Clear Sky Science · pt
Um modelo híbrido ResNet50-vision transformer com um mecanismo de atenção para classificação de imagens aéreas
Por que olhos mais inteligentes no céu são importantes
Fotos aéreas de drones e satélites agora orientam respostas a desastres, planejamento urbano, agricultura e até controle de tráfego. Mas ensinar computadores a compreender essas vistas complexas e cheias de ruído do alto ainda é difícil. Este estudo apresenta dois novos modelos de inteligência artificial que combinam diferentes maneiras de “ver” imagens para reconhecer dez tipos de objetos em fotos de drones — como edifícios, carros, árvores e estradas — com maior precisão do que métodos anteriores. A abordagem deles pode tornar o monitoramento automatizado a partir do ar mais rápido, mais confiável e mais fácil de implantar em cenários reais.
Desafios de olhar para baixo no mundo
Imagens aéreas diferem das fotos cotidianas que tiramos com nossos celulares. Objetos são menores, podem aparecer em ângulos estranhos e frequentemente ficam muito próximos uns dos outros. Um carro parcialmente escondido por uma árvore, uma trilha estreita ou montes de detritos após um deslizamento podem ser difíceis até para humanos identificarem rapidamente. Ainda assim, governos, equipes de emergência e agências ambientais dependem cada vez mais de visões por drone e satélite para rastrear inundações, incêndios florestais, crescimento urbano e danos a infraestrutura. Com milhares de satélites em órbita e um mercado de imagens aéreas em expansão, o volume de dados cresce rápido demais para a inspeção manual, aumentando a necessidade de classificação automatizada mais precisa e eficiente.
Unindo duas formas de aprendizado visual das máquinas
A maioria dos sistemas de reconhecimento de imagens bem-sucedidos hoje se baseia em aprendizado profundo. Uma família, as redes neurais convolucionais, é excelente em identificar padrões locais como contornos, texturas e pequenas formas. Outra família, mais recente, chamada vision transformer trata a imagem como uma sequência de patches e é especialmente boa em capturar relações de longo alcance — por exemplo, como uma estrada, um conjunto de telhados e um campo aberto próximo se relacionam na cena. Este trabalho combina ambos: um modelo convolucional conhecido, o ResNet-50, e um vision transformer. Cada um processa a mesma imagem aérea e extrai seu próprio conjunto de características numéricas — resumos compactos do que a rede aprendeu sobre a cena. Essas duas correntes de informação são então unidas e passadas para um módulo de “atenção” que aprende quais características importam mais para decidir entre as dez classes-alvo.
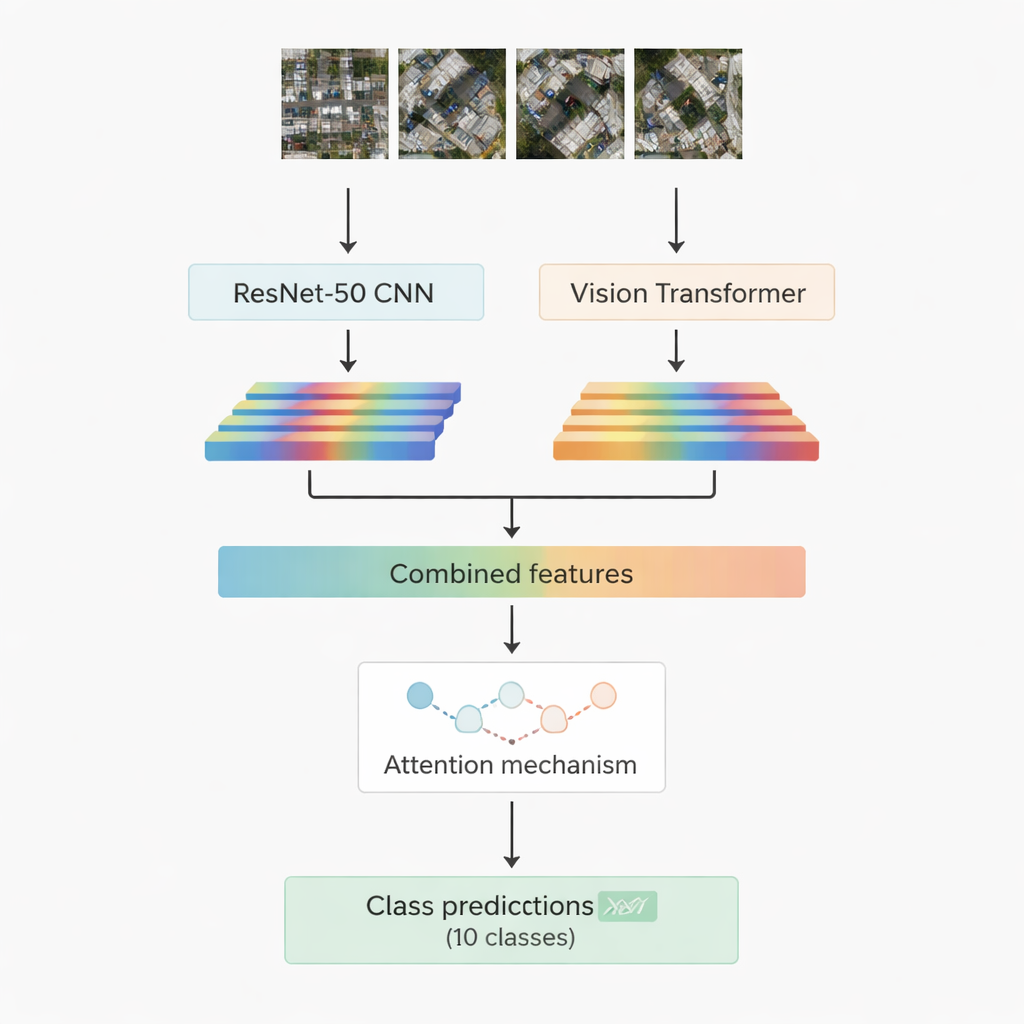
Duas estratégias de atenção para focar no que importa
Os pesquisadores projetam e testam duas versões do sistema híbrido. Na primeira, eles simplesmente juntam as características do ResNet-50 e do transformer e as alimentam em um módulo de atenção multi-cabeça. Esse mecanismo pode ser pensado como várias pequenas lanternas que observam as características de ângulos ligeiramente diferentes e depois combinam suas descobertas. Na segunda versão, usam cross-attention: as características da rede convolucional atuam como uma consulta que pergunta às características do transformer onde olhar, permitindo que uma corrente guie a outra. Em ambos os casos, a saída de atenção é passada por camadas padrão que finalmente atribuem o patch de imagem a uma das dez classes, incluindo edifícios, carros, detritos, trilhas, estradas de metal, campos abertos, sombras, tanques, árvores e telhados.
Testes em imagens reais de drones
Para avaliar o desempenho de seus modelos, os autores usam um conjunto de dados público do estado indiano de Sikkim, coletado por um drone voando a 60 a 120 metros do solo. Os dados cobrem rios, florestas, colinas e áreas construídas, fatiados em pequenos patches para que cada imagem caia em uma das dez categorias. O conjunto é balanceado, com número igual de imagens de treinamento e teste por classe, tornando-o um campo de provas justo. Os pesquisadores treinam ambos os modelos híbridos sob condições idênticas e então comparam o desempenho usando métricas amplamente utilizadas: acurácia, precisão, recall, F1-score, matrizes de confusão e curvas ROC. Eles também comparam seus resultados com várias redes bem conhecidas e métodos baseados em transformer mais recentes da literatura.

Classificação mais precisa e potencial no mundo real
Ambos os modelos híbridos superam sistemas anteriores neste conjunto de dados, alcançando acurácias gerais de 95,52% e 95,80%, com a versão de atenção multi-cabeça ligeiramente à frente. O desempenho se mantém forte e estável em todas as dez categorias de objeto, e análises detalhadas mostram que mesmo as classes mais fracas ainda são reconhecidas em altas taxas. Isso sugere que misturar redes convolucionais, vision transformers e mecanismos de atenção é uma receita poderosa para compreender cenas aéreas complexas. Para um leitor leigo, a conclusão é que os computadores estão cada vez melhores em responder perguntas como “Onde estão as estradas?” ou “Quais áreas mostram detritos ou edifícios?” em coleções enormes de imagens de drones. À medida que esses modelos são refinados e estendidos para novos conjuntos de dados, eles podem sustentar respostas a desastres mais inteligentes, monitoramento ambiental e serviços de cidades inteligentes que dependem de interpretação rápida e confiável de imagens do alto.
Citação: Aboghanem, A., Abd Elfattah, M., M. Amer, H. et al. A hybrid ResNet50-vision transformer model with an attention mechanism for aerial image classification. Sci Rep 16, 5940 (2026). https://doi.org/10.1038/s41598-026-36492-4
Palavras-chave: classificação de imagens aéreas, imagens de drone, aprendizado profundo, vision transformer, sensoriamento remoto