Clear Sky Science · pt
Previsão aprimorada de partidas de críquete usando métodos de kernel para extração de características e redes neurais de retropropagação
Previsões mais inteligentes para fãs de críquete
Os amantes do críquete conhecem a emoção de tentar adivinhar quem vai vencer enquanto a partida oscila. Este estudo transforma essa intuição em números ao usar ferramentas de dados modernas para prever o resultado de partidas One Day International (ODI) bola a bola. Em vez de esperar até o fim, o sistema atualiza sua estimativa a cada over, oferecendo uma previsão em andamento das chances de cada equipe conforme o jogo se desenrola.
Lendo a partida como um especialista em dados
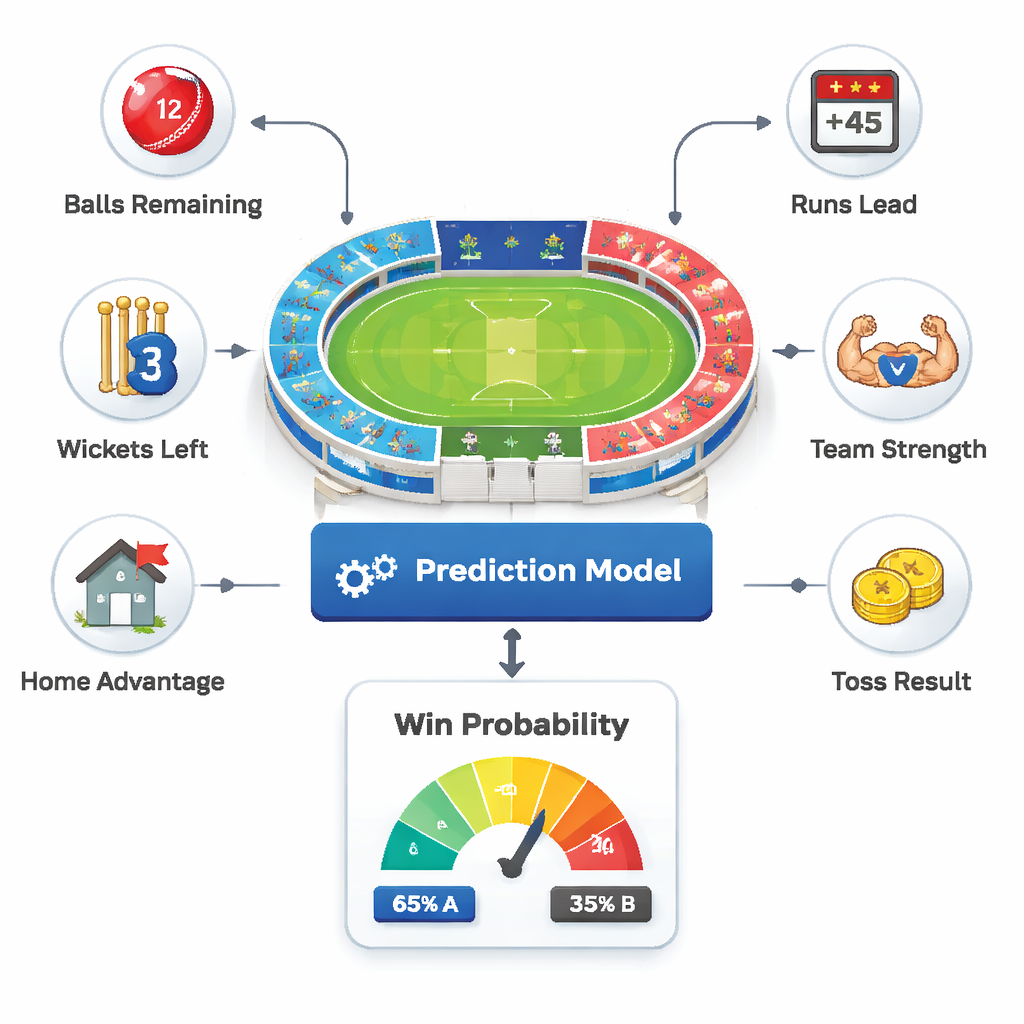
No cerne do trabalho está uma ideia simples: cada over representa um instantâneo da partida. Os autores tratam cada um desses instantâneos como um estado de jogo separado e perguntam: “Dado o que sabemos agora, qual a probabilidade do Time B vencer?” Para responder, eles alimentam seis tipos de informação em um sistema de previsão: quantas bolas restam, por quantas corridas o Time A está à frente, quantas wickets permanecem, quão fortes são as equipes no geral, se o público local favorece um dos lados e quem ganhou o sorteio. Ao combinar essas peças, o sistema capta tanto a pressão do placar quanto o contexto mais amplo sobre o qual os comentaristas costumam falar.
Construindo pontuações de força a partir de um século de partidas
O modelo é treinado em uma vasta coleção de dados internacionais de críquete que se estende desde 1877 e cobre os formatos ODI, Test e T20. Para cada jogador, os pesquisadores coletam registros de batting, bowling e fielding, como médias, strike rates e economy rates. Esses dados são combinados em uma pontuação de “força da equipe” que reflete o quão poderosa uma equipe é no papel antes de uma bola ser lançada. Durante a partida, essa força de longo prazo é mesclada com condições de curto prazo, como vantagem em casa e a situação atual da perseguição, produzindo cerca de 100.000 registros de estado de jogo cuidadosamente limpos para o sistema de aprendizado estudar.
Deixando os algoritmos escolherem as pistas mais reveladoras
Nem toda estatística ajuda o computador a tomar decisões melhores, e incluir muitas pode, na verdade, confundi‑lo. Para enfrentar isso, os autores usam um método de busca inspirado em ligas esportivas, chamado League Championship Algorithm. Nessa abordagem, muitos subconjuntos diferentes de características “competem” entre si. Os subconjuntos que levam a previsões melhores são tratados como equipes vencedoras, e os mais fracos copiam partes de sua estratégia. Ao longo de muitas rodadas, esse processo converge para um pequeno conjunto de entradas especialmente úteis. Testes mostram que esse método de seleção supera técnicas mais comuns, levando a maior precisão e a um modelo mais simples e eficiente.
Como a rede neural aprende a apontar um vencedor
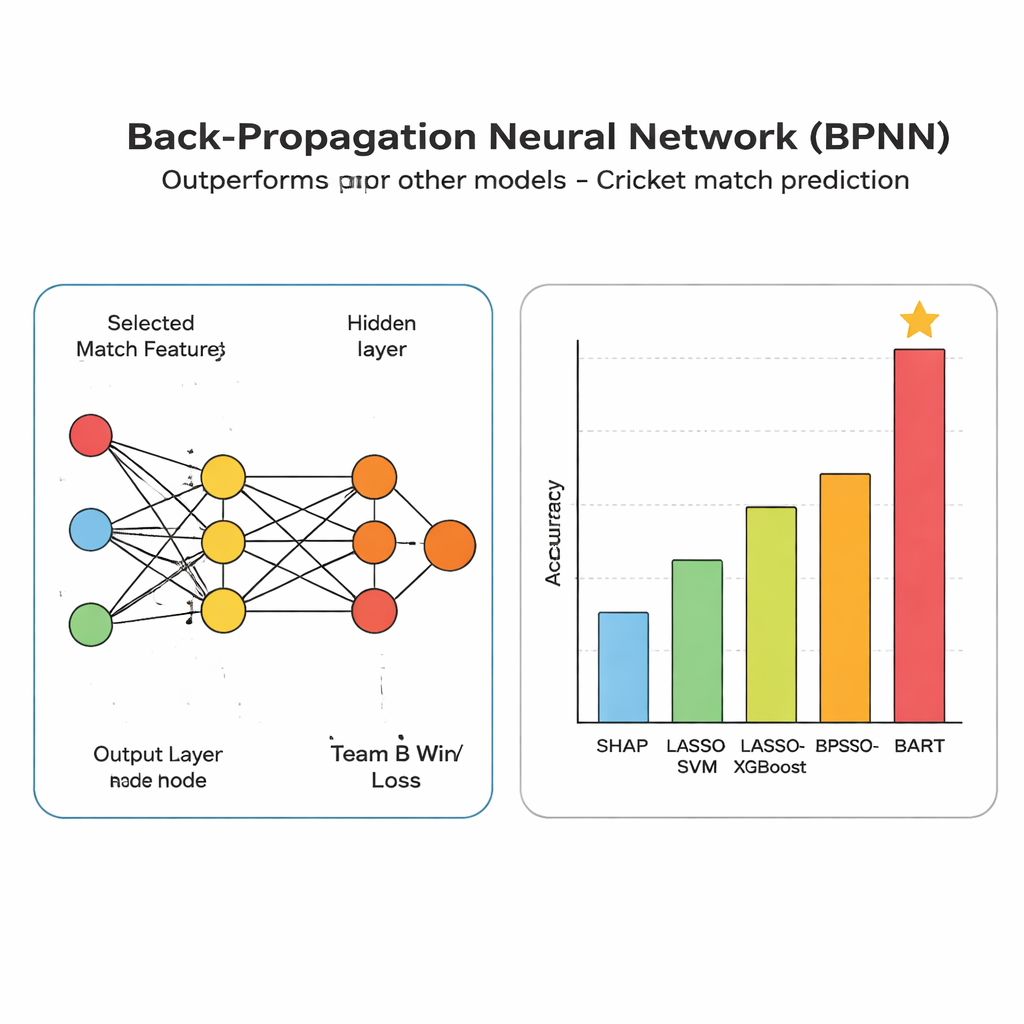
Uma vez escolhidas as melhores características, elas são enviadas para uma rede neural de retropropagação, uma ferramenta flexível de reconhecimento de padrões que ajusta pesos internos até conseguir ligar estados de jogo a resultados de forma confiável. Cada over torna‑se um exemplo de treinamento: a entrada são os seis critérios-chave e a saída é se o Time B acabou vencendo ou perdendo. Ao comparar repetidamente suas estimativas com os resultados reais e ajustando seus parâmetros internos para reduzir erros, a rede aprende gradualmente combinações sutis de condições — como um time de perseguição forte com wickets em mãos e vantagem em casa — que tipicamente levam à vitória.
Superando modelos rivais em diversos formatos
Os autores confrontam sua rede com várias abordagens rivais, incluindo modelos que dependem de características escolhidas manualmente e métodos baseados em árvores amplamente usados em análises esportivas. Em dados de ODI, Test e T20, seu sistema oferece maior precisão, com pontuações em conjuntos de teste na faixa média de 80% e desempenho mais forte em medidas que capturam tanto com que frequência identifica um provável vencedor quanto com que frequência essas previsões positivas estão corretas. Os fatores mais influentes mostram‑se ser estatísticas relacionadas a pontuação, como strike rate e corridas totais, ecoando a intuição de um torcedor de que batedores rápidos e consistentes podem inclinar partidas equilibradas.
O que isso significa para fãs, equipes e emissoras
Para o leitor em geral, a conclusão é que o vai e vem de uma partida de críquete agora pode ser traduzido em probabilidades de vitória precisas e atualizadas regularmente. Ao misturar registros de longo prazo dos jogadores, condições imediatas de jogo e um sistema de aprendizado cuidadosamente ajustado, o estudo mostra que podemos prever resultados com notável confiabilidade enquanto o jogo ainda está em andamento. Tais ferramentas podem apoiar comentários ao vivo, decisões de técnico e até aplicativos para espectadores que mostram como cada bola altera as probabilidades. Em termos simples, a pesquisa demonstra que quando as ricas estatísticas do críquete são combinadas com algoritmos inteligentes, nosso senso intuitivo de “quem está por cima” pode ser convertido em uma imagem clara e orientada por dados.
Citação: Dhinakaran, K., Anbuchelian, S. Enhanced cricket match prediction using kernel methods for feature extraction and back-propagation neural networks. Sci Rep 16, 6478 (2026). https://doi.org/10.1038/s41598-026-36555-6
Palavras-chave: análise de críquete, previsão esportiva, aprendizado de máquina, redes neurais, previsão de partidas