Clear Sky Science · pt
Identificação de fatores de risco para instalações de diversão em grande escala usando mistura de especialistas e fusão de múltiplos modelos
Por que a segurança em parques temáticos precisa de leitura mais inteligente
Cada ano, centenas de milhões de pessoas sobem em montanhas-russas, torres de queda e brinquedos giratórios, confiando que máquinas complexas e operadores ocupados as manterão seguras. Nos bastidores, reguladores e engenheiros geram enormes volumes de relatórios, registros de acidentes e reclamações públicas—mas a maior parte dessa informação está em forma de texto, difícil de vasculhar rapidamente. Este estudo explora como a inteligência artificial avançada pode “ler” esses documentos em escala, identificar padrões de perigo mais cedo e oferecer às autoridades um panorama mais claro de onde os brinquedos de diversão têm maior probabilidade de falhar.
De relatórios dispersos a um quadro unificado de risco
A China agora abriga mais de 25.000 grandes brinquedos de diversão e mais de 700 milhões de visitantes por ano. Apesar das melhorias gerais na segurança, acidentes raros porém graves ainda ocorrem, muitas vezes após inspeções que não conseguiram notar sinais de alerta precoce enterrados em descrições técnicas ou reclamações de usuários. Os autores argumentam que a supervisão tradicional—baseada em checagens manuais periódicas, julgamento de especialistas e registros de manutenção—é lenta e subjetiva demais para um ambiente tão dinâmico. Eles reúnem uma grande coleção de textos do mundo real que inclui relatórios de acidentes, leis e normas, registros de inspeção e manutenção, e reclamações online relacionadas a instalações de diversão. Após limpeza e filtragem cuidadosas, esse corpus multifonte torna-se a matéria-prima para um sistema automatizado e orientado por dados de monitoramento de risco. 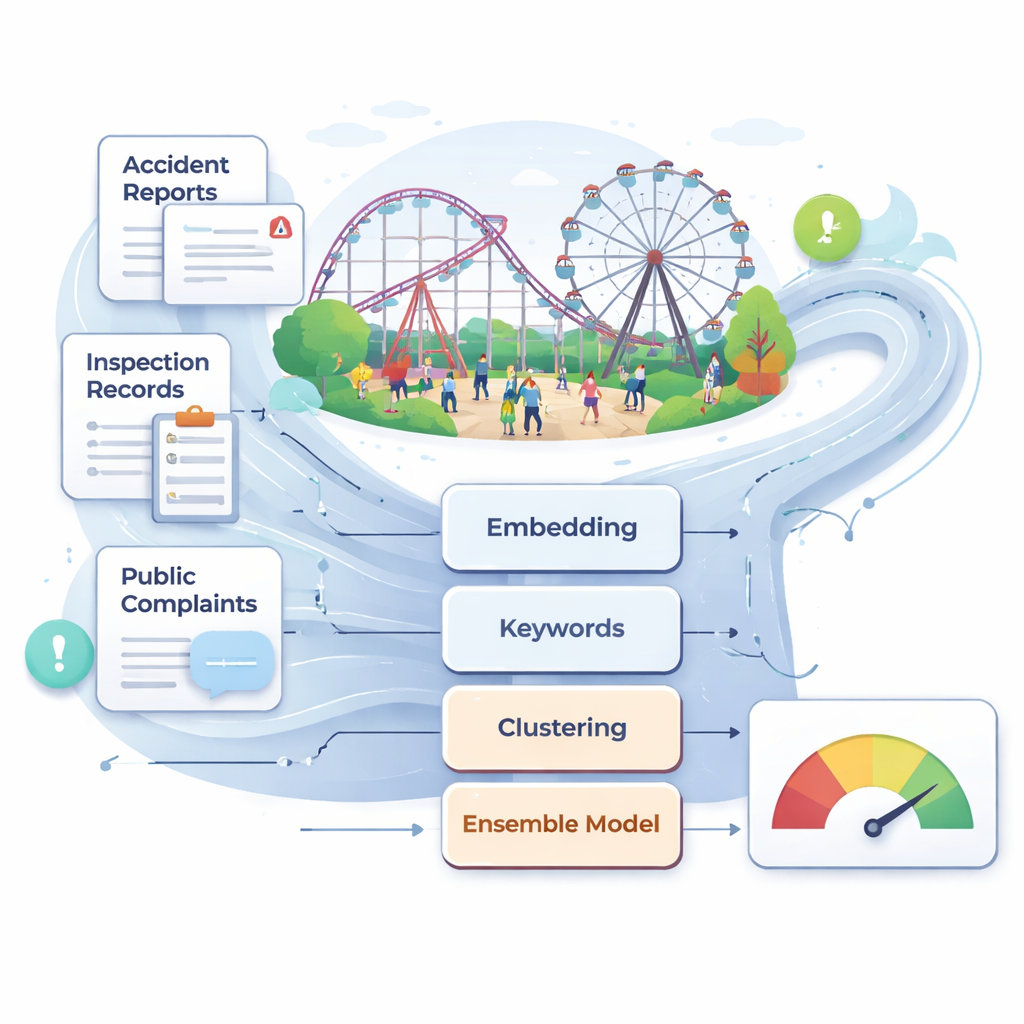
Ensinando computadores a entender a linguagem do risco
Para dar sentido a esses textos desordenados, os pesquisadores recorrem a modelos de linguagem modernos que convertem sentenças em vetores numéricos que capturam seu significado. Eles usam principalmente um modelo chinês chamado BGE, que representa cada trecho de texto como um ponto de 1.024 dimensões no espaço, além de um conjunto compacto de 30 características baseadas em palavras-chave focadas em termos como “manutenção”, “inspeção” e “retificação”. Essa visão dupla—contexto semântico profundo mais frases de risco selecionadas manualmente—ajuda o sistema a distinguir diferenças sutis entre, por exemplo, verificações de rotina e falhas graves. A equipe também experimenta outro modelo de embedding de ponta, o Qwen3, para testar se mudar a espinha dorsal linguística melhora o desempenho; na prática, o BGE mostra-se ligeiramente melhor nesta tarefa de segurança.
Encontrando padrões ocultos e pontos fracos chave
Antes de classificar textos em categorias concretas de risco, os autores usam métodos não supervisionados para descobrir agrupamentos naturais. Aplicam k-means aos embeddings e usam um método de visualização chamado UMAP para mostrar que os relatórios se distribuem em vários clusters temáticos claros. Em seguida, constroem um grafo semântico no qual cada nó é uma palavra-chave relacionada à segurança e os links indicam forte coocorrência e similaridade semântica. Um algoritmo de detecção de comunidades agrupa esses nós em clusters correspondentes a temas amplos, como segurança de equipamentos e estrutura, operação diária e manutenção, resposta a emergências e gestão e supervisão. Dentro dessa rede, certas palavras—como “manutenção”, “inspeção” e “responsabilidade”—atuam como pontes entre clusters, destacando fraquezas transversais que podem desencadear acidentes de várias maneiras. A partir dessa estrutura, extraem-se 31 fatores de risco centrais abrangendo quatro dimensões principais, desde monitoramento em tempo real de equipamentos até clareza das responsabilidades de trabalho. 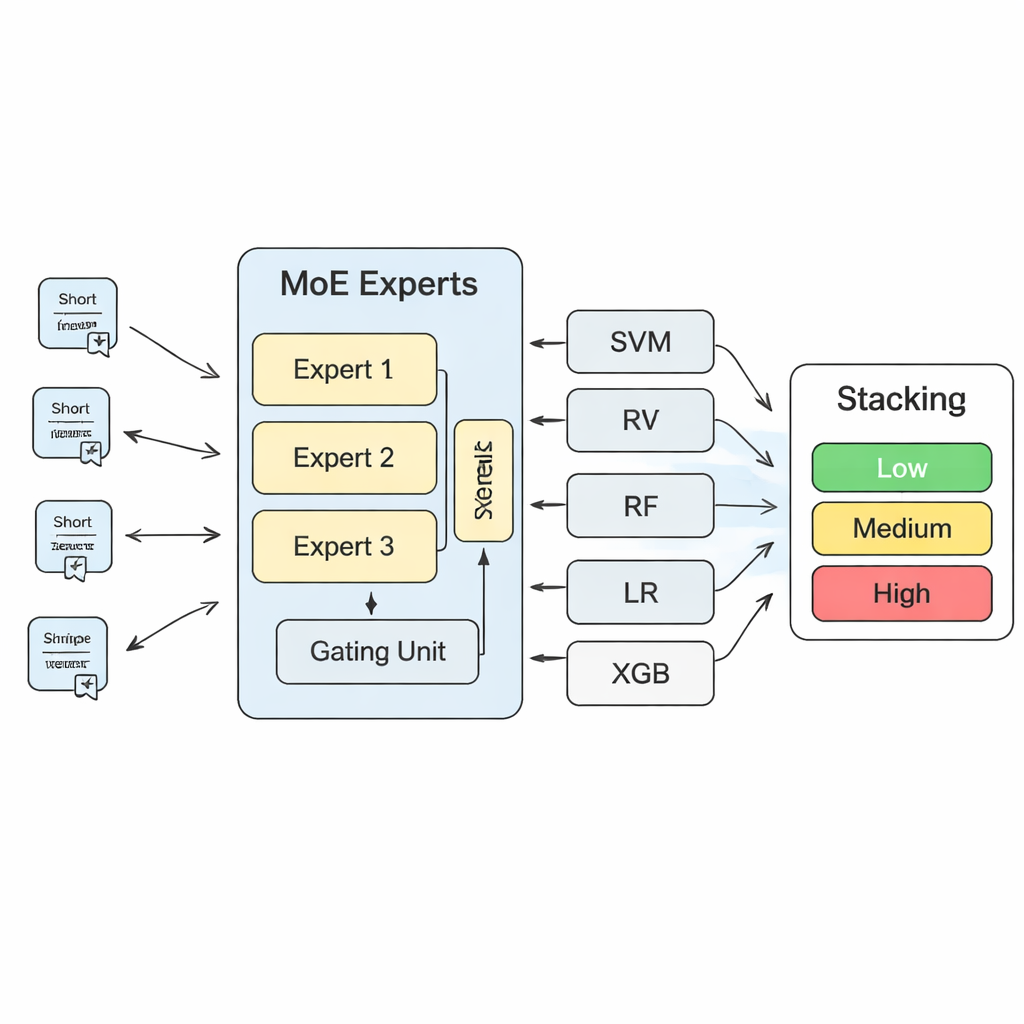
Misturando muitos modelos em um julgador de segurança mais forte
Para transformar essas percepções em previsões concretas de risco, o estudo constrói um sistema de aprendizado de máquina em camadas. No seu núcleo está um modelo “mistura de especialistas” (MoE): várias redes neurais, ou especialistas, cada uma aprendendo a se especializar em diferentes tipos de padrões de risco, enquanto um componente de gate decide em quais especialistas confiar mais para cada novo texto. As saídas desse modelo MoE são então combinadas com as previsões de algoritmos mais tradicionais, como máquinas de vetores de suporte, florestas aleatórias, regressão logística e árvores com boosting de gradiente. Uma camada final de “Stacking”—outro modelo de aprendizado de máquina—aprende a ponderar todas essas opiniões para alcançar uma decisão final. Através de extensa validação cruzada, os autores descobrem que usar três especialistas na camada MoE equilibra melhor a capacidade do modelo e a estabilidade.
O que os ganhos significam para a supervisão no mundo real
Comparado com qualquer modelo isolado, o sistema MoE-mais-Stacking melhora substancialmente acurácia, precisão, recall e uma medida de confiabilidade chamada LogLoss. Em termos práticos, isso significa menos avisos perdidos e menos falsos alarmes ao filtrar grandes volumes de texto de segurança. O modelo pode rodar em uma estação de trabalho comum e fornecer avaliações rápidas de risco para novos relatórios de inspeção ou reclamações, tornando-o adequado como uma ferramenta de suporte à decisão, e não um substituto do julgamento humano. Os autores destacam que sua abordagem poderia ser adaptada além dos brinquedos de diversão para outros equipamentos especiais, como elevadores ou teleféricos. Para leitores leigos, a conclusão-chave é que, ao ensinar computadores a ler a linguagem da segurança—em documentos técnicos, regulações e reclamações cotidianas—os reguladores podem detectar padrões de perigo mais cedo, direcionar inspeções de forma mais inteligente e tornar um dia no parque um pouco mais seguro para todos.
Citação: Hao, S., Xing, L. & Zhang, M. Risk factor identification for large scale amusement facilities using mixture of experts and fusion of multiple models. Sci Rep 16, 6804 (2026). https://doi.org/10.1038/s41598-026-36377-6
Palavras-chave: segurança em brinquedos de parque, análise de texto de risco, aprendizado de máquina, mistura de especialistas, monitoramento de segurança pública