Clear Sky Science · pt
Comparação de desempenho de grandes modelos de linguagem na avaliação de conhecimentos sobre terapia de captura de nêutrons com boro
Tutores inteligentes para um novo tipo de radiação contra o câncer
A terapia de captura de nêutrons com boro, ou BNCT, é um tipo emergente de tratamento por radiação que visa destruir tumores preservando o tecido saudável adjacente. À medida que essa terapia complexa migra dos laboratórios de pesquisa para os hospitais, médicos e profissionais em formação precisam dominar um grande volume de conhecimentos especializados. Este estudo faz uma pergunta oportuna: os chatbots de inteligência artificial populares hoje podem ajudar a ensinar e apoiar a BNCT e, se sim, quão confiáveis eles são?
O que torna a BNCT diferente da radioterapia convencional?
A BNCT funciona de maneira muito distinta dos tratamentos padrão por raios X ou prótons. Os pacientes recebem fármacos que contêm uma forma especial de boro que se acumula dentro das células tumorais. Quando essas células são posteriormente expostas a um feixe de nêutrons, os átomos de boro sofrem uma pequena reação nuclear que libera partículas de curto alcance, matando a célula cancerígena internamente e deixando o tecido próximo amplamente intacto. Essa abordagem altamente direcionada é especialmente promissora para tumores de difícil tratamento ou com baixa oxigenação. Até recentemente, a BNCT dependia de reatores nucleares como fontes de nêutrons, o que limitava seu uso clínico. A aprovação de aparelhos de BNCT baseados em aceleradores no Japão em 2020, e novos centros agora operando em países como a China, transformaram a BNCT em uma opção realista para mais pacientes — e criaram uma necessidade urgente de treinamento e certificação focados.
Testando quatro IAs líderes
Para avaliar quão bem chatbots de uso geral lidam com tópicos de BNCT, os pesquisadores criaram um teste de 47 perguntas cobrindo conceitos básicos, pesquisas recentes, prática clínica e tarefas de cálculo e raciocínio. As perguntas foram escritas em chinês e inglês e incluíram fatos simples (como definições) e problemas mais exigentes que requeriam lógica ou trabalho numérico. Quatro famílias principais de IA — representadas por sistemas amplamente usados de diferentes empresas — foram testadas em cinco períodos distintos, em duas línguas e com duas formas de formular as perguntas (perguntas diretas simples e perguntas apresentadas num breve cenário clínico). Especialistas humanos em cuidados oncológicos pontuaram cada resposta com base em um gabarito padrão, e a equipe também acompanhou com que frequência as IAs admitiam incerteza dizendo coisas como "não sei".
Quem respondeu melhor e em que tipo de perguntas?
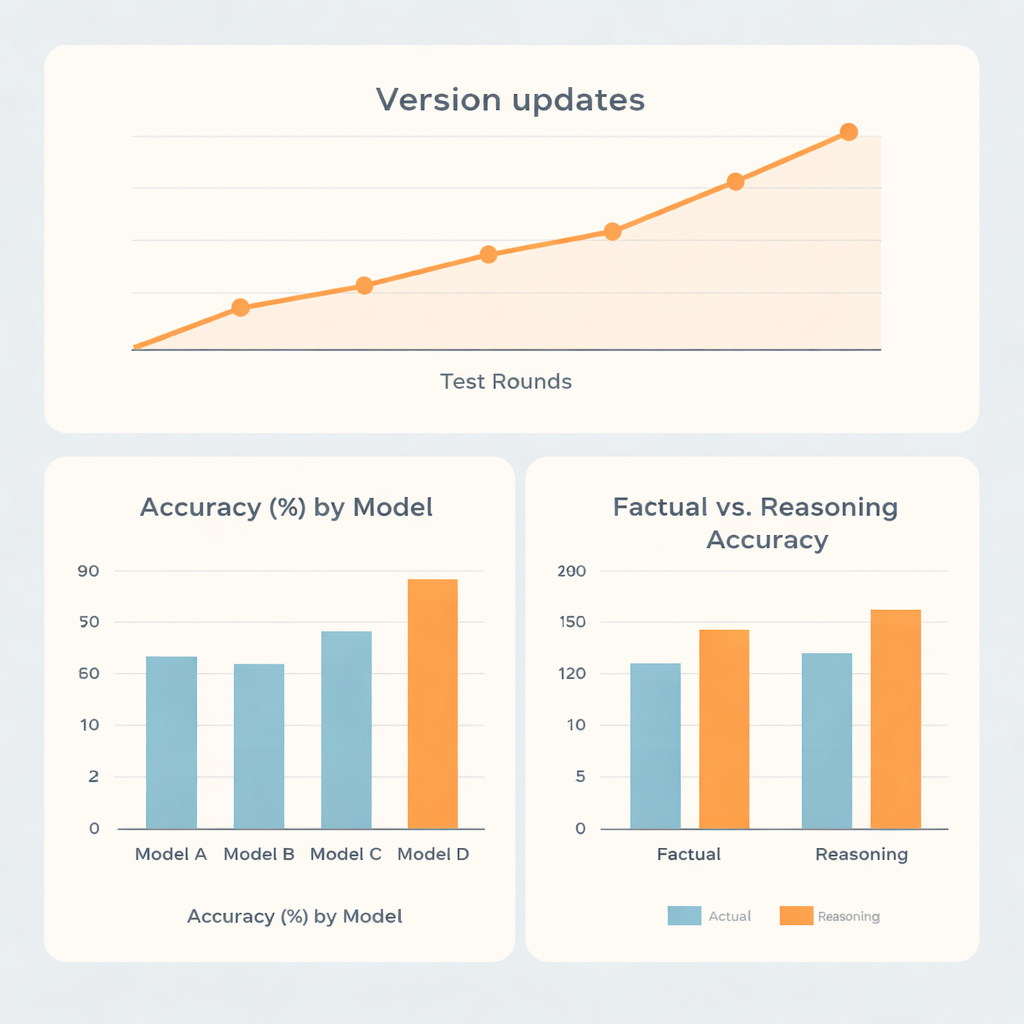
No geral, duas famílias de modelos tiveram desempenho claramente superior às outras duas. O sistema mais forte alcançou cerca de 73% de acurácia, e o segundo melhor cerca de 70%, enquanto os modelos restantes marcaram por volta de 62% e 56%. Curiosamente, os melhores não se destacaram apenas em fatos memorizados. Eles foram notavelmente melhores em perguntas que exigiam raciocínio do que em recordação direta, sugerindo que esses sistemas são relativamente fortes em tarefas de pensamento em múltiplas etapas, como cálculos de dose ou problemas do tipo planejamento, dentro desse campo médico restrito. Um modelo apresentou pontuações quase iguais em itens de fato e de raciocínio, enquanto outro ficou atrás no geral apesar de ter um desempenho um pouco melhor em raciocínio do que em fatos.
Atualizações, idiomas e a disposição de dizer "não sei"
Como os sistemas de IA são frequentemente atualizados, os pesquisadores também examinaram como o desempenho mudou ao longo de cinco rodadas de testes distribuídas entre o final de 2023 e meados de 2025. Grandes atualizações de versão tendiam a trazer saltos claros na acurácia, enquanto ajustes menores dentro da mesma versão fizeram pouca diferença. Uma família subiu de menos de 60% para mais de 80% de acurácia ao longo do tempo, destacando a rapidez do avanço tecnológico. Surpreendentemente, o fato de as perguntas serem feitas em chinês ou inglês, ou formuladas diretamente versus inseridas num enunciado de interpretação de papel, teve apenas efeitos pequenos comparados às forças intrínsecas de cada modelo. Mais marcantes foram as diferenças em quão francos os sistemas eram quando estavam errados. Alguns modelos admitiam incerteza em quase uma em cada cinco respostas incorretas, enquanto outro raramente fazia isso, muitas vezes oferecendo respostas equivocadas com confiança.
O que isso significa para médicos, estudantes e pacientes
O estudo conclui que os melhores chatbots de uso geral hoje já podem fornecer explicações razoavelmente precisas e questões de prática sobre BNCT, tornando-os auxiliares promissores para educação e autoestudo. No entanto, nenhum dos sistemas pode ainda ser confiado para responder corretamente a todas as perguntas sobre BNCT, e seus modos de expressar — ou ocultar — incerteza variam de maneiras que importam para a segurança. Por ora, essas ferramentas são melhores vistas como assistentes inteligentes que podem apoiar, mas não substituir, o julgamento de especialistas. Os autores argumentam que modelos de IA dedicados e focados em BNCT, juntamente com padrões claros sobre como tais ferramentas devem ser usados em clínicas e salas de aula, serão necessários antes que a IA possa desempenhar um papel confiável na linha de frente deste formato altamente especializado de cuidado oncológico.
Citação: Shen, S., Wang, S., Gao, M. et al. Performance comparison of large language models in boron neutron capture therapy knowledge assessment. Sci Rep 16, 5321 (2026). https://doi.org/10.1038/s41598-026-36322-7
Palavras-chave: terapia de captura de nêutrons com boro, radiação contra o câncer, educação médica, inteligência artificial, grandes modelos de linguagem