Clear Sky Science · pt
Análise de desempenho de rede dependente de longo prazo em cascata embaralhada com atenção otimizada para e-learning adaptativo entre profissionais de TI
Treinamento online mais inteligente para profissionais de tecnologia
Para muitos profissionais de tecnologia da informação (TI), cursos online tornaram-se a principal forma de manter as habilidades atualizadas. Mas a maioria das plataformas de treinamento ainda avalia as pessoas com ferramentas rudimentares, como totais de questionários ou distintivos de conclusão. Este estudo apresenta uma maneira mais inteligente de ler as “pegadas” digitais que os aprendizes deixam e transformá‑las em insights precisos e em tempo real sobre o quanto cada pessoa está realmente aprendendo.
Por que cursos online “tamanho único” não dão conta
O e-learning convencional trata a maioria dos aprendizes de forma idêntica: todos veem os mesmos módulos, fazem os mesmos questionários e são julgados por testes fixos iguais. Essa abordagem ignora as diferenças no ritmo de progresso, especialmente em áreas que mudam rapidamente, como segurança cibernética ou computação em nuvem. Pesquisas anteriores tentaram corrigir isso com aprendizado de máquina — combinando notas de questionários, tempo gasto e dados de cliques para prever o sucesso —, mas muitos modelos tiveram problemas com dados ruidosos ou incompletos, não conseguiram escalar para plataformas realistas ou falharam em acompanhar como a aprendizagem evolui ao longo de semanas e meses. O resultado frequentemente foi um feedback tardio e grosseiro que não orientava facilmente conteúdos personalizados ou intervenções oportunas.
Transformando logs brutos de cursos em dados limpos e justos
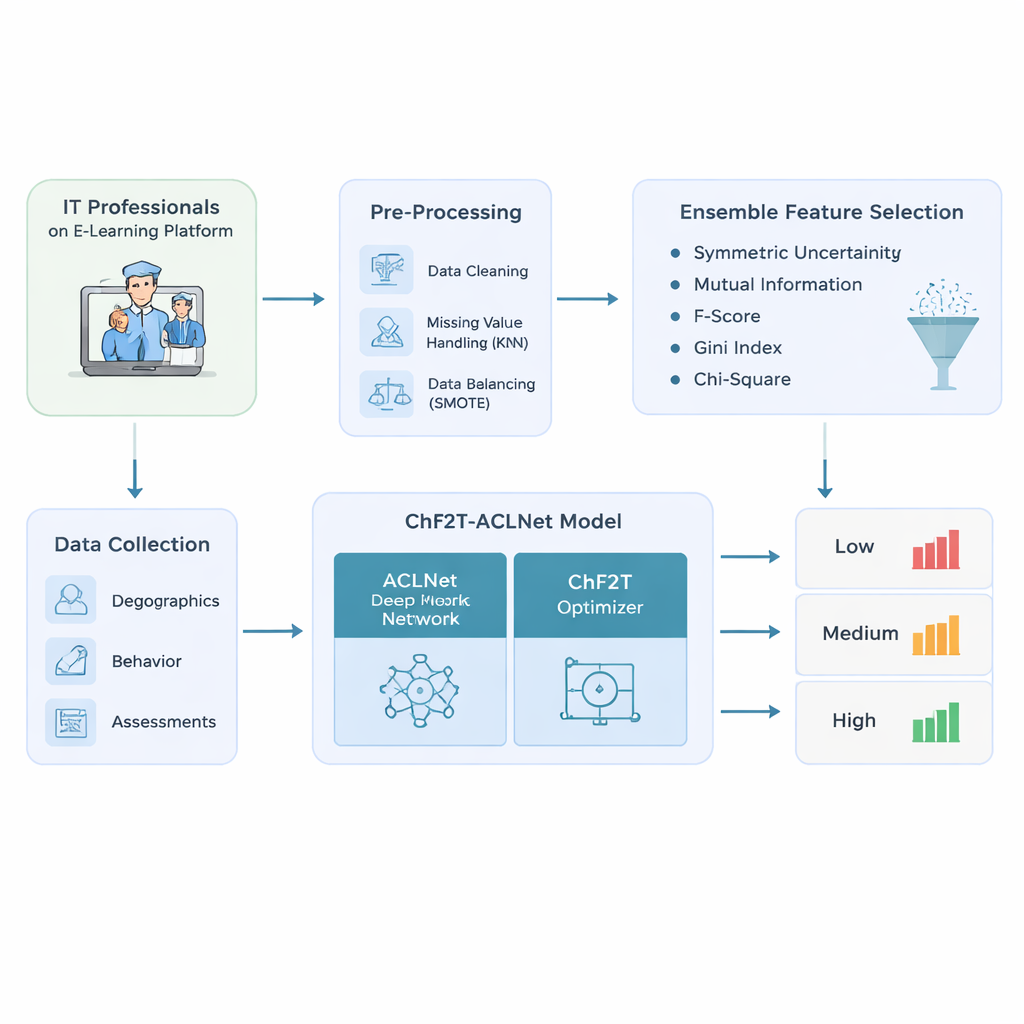
Os autores começam projetando um pipeline de dados cuidadoso para profissionais de TI que usam plataformas de e-learning adaptativo. Eles reúnem uma mistura rica de informações: dados de perfil básicos, como idade e função; rastros comportamentais como tempo gasto, datas de acesso e dias ativos; e indicadores de desempenho, incluindo notas de questionários, tentativas, certificados e avaliações de feedback. Antes de qualquer modelagem, limpam os dados — removendo registros duplicados, estimando valores ausentes com base em aprendizes semelhantes e corrigindo distribuições de classes enviesadas para que baixos, médios e altos desempenhos estejam mais bem representados. Essa etapa de balanceamento evita modelos excessivamente confiantes apenas em relação aos aprendizes “médios” mais comuns e cegos quanto àqueles que têm dificuldades ou se destacam.
Selecionando apenas os sinais mais reveladores
Do conjunto de dados limpo, o sistema não alimenta simplesmente todas as colunas disponíveis em uma caixa‑preta. Em vez disso, usa um conjunto de cinco métodos simples de ranqueamento para decidir quais recursos realmente importam para prever resultados de aprendizagem. Cada método examina a conexão entre um recurso candidato — como tentativas de questionário ou tempo gasto — e o rótulo final de desempenho. Ao combinar seus rankings por uma pontuação mediana, a abordagem filtra sinais ruidosos ou redundantes e mantém somente os mais informativos. Isso não apenas reduz a quantidade de computação necessária pelo modelo posterior, como também o ajuda a focar em padrões que distinguem de forma significativa os aprendizes de baixo, médio e alto desempenho.
Uma rede híbrida treinada como um time esportivo
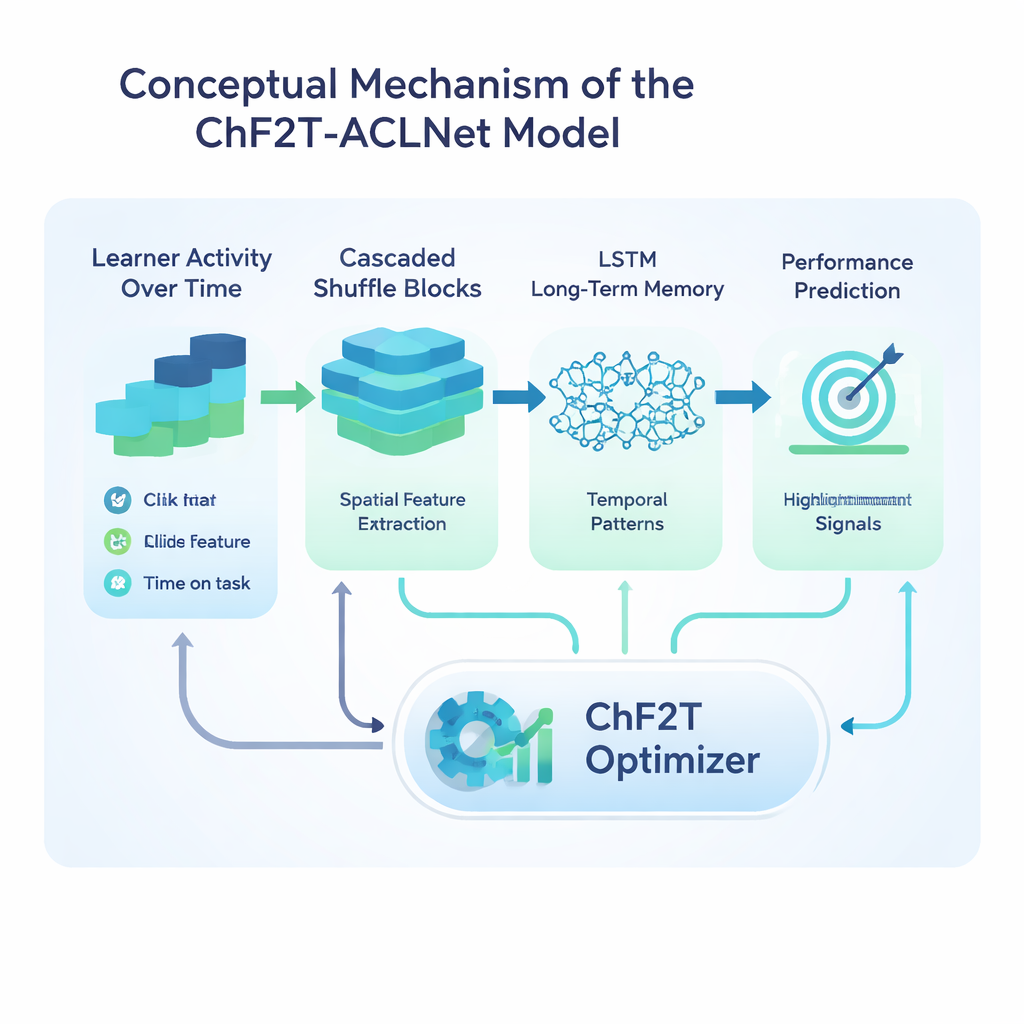
O cerne do estudo é um modelo híbrido de aprendizado profundo chamado ACLNet, acompanhado de uma estratégia de treinamento não convencional inspirada por esportes coletivos. O ACLNet primeiro usa blocos leves de “embaralhamento” para compactar e misturar os sinais de entrada de forma eficiente, depois os passa para um módulo de memória que traça como o comportamento do aprendiz muda ao longo do tempo. Uma camada de atenção no topo destaca os canais mais influentes — como quedas repentinas de atividade ou notas de questionários consistentemente altas — antes de fazer a previsão final da classe de desempenho do aprendiz. Para ajustar as muitas configurações internas dessa rede, os autores introduzem um algoritmo Chaotic Football Team Training (ChF2T). Nesse cenário, “jogadores” virtuais exploram diferentes configurações de parâmetros, imitando bons desempenhos, evitando os fracos e ocasionalmente fazendo grandes saltos caóticos que ajudam a busca a escapar de escolhas locais ruins. Essa mistura de estrutura e aleatoriedade controlada acelera a convergência e reduz overfitting.
Como o sistema se sai na prática
Os pesquisadores testam o pipeline em um conjunto de dados sintético porém realista com 1.200 profissionais de TI, construído para espelhar registros de sistemas de gestão de aprendizagem com distribuições de classes deliberadamente desiguais. Eles comparam seu modelo ChF2T‑ACLNet com vários fortes baselines, incluindo configurações de aprendizado federado, redes avançadas de estilo de imagem adaptadas à educação e outros modelos profundos ou em conjunto. Em múltiplas configurações de validação cruzada, o método proposto alcança cerca de 98,9% de acurácia, com precisão, recall e F‑scores igualmente altos. Também atinge uma concordância quase perfeita ajustada ao acaso e apresenta fortes valores de área sob a curva, o que significa que separa níveis de desempenho de forma confiável em muitos limiares. Apesar da complexidade, o sistema roda mais rápido que abordagens concorrentes, graças à seleção criteriosa de recursos, ao projeto eficiente da rede e à rápida convergência do otimizador.
O que isso significa para o aprendizado online do dia a dia
Em termos simples, este trabalho mostra que é possível observar como profissionais percorrem cursos online e inferir, com alta confiança, quem está com dificuldades, quem está apenas mantendo e quem está dominando o conteúdo — sem esperar por um exame final. Tal sistema poderia disparar dicas precoces, recomendar exercícios diferentes ou alertar mentores muito antes de um aprendiz ficar para trás. Os autores apontam desafios remanescentes, incluindo escalar para plataformas muito grandes, adaptar‑se a designs de curso que mudam rapidamente e tornar as decisões do modelo mais fáceis de explicar. Ainda assim, a abordagem representa um avanço importante rumo a sistemas de e‑learning que agem mais como treinadores pessoais atentos do que como livros didáticos digitais estáticos.
Citação: Yuvapriya, P., Subramanian, P. & Surendran, R. Optimized attention-based cascaded shuffle long-term dependent network based performance analysis of adaptive e-learning among IT professionals. Sci Rep 16, 6245 (2026). https://doi.org/10.1038/s41598-026-36470-w
Palavras-chave: e-learning adaptativo, análise de aprendizagem, aprendizado profundo, treinamento de profissionais de TI, predição de desempenho estudantil