Clear Sky Science · pt
Pré-treinamento contrastivo linguagem-imagem guiado por objeto para reconhecimento de alvos zero-shot
Olhos mais inteligentes para céus e mares congestionados
Sistemas modernos de segurança e resposta a desastres dependem de câmeras no céu e no mar para detectar aeronaves, embarcações e outros objetos críticos. Mas ensinar computadores a distinguir um caça de um avião de passageiros, ou um navio de guerra de um cargueiro, é surpreendentemente difícil quando as cenas estão cheias, os dados são escassos e novos modelos de equipamento surgem constantemente. Este artigo apresenta o OG‑CLIP, um novo sistema de IA projetado para reconhecer alvos militares e civis nos quais ele nunca foi treinado explicitamente, combinando conhecimento prévio em larga escala com um foco visual mais apurado nos objetos que realmente importam.
Por que a IA tradicional erra o alvo
A maioria dos sistemas de reconhecimento de imagem aprende a partir de grandes coleções de imagens rotuladas: cada imagem está vinculada a uma lista fixa de categorias, como “gato” ou “carro”. Essa abordagem se mostra inadequada em domínios especializados como defesa e sensoriamento remoto, onde os dados são sensíveis, a rotulagem exige especialistas e a variedade de equipamentos é enorme. Modelos visão‑linguagem mais recentes, como o CLIP, emparelham imagens com legendas curtas coletadas na web, permitindo reconhecer novos conceitos descritos em palavras. Ainda assim, em imagens militares esses modelos continuam com dificuldades: as legendas frequentemente são vagas, fundos como nuvens e ondas dominam os pixels e suas representações internas não são flexíveis o suficiente para rodar eficientemente em tudo, desde pequenos drones até servidores potentes. O OG‑CLIP enfrenta esses três problemas diretamente.
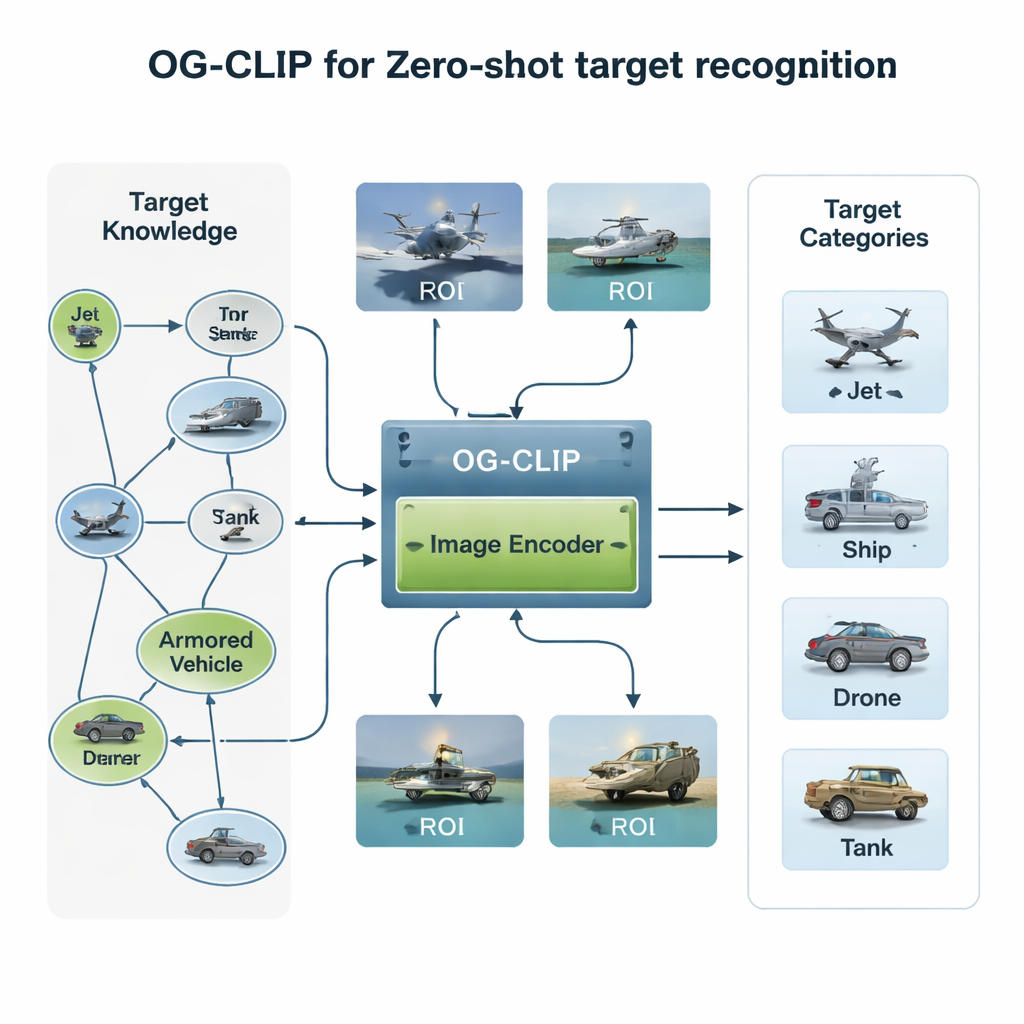
Construindo um mundo de treino rico em conhecimento
O primeiro ingrediente do OG‑CLIP é um universo de treinamento cuidadosamente projetado. Os autores reuniram um banco de dados com 5.000 tipos de alvos — que vão de caças e bombardeiros a navios de guerra e aeronaves civis — e os organizaram em um grafo de conhecimento detalhado. Cada entrada inclui fatos estruturados, como alcance, peso e configuração de armamento, extraídos de referências públicas de defesa, enciclopédias e documentos técnicos. Em seguida, coletaram cerca de um milhão de imagens usando conjuntos de dados públicos, buscas na web, arquivos internos antigos e até cenas simuladas em motores de jogo. Para manter a confiabilidade dos dados, agruparam imagens usando um modelo existente para detectar outliers, realizaram revisões por especialistas e filtraram rótulos ruins. Por fim, usaram ferramentas avançadas visão‑linguagem para transformar o grafo de conhecimento em descrições ricas em linguagem natural para cada imagem, de modo que o sistema aprende não apenas “isto é um jato”, mas “uma aeronave de corredor único com winglets curvados para cima” ou “um bombardeiro stealth com formato de asa voadora”.
Ensinando o modelo a ignorar o ruído
A segunda inovação está em onde o modelo olha. Em muitas imagens de satélite ou aéreas, o navio ou a aeronave real ocupa apenas um pequeno recorte, rodeado por céu, mar ou terreno que distraem. O OG‑CLIP adiciona um módulo de região de interesse (ROI) que imita como um humano focalizaria o objeto-chave em vez do quadro inteiro. Uma ferramenta de segmentação de última geração contorna automaticamente os prováveis objetos na imagem, produzindo máscaras suaves que destacam o alvo e escurecem o fundo. Essas máscaras são alimentadas, junto com a imagem original, na espinha dorsal visual do modelo, de modo que sua atenção naturalmente se concentra em características distintivas como formato da asa, disposição do convés ou silhueta do casco. Esse design plug‑in pode ser adicionado a sistemas existentes sem reescrever sua arquitetura central, conferindo-lhes um olhar mais “guiado por objeto”.

Adaptando o detalhe ao hardware
A terceira peça aborda uma preocupação prática, mas crucial: nem todos os dispositivos podem arcar com o mesmo nível de detalhe. Uma estação terrestre de satélite pode processar recursos ricos e de alta dimensão, enquanto um pequeno drone precisa de cálculos mais rápidos e leves. Métodos tradicionais fixam um único tamanho de representação ou treinam vários modelos separados para diferentes tamanhos. O OG‑CLIP, em vez disso, usa uma representação em estilo “Matryoshka”, empacotando informação em múltiplos níveis de detalhe dentro de um único vetor, como bonecas russas aninhadas. O sistema pode recortar porções mais curtas ou mais longas desse vetor — descrições mais grosseiras ou mais finas do que há na imagem — sem retrainar. Um mecanismo de ponderação incentiva cada nível a manter a informação mais útil para a classificação, e um termo de perda adicional estimula que os níveis permaneçam semanticamente consistentes entre si.
Quão bem funciona na prática?
Para testar o OG‑CLIP, os pesquisadores construíram um conjunto de avaliação desafiador com 99 categorias de alvo, incluindo 51 tipos de aeronaves militares, 29 tipos de navios de guerra e 19 alvos civis ou mistos. Crucialmente, nenhuma dessas categorias aparece nos dados de treinamento, de modo que o sistema deve confiar em sua compreensão aprendida da linguagem e dos padrões visuais — um teste “zero‑shot”. Em comparação com várias linhas de base fortes baseadas em CLIP, o OG‑CLIP melhorou a acurácia média em mais de 11 pontos percentuais, atingindo 84,28% no total. Teve desempenho especialmente bom em cenas lotadas e complexas e em distinções finas entre modelos semelhantes, como diferentes caças, onde o módulo ROI e as descrições ricas em conhecimento lhe deram vantagem clara. Estudos de ablação mostraram que cada componente — os dados do grafo de conhecimento, o foco ROI e as representações adaptativas — contribuiu com ganhos mensuráveis.
O que isso significa para monitoramento no mundo real
Para não especialistas, a conclusão principal é que o OG‑CLIP representa um avanço para sistemas de segurança e monitoramento capazes de reconhecer com mais confiabilidade aeronaves e navios desconhecidos a partir de imagens do mundo real, mesmo quando exemplos rotulados são escassos. Ao combinar conhecimento especializado estruturado, foco automático no objeto de interesse e níveis ajustáveis de detalhe, a abordagem torna a IA visão‑linguagem mais inteligente e mais prática. Além da defesa, ideias semelhantes podem ajudar monitoramento ambiental, resposta a desastres e sistemas de inspeção industrial a interpretar cenas complexas enquanto rodam em uma ampla gama de hardware.
Citação: Zheng, C. Object-guided contrastive language-image pre-training for zero-shot target recognition. Sci Rep 16, 6425 (2026). https://doi.org/10.1038/s41598-026-36314-7
Palavras-chave: reconhecimento zero-shot, modelos visão-linguagem, detecção de objetos, sensoriamento remoto, grafos de conhecimento