do conhecimento especial que cada tarefa precisa de forma única. Em vez de forçar todas as tarefas a usar exatamente as mesmas características, a UMDA cria “ramificações” separadas para cada tarefa que ainda podem se comunicar por meio de conexões com pesos cuidadosamente calibrados. Termos de penalização adicionais no objetivo de treinamento empurram essas ramificações para serem suficientemente diferentes para se especializarem, sem se afastarem demais ponto de deixar de cooperar. Esse equilíbrio ajuda a reduzir interferências prejudiciais entre tarefas, ao mesmo tempo em que permite que se beneficiem do que as outras aprendem.
Ver estrutura em coleções de exemplos
Muitos conjuntos de dados reais aparecem como coleções de itens relacionados — por exemplo, múltiplos patches de imagem de uma única lâmina médica ou muitos quadros de um vídeo. A terceira parte da UMDA, chamada Agrupamento Multi‑Instância Baseado em Grafos, modela explicitamente as relações entre esses itens tratando‑os como nós em uma rede. Ela conecta itens semelhantes, permite que a informação flua ao longo dessas conexões e então resume toda a coleção em uma representação compacta única. Regularizações adicionais estimulam itens próximos a concordarem entre si, mantendo ainda diversidade suficiente, permitindo que o modelo capture padrões estruturais que uma simples média deixaria passar.
Treinamento autoajustável para progresso estável
A parte final, Aprendizado Auto‑Guiado, concentra‑se em como o modelo é treinado, em vez de apenas em sua estrutura interna. Ela mede continuamente quão fortes e quão semelhantes são os sinais de treinamento de cada tarefa e então ajusta automaticamente a velocidade de aprendizado de cada uma. Também suaviza e re‑recalibra os gradientes — os sinais que dizem ao modelo como mudar — para que tarefas com objetivos semelhantes se reforcem mutuamente e tarefas que puxam em direções muito diferentes não desestabilizem o treinamento. Em testes com um conjunto de dados padrão que mistura enredos e pôsteres de filmes, a UMDA alcançou maior acurácia média do que uma dúzia de concorrentes de ponta, manteve a relação entre vistas mais consistente e reduziu uma medida-chave de instabilidade de treinamento em mais da metade.
O que isso significa para sistemas de IA no mundo real
Para não especialistas, a mensagem principal é que a UMDA oferece um caminho para construir modelos de IA únicos capazes de lidar de forma mais confiável com múltiplos tipos de dado e objetivos. Ao ensinar o modelo quando compartilhar informação e quando mantê‑la separada, e ao permitir que ele ajuste automaticamente como aprende, a arquitetura entrega previsões melhores, representações internas mais coerentes e um treinamento mais suave. Isso a torna um componente promissor para sistemas futuros em medicina, direção autônoma e outras aplicações complexas onde a IA precisa interpretar muitos sinais ao mesmo tempo sem perder o equilíbrio.
Citação: Mahmood, K., Althobaiti, M.M., Hassan, M.U. et al. Multitask optimization and convergence stability with hierarchical feature learning for self guided optimization. Sci Rep 16, 6414 (2026). https://doi.org/10.1038/s41598-026-36622-y
Palavras-chave: aprendizado multitarefa, IA multimodal, estabilidade do deep learning, redes de atenção, redes neurais gráficas