Clear Sky Science · pt
Estrutura de aprendizado por reforço para testes adaptativos computadorizados usando abordagem multi-armed bandit
Testes mais inteligentes para a sala de aula digital
Quem já passou por um exame longo e único para todos sabe o quanto ele pode parecer entediante e injusto. Algumas questões são fáceis demais, outras impossivelmente difíceis, e a nota final pode não refletir o que você realmente sabe. Este artigo apresenta uma nova maneira de construir testes em computador que se adaptam, em tempo real, às respostas de cada pessoa. Ao emprestar ideias da inteligência artificial moderna, os autores buscam tornar os exames mais curtos, mais precisos e mais alinhados à habilidade real de cada testando.
Por que testes fixos ficam aquém
Exames tradicionais aplicam a mesma coleção de questões a todos os alunos. Isso facilita a criação do teste, mas desperdiça informação: alunos fortes passam por muitas questões fáceis, enquanto alunos com dificuldades são rapidamente sobrecarregados. O teste adaptativo computadorizado tenta corrigir isso escolhendo cada próxima questão com base nas respostas anteriores, mas a maioria dos sistemas atuais ainda se apoia em modelos estatísticos antigos e regras manualmente elaboradas. Essas abordagens têm dificuldade para capturar padrões complexos de resposta e muitas vezes não conseguem levar totalmente em conta as grandes diferenças entre aprendizes em contextos online em larga escala.
Introduzindo IA moderna nos testes
Os autores propõem uma nova estrutura que combina aprendizado profundo e aprendizado por reforço para conduzir exames adaptativos do início ao fim. O sistema opera em ciclos repetidos. Primeiro, uma rede neural convolucional unidimensional (1D-CNN) analisa as respostas recentes de uma pessoa, a dificuldade das questões e outras estatísticas resumidas. A partir desse fluxo de dados, ela produz um único número que representa o nível de habilidade atual da pessoa em uma escala normalizada, semelhante à forma como teorias tradicionais de teste descrevem a habilidade, mas aprendida diretamente a partir dos dados. Essa rede é treinada para reconhecer padrões sutis, como sucesso consistente em questões mais difíceis ou erros inesperados em questões mais fáceis. 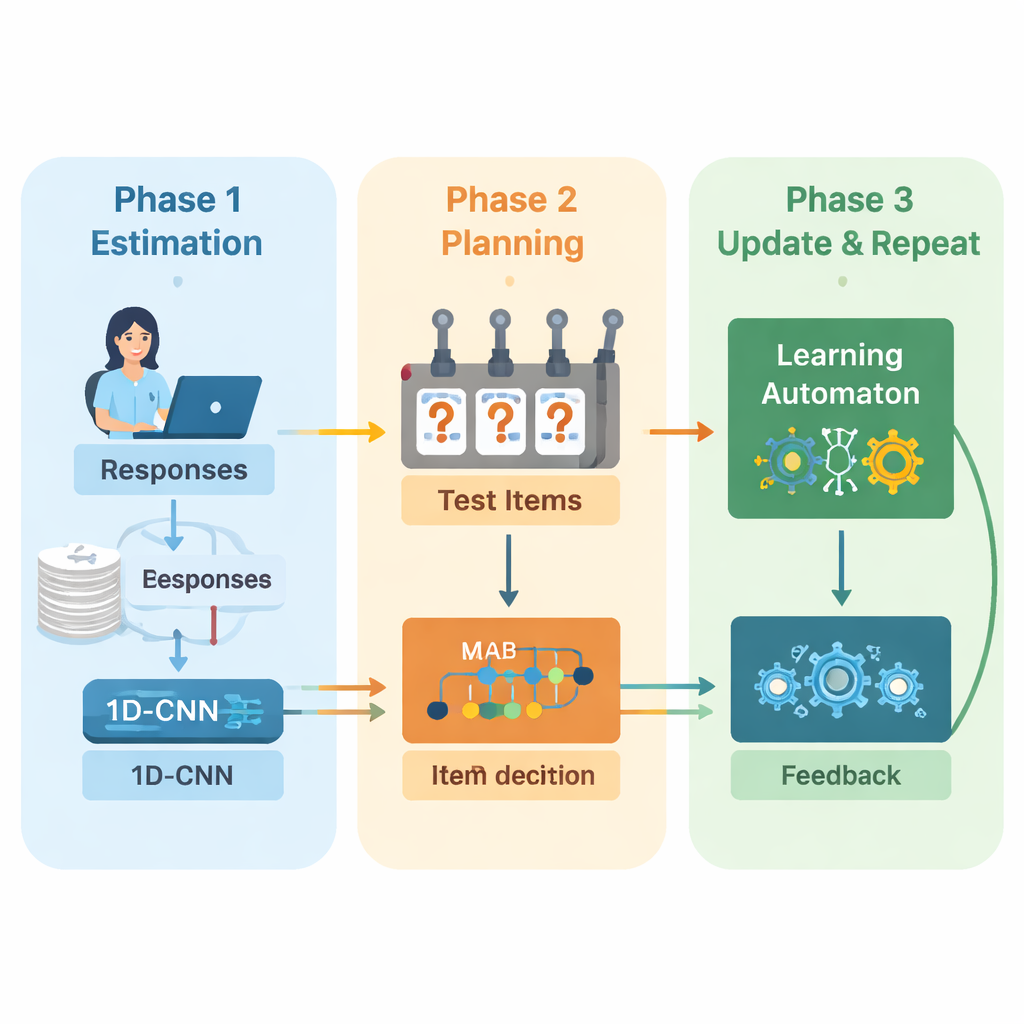
Escolhendo a próxima questão certa
Uma vez que o sistema tem uma estimativa atualizada da habilidade, ele precisa decidir o que perguntar a seguir. Aqui os autores usam uma estratégia de "multi-armed bandit", uma ferramenta clássica da teoria de decisão em que cada ação possível é tratada como acionar uma alavanca em uma máquina caça‑níqueis. Nesse contexto, cada questão no banco de itens é um braço. O algoritmo observa questões cuja dificuldade aproximadamente corresponde à estimativa de habilidade atual e então escolhe aquelas que se espera serem mais informativas. Ele equilibra dois objetivos: conseguir uma boa correspondência de dificuldade, para que as respostas não sejam nem fáceis nem difíceis demais, e cobrir o máximo possível de áreas de conteúdo diferentes, para que o teste não ignore tópicos importantes. Uma pontuação de recompensa que combina esses dois objetivos guia o processo de seleção.
Aprendendo a partir de suas próprias decisões
Para continuar melhorando conforme o teste avança, o sistema adiciona outro componente de aprendizagem chamado autômato de aprendizagem. Esse módulo observa como a habilidade estimada muda ao longo das rodadas e se a acurácia da pessoa está melhorando ou piorando. Ele ajusta um pequeno conjunto de probabilidades que resumem se o modelo espera que a habilidade aumente, permaneça igual ou diminua. Essas probabilidades são então retroalimentadas como entrada adicional para a rede neural na rodada seguinte. Dessa forma, o motor do teste não apenas aprende sobre o aluno, mas também aprende sobre suas próprias decisões passadas—recompensando tendências que levaram a estimativas precisas e penalizando tendências que não o fizeram. 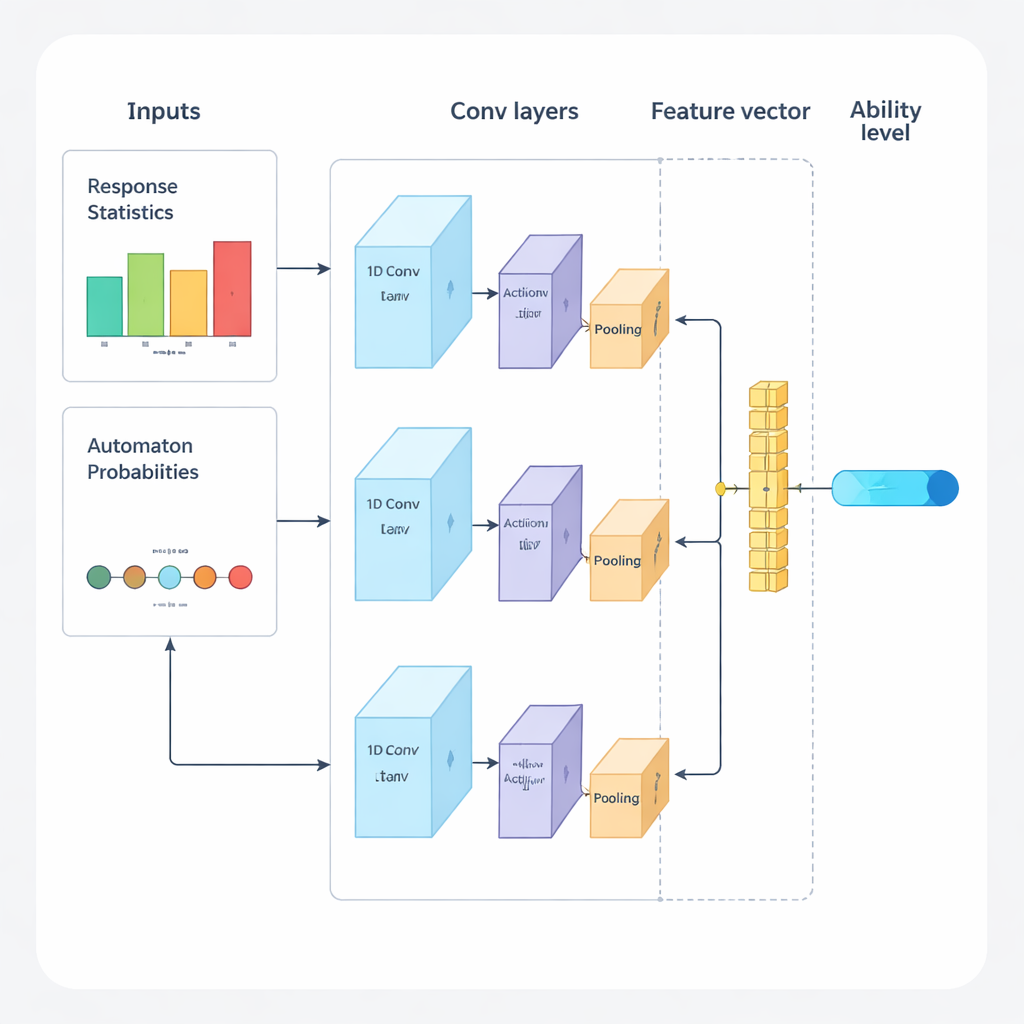
Qual o desempenho na prática?
Os pesquisadores avaliaram sua estrutura usando um grande conjunto de dados de exames multilíngues e milhares de testandos simulados cujos níveis reais de habilidade eram conhecidos. Eles compararam sua abordagem com vários métodos adaptativos de ponta. Em uma gama de medidas de erro e correlação, o novo sistema produziu estimativas de habilidade mais precisas enquanto exigia menos questões. Seus erros—medidos por estatísticas comuns como raiz do erro quadrático médio e erro absoluto médio—foram claramente menores do que os de métodos concorrentes. Ao mesmo tempo, o sistema distribuiu o uso das questões de forma mais uniforme pelo banco de itens, reduzindo o risco de que certas questões fossem excessivamente expostas e vazassem.
O que isso significa para exames futuros
Em termos práticos, este trabalho sugere que testes computadorizados futuros poderiam se assemelhar mais a uma sessão de tutoria personalizada do que a um exame rígido. As questões rapidamente se ajustariam à dificuldade certa para cada pessoa, cobririam toda a gama de tópicos relevantes e terminariam assim que o sistema tivesse confiança sobre seu nível—frequentemente com menos itens do que os testes atuais. Embora o método ainda dependa de bons dados de treinamento e poder computacional, e até agora tenha sido testado em um único conjunto de dados, ele aponta para uma nova geração de avaliações mais inteligentes, mais justas e mais eficientes que se adaptam naturalmente aos aprendizes individuais.
Citação: Tang, B., Li, S. & Zhao, C. Reinforcement learning framework for computerized adaptive testing using multi armed bandit approach. Sci Rep 16, 7441 (2026). https://doi.org/10.1038/s41598-026-36394-5
Palavras-chave: testes adaptativos computadorizados, avaliação educacional, aprendizado profundo, aprendizado por reforço, multi-armed bandit