Clear Sky Science · pt
Rede neural profunda Inception com conexões residuais para reconhecimento de caracteres manuscritos em Tamil
Preservando a escrita manual na era digital
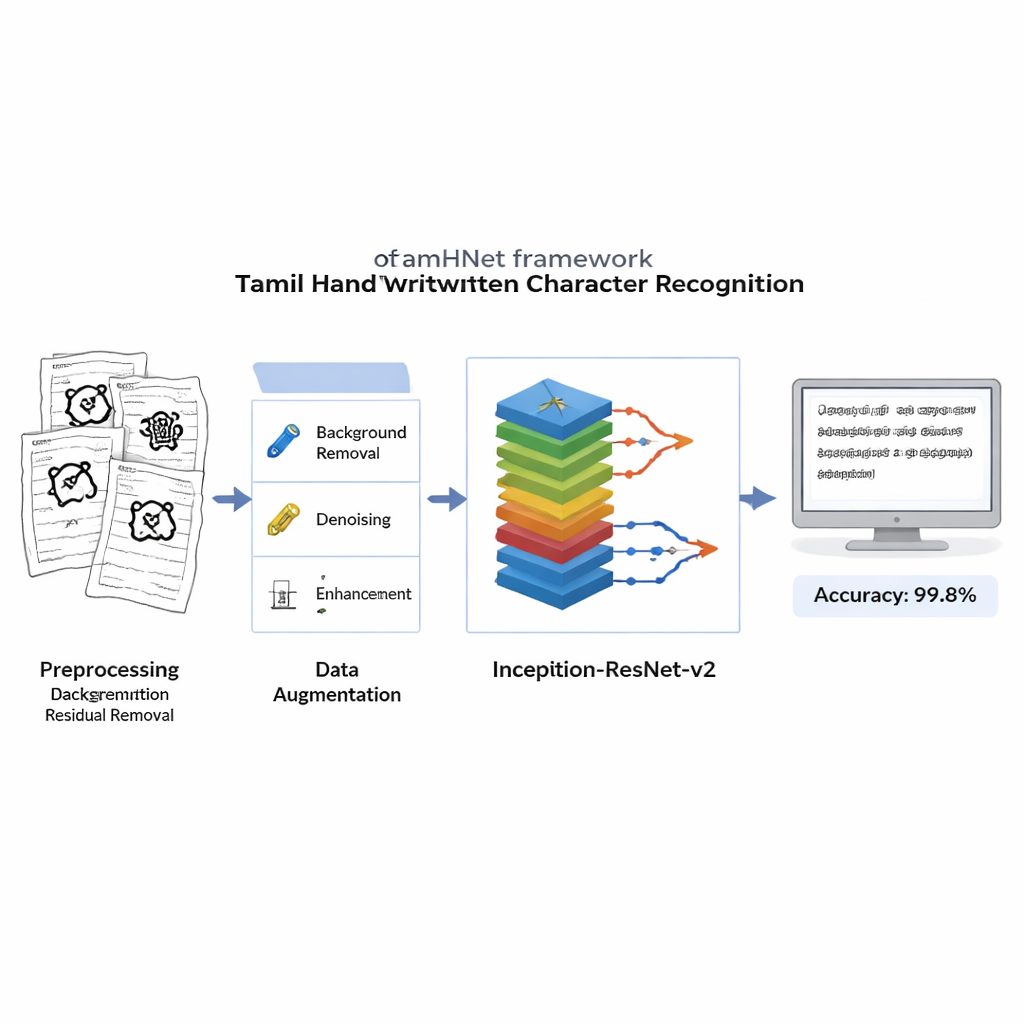
De antigos manuscritos em folhas de palmeira a anotações do dia a dia, grande parte do patrimônio escrito em Tamil ainda existe no papel. Converter esse rico conjunto de páginas manuscritas em texto digital pesquisável é essencial para preservar a cultura, apoiar a educação e desenvolver melhores tecnologias de linguagem. Este artigo apresenta um novo sistema de visão computacional, chamado TamHNet, que lê a caligrafia em Tamil com precisão quase perfeita, mesmo quando as letras parecem confusamente semelhantes entre si.
Por que as letras em Tamil são difíceis para computadores
O Tamil é falado por mais de 80 milhões de pessoas e usa uma escrita com 247 caracteres, incluindo vogais, consoantes e muitas combinações entre ambos. Muitas letras diferem apenas por pequenos cachos ou traços extras, e os escreventes variam muito na forma de cada caractere. Pares como எ/ஏ ou ஒ/ஓ podem parecer quase idênticos à primeira vista, e caracteres como ல e வ podem ser facilmente confundidos entre si. Programas antigos e até sistemas modernos de aprendizado de máquina frequentemente tinham dificuldade com essas sutilezas, levando a leituras incorretas de palavras e a uma digitalização pouco confiável de documentos.
Construindo um conjunto de dados de escrita real
Para treinar e testar o sistema em condições realistas, os pesquisadores criaram um novo Conjunto de Caracteres Isolados em Tamil usando amostras manuscritas de 1.000 estudantes universitários. Em vez de depender de imagens sintéticas ou geradas por computador, eles coletaram caracteres autênticos escritos com caneta no papel cobrindo 12 vogais, 18 consoantes e 214 combinações comuns. A equipe rotulou cuidadosamente essas amostras e tornou o conjunto de dados publicamente disponível para que outros grupos possam comparar métodos e ampliar esse trabalho. Ao organizar o sistema em 104 símbolos base que capturam os 247 caracteres, reduziram a redundância ao mesmo tempo em que representaram toda a variedade de formas presentes na escrita manual real.
Limpeza, distorção controlada e ensino das imagens
Antes de qualquer aprendizado, cada imagem digitalizada é limpa para remover fundos ruidosos, manchas e iluminação irregular, preservando os traços delicados que definem cada letra. As imagens são convertidas para preto e branco nítidos e redimensionadas para um formato padrão para que o computador veja cada exemplo da mesma maneira. Para tornar o sistema robusto a diferentes hábitos de escrita, os autores aplicam então distorções controladas: deslocam levemente pontos-chave na imagem e aplicam deformações suaves, gerando novas versões de cada caractere que ainda parecem o mesmo símbolo para um humano. Esse conjunto de treinamento ampliado ajuda o modelo a reconhecer caracteres mesmo quando estão inclinados, comprimidos ou escritos com proporções incomuns.
Uma rede profunda que aprende diferenças sutis
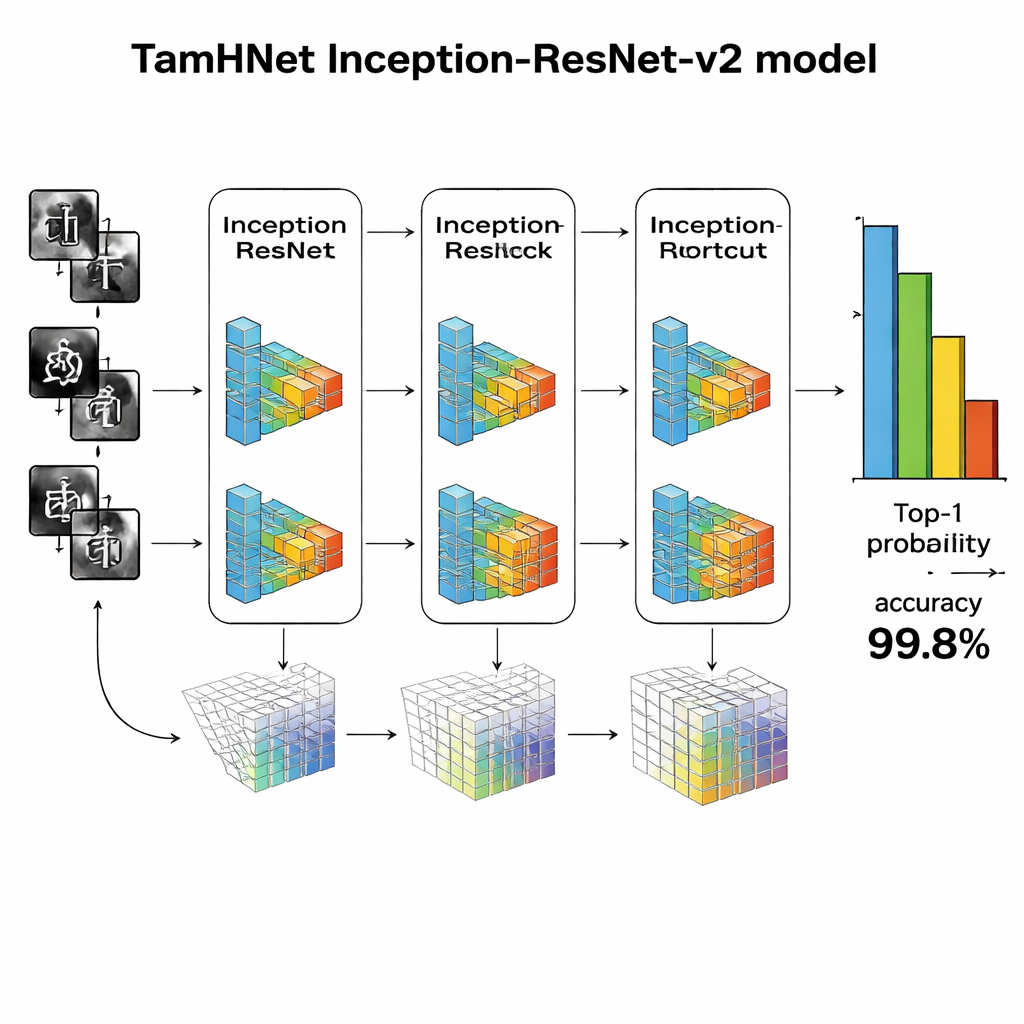
No núcleo do TamHNet está uma poderosa arquitetura de aprendizado profundo chamada Inception-ResNet-v2, originalmente projetada para reconhecimento geral de objetos. Os autores adaptam e ajustam finamente essa rede especificamente para a caligrafia em Tamil. O modelo processa cada imagem por muitas camadas que transformam gradualmente pixels brutos em padrões de nível mais alto, como bordas, curvas e partes de caracteres. Conexões especiais de atalho, conhecidas como links residuais, estabilizam o treinamento e ajudam a rede a focar nas diferenças pequenas, porém cruciais, entre letras semelhantes. Em vez de ajustar todas as configurações internas de uma só vez, a equipe “descongela” seletivamente as camadas mais úteis e as retreina para essa tarefa. Eles usam uma técnica de otimização chamada Adam, que adapta automaticamente a velocidade de atualização de cada parâmetro, permitindo que a rede aprenda de forma eficiente a partir de caligrafias complexas e por vezes imperfeitas.
Quão bem o sistema lê a escrita manual
Os pesquisadores avaliam o TamHNet no novo conjunto de dados usando medidas padrão de qualidade de reconhecimento. O sistema alcança cerca de 99,8% de acurácia em 104 classes de caracteres, superando uma ampla gama de métodos anteriores baseados em máquinas de vetores de suporte, redes convolucionais tradicionais e outros projetos avançados de aprendizado profundo. Testes detalhados mostram que mesmo letras com formas extremamente semelhantes são corretamente distinguidas na maioria dos casos, e curvas estatísticas confirmam que o modelo raramente confunde um caractere com outro. Em comparação com trabalhos anteriores, isso representa um avanço claro na confiabilidade do reconhecimento de caracteres manuscritos em Tamil.
O que isso significa para leitores e arquivos
Para não especialistas, a principal conclusão é que os computadores estão ficando dramaticamente melhores em ler a caligrafia em Tamil. Um sistema como o TamHNet pode alimentar ferramentas que transformam pilhas de cadernos, manuscritos históricos e formulários manuscritos em texto digital pesquisável com correção humana mínima. Embora o modelo atual ainda não trate certos símbolos pontilhados e variantes antigas da escrita, os autores descrevem planos para estendê-lo a estilos de escrita antigos também. Em termos práticos, essa pesquisa nos aproxima da digitalização em grande escala e com alta precisão de documentos em Tamil, ajudando a proteger o patrimônio cultural e tornando o conhecimento escrito mais acessível para as gerações futuras.
Citação: Periyasamy, H., Natarajan, S. & Amirtharajan, R. Deep inception neural network with residual connections for Tamil handwritten character recognition. Sci Rep 16, 6053 (2026). https://doi.org/10.1038/s41598-026-36330-7
Palavras-chave: reconhecimento de caracteres manuscritos em Tamil, reconhecimento óptico de caracteres, aprendizado profundo, Inception-ResNet, preservação digital