Clear Sky Science · pt
Percepção visual baseada em transformadores de deep learning para classificar pinturas e fotografias por extração de características
Por que isso importa para imagens do dia a dia
Em uma era em que qualquer pessoa pode gerar uma imagem realista com alguns cliques, está cada vez mais difícil distinguir se uma imagem é uma fotografia real, uma pintura tradicional ou algo criado inteiramente por algoritmos. Este estudo explora como a inteligência artificial moderna pode distinguir automaticamente pinturas feitas por humanos de fotos tiradas por câmeras e até de imagens geradas por IA, ajudando a proteger mercados de arte, arquivos e usuários online de confusão e falsificações.
Arte, fotografias e a ascensão das imagens feitas por máquinas
Pinturas e fotografias podem parecer semelhantes à primeira vista na tela, mas carregam impressões visuais muito diferentes. Pinturas tendem a mostrar pinceladas visíveis, cores estilizadas e composições mais abstratas, enquanto fotografias geralmente contêm detalhes mais nítidos e iluminação natural. Ao mesmo tempo, novos geradores de imagem estão produzindo obras que imitam ambos os meios com habilidade crescente. Museus, galerias, colecionadores e plataformas digitais precisam cada vez mais de ferramentas capazes de identificar rapidamente e com confiança que tipo de imagem estão analisando, tanto para autenticar obras quanto para gerenciar o fluxo de conteúdo sintético.
Um novo pipeline para ensinar máquinas a ver
Os pesquisadores construíram um pipeline completo de análise de imagens baseado em um Vision Transformer, um modelo recente de deep learning originalmente desenvolvido para processamento de linguagem e agora adaptado para imagens. Eles treinaram esse sistema em um conjunto de dados público do Kaggle contendo 1.361 pinturas e 3.747 fotografias, representando uma ampla variedade de cenas e estilos. Cada imagem é primeiro padronizada: é redimensionada, levemente recortada e então aumentada por meio de flip, pequenas rotações, alterações de brilho e remoção de ruído, para que o modelo experimente muitas variações realistas. Após essa preparação, o Vision Transformer divide cada imagem em pequenos blocos (patches) e aprende como diferentes partes da imagem se relacionam entre si em todo o quadro. 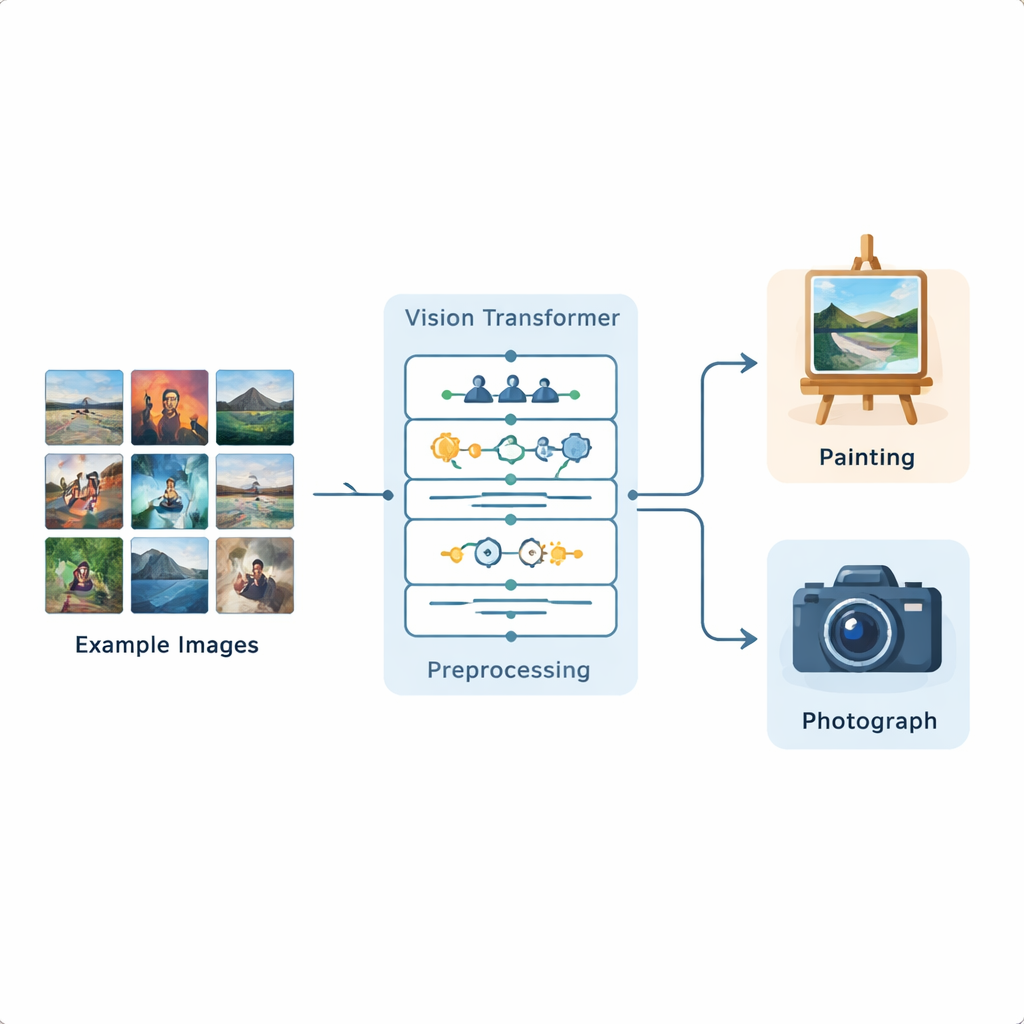
Como o modelo foca nos detalhes certos
Diferente de redes neurais anteriores que olham principalmente para padrões locais, o Vision Transformer usa um mecanismo de “atenção” para decidir quais partes da imagem importam mais para a tarefa. Ele efetivamente pergunta, para cada bloco, com que intensidade deve prestar atenção a cada outro bloco. Isso o torna melhor em notar a estrutura global: a forma como as cores se espalham pela tela, como a luz incide sobre uma cena ou como texturas se repetem. Para verificar se o modelo não está adivinhando às cegas, os autores também aplicam um método de visualização chamado Grad-CAM, que destaca as regiões específicas que influenciaram cada decisão. Para pinturas, esses destaques tendem a recair sobre texturas de pincelada e áreas estilizadas; para fotografias, concentram-se em bordas finas, superfícies realistas e transições de iluminação. 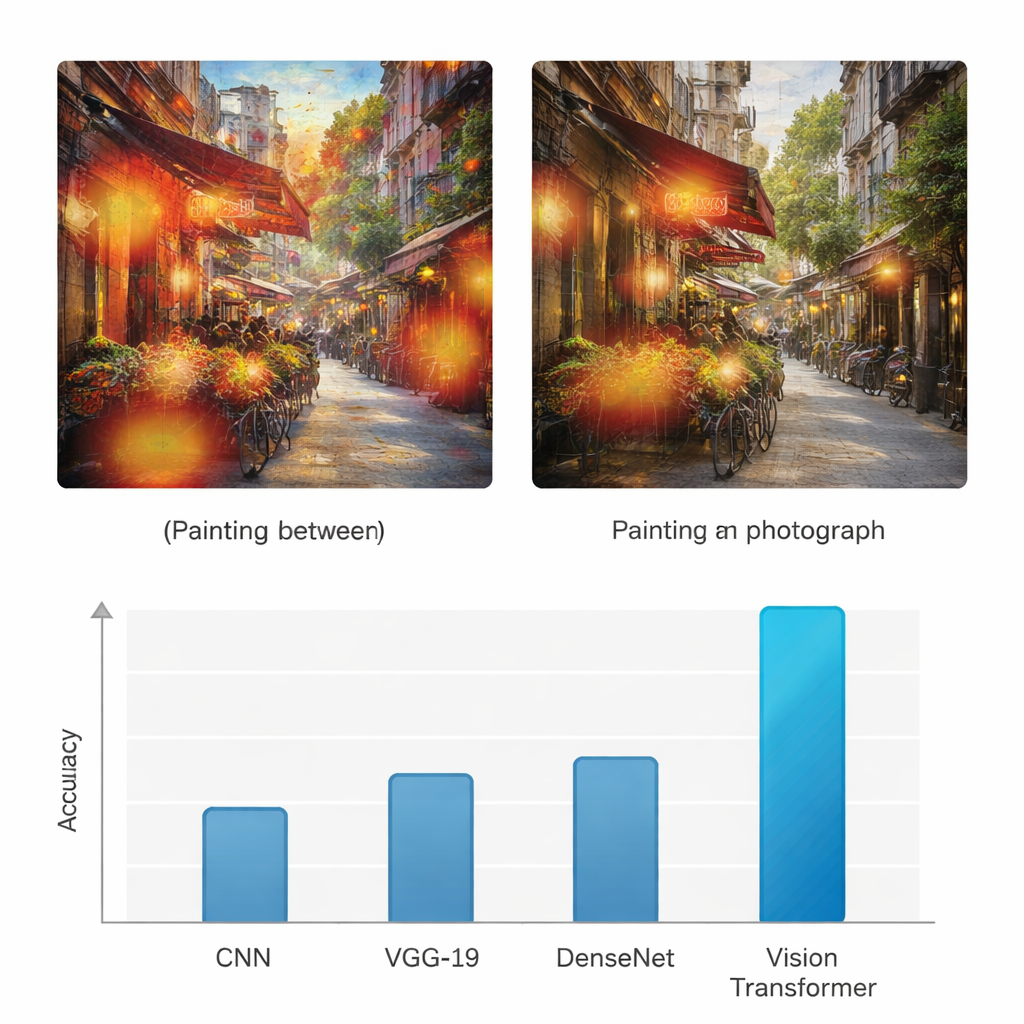
Superando métodos anteriores de reconhecimento de imagens
Para avaliar se essa abordagem realmente agrega valor, o estudo compara o Vision Transformer com três arquiteturas amplamente usadas de deep learning: uma rede neural convolucional (CNN) padrão, a rede VGG-19 e a DenseNet. Todos os modelos são treinados e testados no mesmo conjunto de dados e avaliados com medidas comuns como acurácia, precisão, recall e F1-score, que equilibram detecções corretas e erros para ambas as classes. Enquanto as redes de referência alcançam acurácias na faixa de meados dos 70% a meados dos 80%, o Vision Transformer atinge 95% de acurácia tanto para pinturas quanto para fotografias, com precisão e recall igualmente altos. Os autores também realizaram vários testes estatísticos para confirmar que essa melhoria não se deve ao acaso, mostrando que o modelo baseado em transformer é consistentemente melhor em repetições de testes e diferentes critérios de avaliação.
O que isso significa para arte, confiança e tecnologia
Os resultados sugerem que modelos transformer modernos podem atuar como ferramentas poderosas e explicáveis para separar pinturas de fotografias e para sinalizar imagens geradas por IA que imitam qualquer um dos meios. Para não especialistas, a conclusão é que os computadores agora podem detectar pistas sutis — como marcas de pincel, suavidade ou gradientes de iluminação — que até observadores humanos cuidadosos podem deixar passar, e fazê-lo em grande escala. Sistemas desse tipo podem ajudar galerias e colecionadores a verificar obras, auxiliar curadores e arquivistas a organizar vastas coleções digitais e apoiar plataformas online na rotulagem ou filtragem de conteúdo sintético. À medida que os geradores de imagem continuam a borrar a linha entre realidade e invenção, métodos como o apresentado aqui oferecem uma maneira prática de manter a confiança no que vemos.
Citação: Yu, L. Visual perception based deep learning transformers for classifying paintings and photographs through feature extraction. Sci Rep 16, 5326 (2026). https://doi.org/10.1038/s41598-026-36298-4
Palavras-chave: imagens geradas por IA, autenticação de arte, classificação de imagens, vision transformer, análise de arte digital