Clear Sky Science · pt
Um método de desambiguação de entidades em textos curtos baseado no modelo BERT e no algoritmo do caminho mais curto
Por que esclarecer nomes ambíguos importa
Todos os dias pesquisamos, rolamos e conversamos usando trechos curtos e frequentemente confusos de texto — tuítes, consultas de busca, mensagens de chat. Esses trechos estão cheios de nomes de pessoas, lugares, empresas e coisas que podem ter mais de um sentido, como “Apple” a fruta ou “Apple” a empresa. Os computadores precisam adivinhar qual sentido pretendemos, e quando erram, os resultados de busca, as recomendações e os serviços online ficam muito menos úteis. Este artigo apresenta uma nova forma de ajudar as máquinas a interpretar corretamente nomes ambíguos em textos curtos, especialmente em mídias sociais e buscas em chinês, combinando modelos de linguagem modernos com um algoritmo gráfico eficaz.
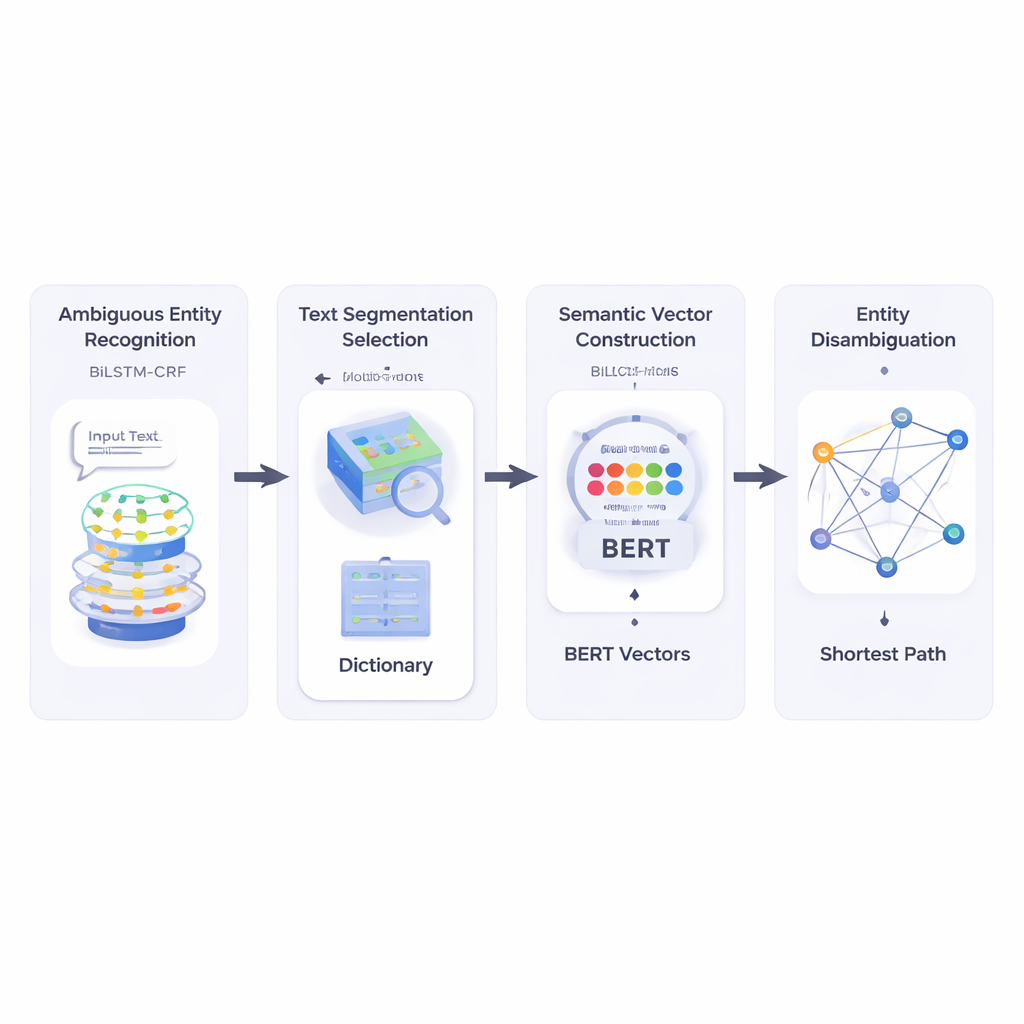
De textos curtos e confusos a alvos claros
Textos curtos são surpreendentemente difíceis para computadores entenderem. Ao contrário de artigos longos, eles trazem muito pouco contexto e estão cheios de gírias, abreviações e frases incompletas. Métodos tradicionais tentavam casar um nome do texto com entradas de uma base de conhecimento ou usavam regras manuais e modelos de aprendizado de máquina mais simples. Essas abordagens frequentemente tratam cada palavra como tendo um único significado fixo, o que falha quando a mesma palavra pode representar um cargo, uma empresa ou uma música, dependendo do uso. O resultado é confusão frequente sobre qual entidade do mundo real uma palavra em um tuíte ou consulta realmente refere.
Ensinando o sistema a identificar nomes ambíguos
Os autores primeiro constroem um sistema que lê um texto curto e identifica quais trechos são nomes de entidade e quais deles podem ser ambíguos. Eles usam uma combinação de rede neural chamada BiLSTM‑CRF, que é boa para rotular sequências de palavras observando tanto o contexto à esquerda quanto à direita. Uma vez marcadas as entidades potenciais, o sistema consulta um grande recurso lexicográfico chamado HowNet. Se o HowNet lista vários sentidos para uma palavra, essa palavra é sinalizada como ambígua; se há apenas um sentido, a palavra é tratada como já clara. Essa etapa fornece ao sistema uma lista focada de nomes que realmente precisam de desambiguação.
Transformando significados em pontos no espaço
Em seguida, o método divide o texto curto em segmentos de palavras candidatos e escolhe a melhor segmentação verificando quão bem cada corte possível se alinha, em termos de significado, com palavras de referência claramente entendidas na mesma frase. Para medir isso, os autores recorrem ao BERT, um poderoso modelo de linguagem pré‑treinado que produz um “vetor semântico” numérico para cada ocorrência de palavra, capturando seu significado dependente do contexto. Calculando a similaridade por cosseno entre esses vetores, o sistema encontra a segmentação cujas partes são mais semanticamente compatíveis com os termos de referência não ambíguos. Isso permite ao modelo representar cada possível sentido de cada palavra como um ponto em um espaço multidimensional.
Encontrando a rota mais curta para o sentido certo
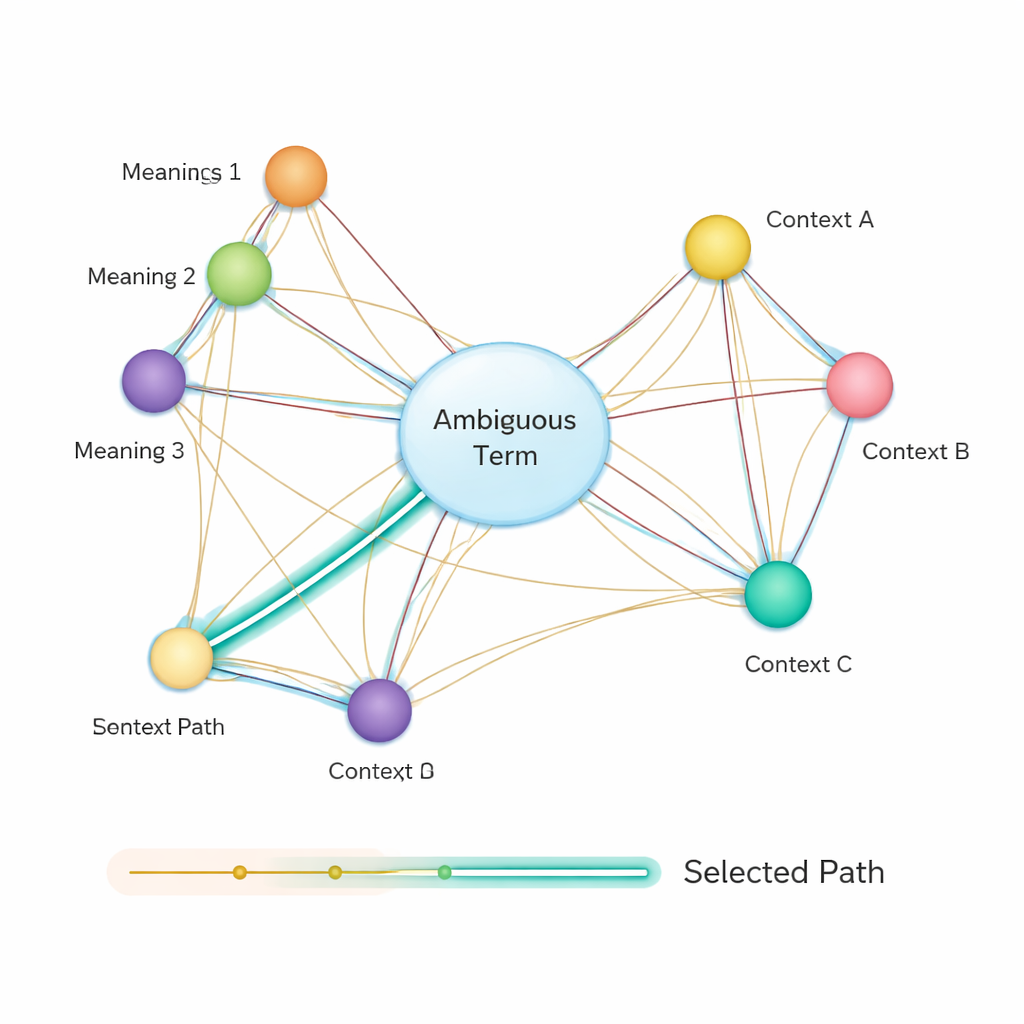
Depois disso, o método constrói uma rede semântica: um grafo onde cada possível sentido de cada termo é um nó, e arestas conectam sentidos que podem coocorrer na mesma frase. A força de cada aresta é baseada em quão semelhantes são os sentidos, novamente usando vetores derivados do BERT. Para decidir qual sentido de uma palavra ambígua melhor se encaixa na frase, os autores aplicam um algoritmo clássico conhecido como algoritmo do caminho mais curto de Dijkstra. Intuitivamente, o sistema procura o caminho através desse grafo de sentidos que mantém a “distância” semântica total o menor possível. O caminho escolhido corresponde a uma interpretação consistente de todos os termos, e o sentido da entidade ambígua que está nesse caminho é selecionado como resposta final.
Quanto melhor isso funciona?
Os pesquisadores testaram seu método em um conjunto de dados chinês público do benchmark CLUE, que simula cenários reais de textos curtos como posts em redes sociais e consultas. Eles compararam quatro abordagens: versões usando embeddings Word2Vec tradicionais, o modelo de linguagem ELMo, um sistema baseado em BERT sem a etapa do caminho mais curto, e seu pipeline completo BiLSTM‑CRF‑BERT‑SPA. Ao longo de milhares de textos, o método completo melhorou precisão, recall e F1 em aproximadamente um quarto em média em comparação com os demais. Em termos práticos, o sistema foi tanto melhor em identificar as entidades corretas quanto em fazê‑lo de modo consistente em diferentes volumes de dados.
O que isso significa para a tecnologia do dia a dia
Para não especialistas, a conclusão é direta: ao combinar um poderoso modelo de entendimento de linguagem (BERT) com uma busca em grafo baseada no caminho mais curto, os autores dão às máquinas uma forma mais confiável de decidir a que um nome ambíguo realmente se refere em textos curtos e ruidosos. Isso pode tornar motores de busca mais inteligentes, ajudar plataformas sociais a entender melhor publicações e melhorar ferramentas a jusante, como sistemas de recomendação e grafos de conhecimento. Embora o método esteja atualmente orientado ao chinês e ainda possa evoluir em termos de eficiência, ele demonstra como a mistura de IA moderna com algoritmos clássicos pode reduzir de forma significativa a confusão na interpretação que as máquinas fazem da nossa linguagem cotidiana.
Citação: Liu, X., Zhang, D., Xiao, T. et al. A short text entity disambiguation method based on BERT model and shortest path algorithm. Sci Rep 16, 5720 (2026). https://doi.org/10.1038/s41598-026-36411-7
Palavras-chave: desambiguação de entidades, texto curto, BERT, grafo de conhecimento, processamento de linguagem natural