Clear Sky Science · pt
Meta-aprendizagem para reconhecimento de tarefas abertas com poucos exemplos
Por que ensinar IA com pouquíssimos exemplos importa
Sistemas modernos de IA conseguem reconhecer rostos, animais e objetos cotidianos com precisão impressionante — mas normalmente apenas após verem milhões de imagens rotuladas. Em muitas situações reais, como diagnosticar uma doença rara ou detectar um novo tipo de defeito em uma linha de produção, simplesmente não há tantos dados disponíveis. Este artigo explora como treinar modelos de IA que possam aprender novas tarefas visuais a partir de apenas alguns exemplos, mesmo quando essas tarefas diferem bastante daquelas vistas durante o treinamento. Ele apresenta um método chamado Open-MAML que busca tornar esse tipo de aprendizado flexível e com poucos dados mais confiável e previsível.
De exercícios fixos em sala para testes surpresa abertos
A maior parte da pesquisa sobre “few-shot learning” avalia sistemas de IA sob condições rigidamente controladas. O modelo é treinado e testado em tarefas muito semelhantes — por exemplo, sempre distinguindo exatamente cinco categorias (chamado “5-way”) com um exemplo por categoria (“1-shot”). Isso é como treinar um aluno apenas com provas de cinco perguntas e um exemplo de prática por tipo de pergunta. Implantações no mundo real são bem mais confusas: o número de categorias pode mudar, e a quantidade de dados rotulados por categoria pode aumentar ou diminuir ao longo do tempo. Os autores chamam essa situação mais realista de cenário de tarefa aberta, em que os modelos precisam lidar com tarefas que têm números de classes e exemplos diferentes dos vistos no treinamento. 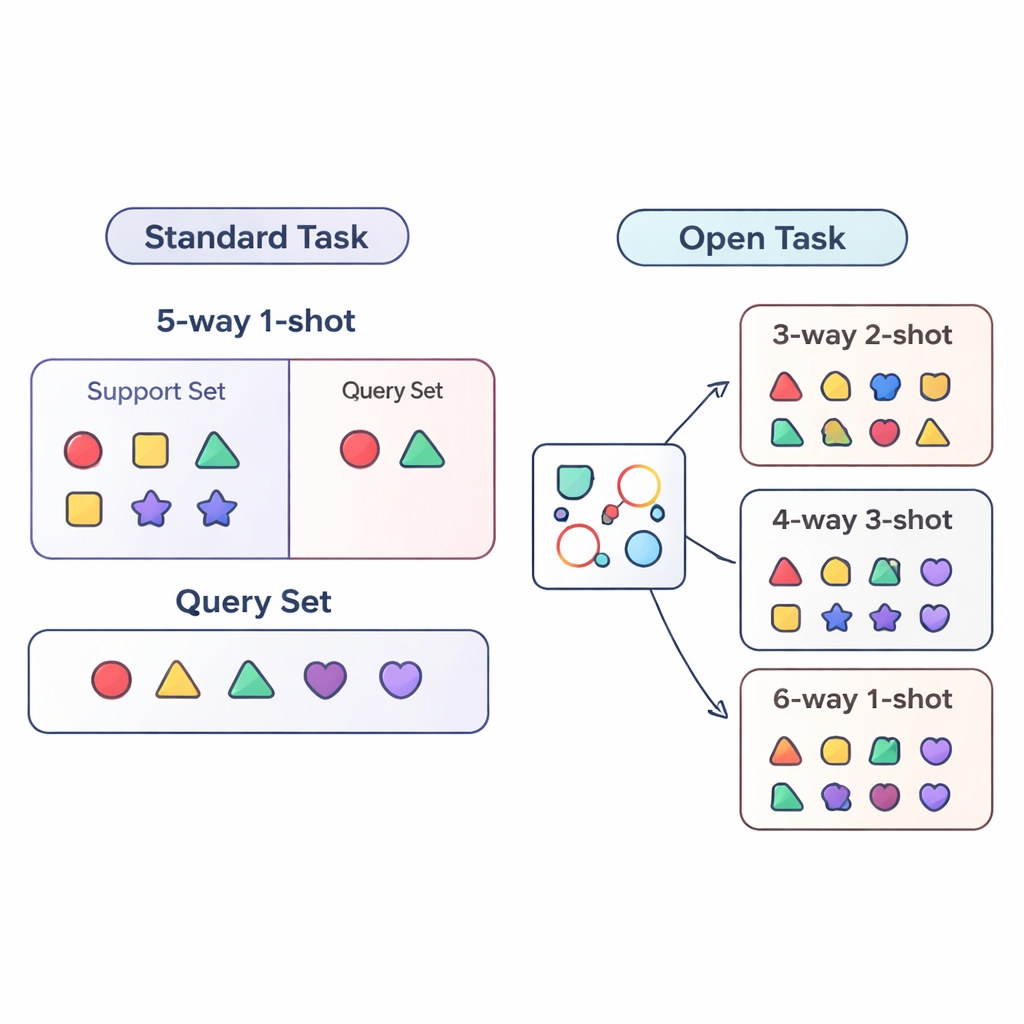
Redefinindo como testamos aprendizes com poucos exemplos
Para estudar esse mundo de tarefas abertas de forma sistemática, o artigo propõe três regimes de avaliação. No regime cross-way, muda apenas o número de classes: o modelo pode treinar com cinco classes, mas ser testado em três ou quinze. No regime cross-shot, varia o número de exemplos por classe, desde uma única imagem rotulada até várias. O caso mais difícil é cross-way–cross-shot, onde tanto o número de classes quanto a quantidade de dados por classe mudam simultaneamente. Os autores também examinam o que acontece quando o estilo visual dos dados muda, treinando em um conjunto genérico de objetos e testando em um conjunto de aves de alta granularidade. Essas configurações são projetadas para revelar se um método realmente consegue generalizar além de uma única receita de treinamento fixa.
Como o Open-MAML se adapta em tempo real
Open-MAML baseia-se em uma estratégia popular de meta-aprendizagem chamada Model-Agnostic Meta-Learning (MAML), que treina um modelo para que ele possa se adaptar rapidamente a uma nova tarefa com alguns passos de gradiente. O MAML padrão, porém, assume que o número de categorias no momento do teste coincide com o do treinamento, e usa uma camada final de classificação fixa. Open-MAML introduz três ajustes-chave para romper essa limitação. Primeiro, usa construção dinâmica do classificador: quando uma nova tarefa tem mais classes do que antes, ele cria unidades de saída extras copiando a média das existentes, dando ao modelo um ponto de partida neutro, mas sensato. Segundo, ajusta a taxa de aprendizado interna com base em quantas classes e exemplos a tarefa tem, de modo que a adaptação permaneça estável tanto com dados escassos quanto abundantes. Terceiro, adiciona um regularizador chamado AdaDropBlock que oculta temporariamente regiões contíguas nos mapas de características durante o treinamento, incentivando o modelo a usar pistas visuais mais diversas em vez de se ajustar demais a detalhes pequenos e frágeis. 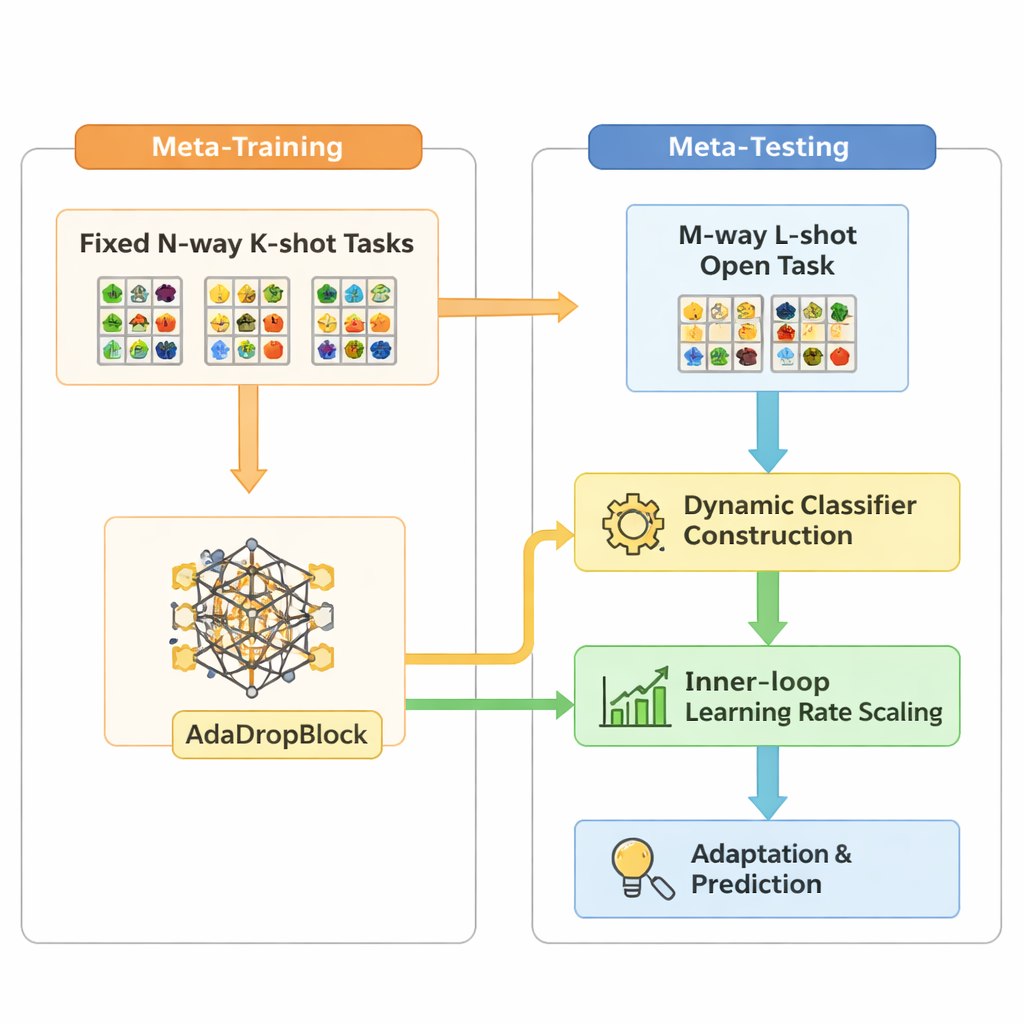
Colocando o aprendizado flexível à prova
Os pesquisadores avaliam o Open-MAML em benchmarks padrão de few-shot e sob os novos cenários de tarefa aberta, comparando-o com várias linhas de base conhecidas. Isso inclui modelos treinados do zero para cada tarefa, modelos que usam um extrator de características pré-treinado forte mais um classificador ajustado, e métodos baseados em métricas que classificam imagens pela distância a “protótipos” das classes. Todos os métodos compartilham a mesma rede backbone para que as diferenças venham da estratégia de aprendizado, não da arquitetura. Ao longo de dezenas de milhares de tarefas de teste, Open-MAML alcança consistentemente maior acurácia — tipicamente de 1 a 7 pontos percentuais a mais quando apenas o número de classes ou de exemplos muda, e 3 a 6 pontos a mais quando ambos variam. Os ganhos são ainda mais pronunciados em cenários mais desafiadores com mais classes, mais exemplos por classe, ou com a mudança para o conjunto de aves, sugerindo que seus mecanismos de adaptação realmente ajudam em territórios complexos e desconhecidos.
O que isso significa para sistemas de IA no mundo real
Para o leitor geral, a mensagem principal é que nem todos os aprendizes com poucos exemplos são iguais quando saímos da zona de conforto do laboratório. Um método que se destaca em um único benchmark fixo pode tropeçar quando o número de categorias ou a quantidade de dados rotulados muda. Open-MAML mostra que, ao planejar explicitamente para tais mudanças estruturais — permitindo que o classificador cresça ou encolha, ajustando a taxa de aprendizado ao tamanho da tarefa e regularizando características de forma independente da tarefa —, sistemas de IA podem lidar melhor com as condições variáveis que encontrarão na prática. Em cenários como imagens médicas, monitoramento por satélite ou inspeção industrial, onde tanto o conjunto de categorias quanto a disponibilidade de rótulos estão em fluxo constante, esse tipo de robustez para tarefas abertas pode tornar o few-shot learning muito mais utilizável fora de benchmarks cuidadosamente curados.
Citação: Han, X., Shi, D., Wang, Z. et al. Meta-learning for few-shot open task recognition. Sci Rep 16, 5624 (2026). https://doi.org/10.1038/s41598-026-36291-x
Palavras-chave: aprendizado com poucos exemplos, meta-aprendizagem, reconhecimento de tarefas abertas, classificação de imagens, generalização