Clear Sky Science · pt
Substituição dialetal como abordagem adversarial para avaliar a robustez do PNL em árabe
Por que o árabe do dia a dia confunde computadores inteligentes
Muitos aplicativos hoje em dia leem textos em árabe para avaliar sentimento, organizar notícias ou responder perguntas. Ainda assim, esses sistemas aprendem majoritariamente com o Árabe Padrão Moderno (MSA), enquanto as pessoas reais misturam dialetos regionais no cotidiano. Este artigo mostra como trocar apenas uma palavra por sua forma no árabe egípcio ou do Golfo pode enganar modelos de linguagem de ponta, levantando preocupações para quem depende de IA em árabe em atendimento ao cliente, monitoramento de mídia ou segurança online.
Uma língua, muitas vozes
O árabe não é uma forma única e uniforme de falar. O MSA é usado nas escolas, nas notícias e na escrita oficial, mas as conversas diárias dependem de dialetos como o egípcio e o do Golfo. Essas variedades diferem em vocabulário, formas de palavras e até na estrutura das frases. Por exemplo, uma palavra simples como “agora” tem formas muito diferentes conforme a região. Para leitores humanos, essas variações são naturais e fáceis de entender. Para modelos de computador treinados quase inteiramente em MSA, no entanto, palavras dialetais podem parecer desconhecidas, transformando uma frase clara em algo confuso.
Transformando dialetos em um teste de estresse para IA
Para sondar quão frágeis são realmente os modelos de linguagem em árabe, o autor desenvolve um teste simples em duas etapas. Primeiro, um modelo é consultado repetidamente para encontrar a única palavra em uma frase que mais influencia sua decisão — muitas vezes um adjetivo forte, um verbo-chave ou um substantivo tópico. Segundo, essa palavra é substituída por um equivalente no árabe egípcio ou do Golfo usando um grande modelo “dialeitizador” cuidadosamente ajustado. O restante da frase permanece intacto, e o sentido continua o mesmo para leitores humanos. Isso transforma a frase alterada em um exemplo adversarial realista: um ajuste pequeno e com aparência natural, criado para enganar o sistema sem mudar a mensagem pretendida.
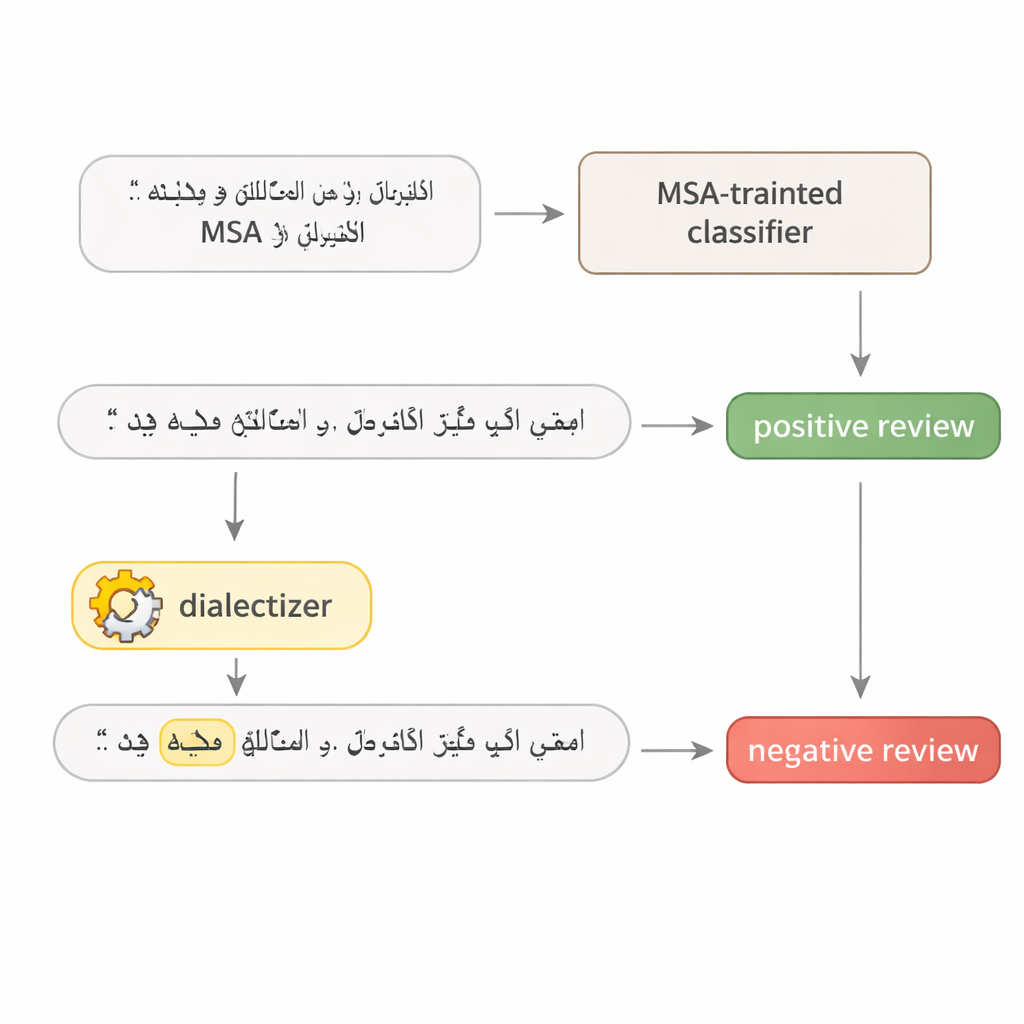
Testando avaliações de hotéis e matérias de notícias
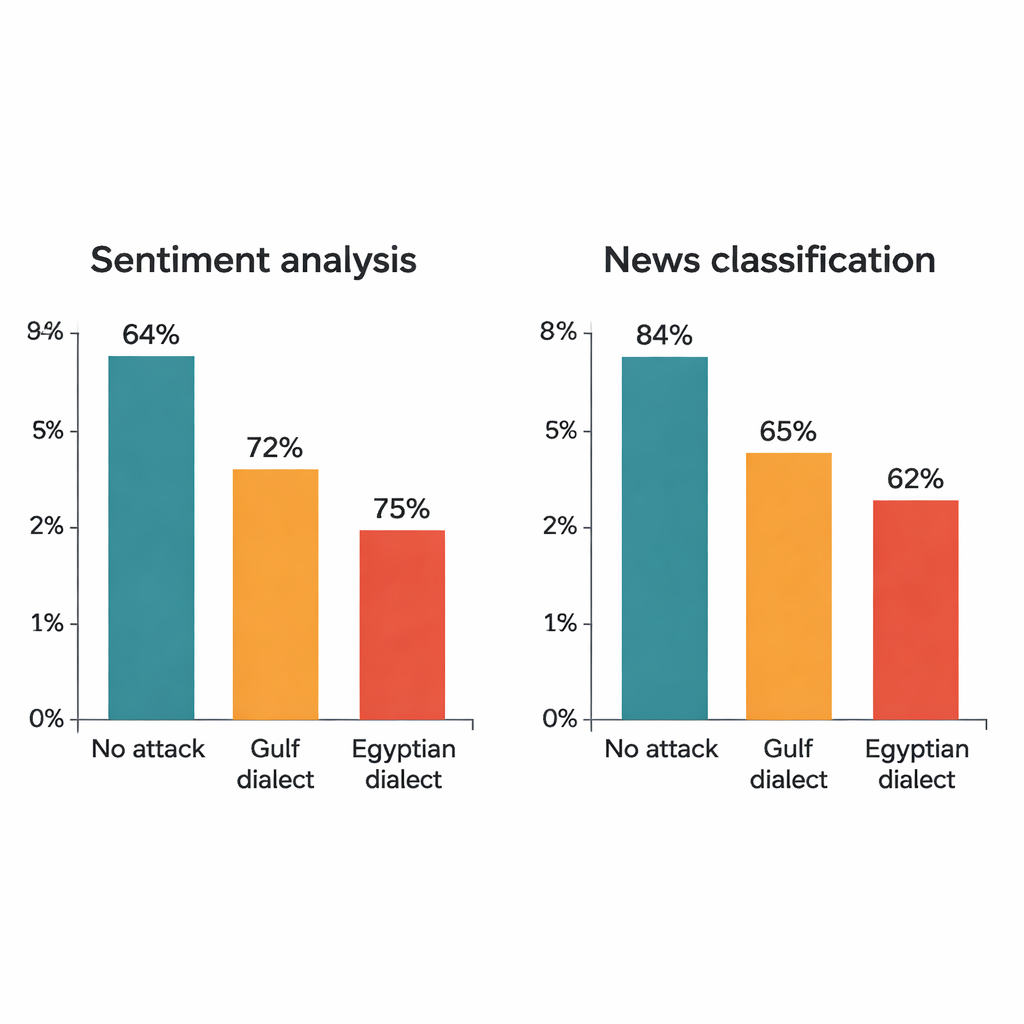
O estudo ataca quatro modelos de deep learning bem conhecidos: dois grandes transformadores (AraBERT e CAMeLBERT) e duas redes menores (um modelo convolucional e um LSTM bidirecional). Eles são treinados em dois grandes conjuntos de MSA: avaliações de hotéis para análise de sentimento e artigos de notícias para classificação de tópicos. De cada conjunto de teste, o autor extrai 1.280 exemplos e aplica o procedimento de substituição dialetal. Mesmo que apenas uma palavra em cada frase seja alterada, o impacto é notável. Nas avaliações de hotéis, a acurácia do AraBERT cai de 94% no texto limpo para cerca de 72% com substituições do Golfo e 65% com as egípcias. O CAMeLBERT cai ainda mais, para aproximadamente 63% e 55%. Classificadores de notícias também sofrem: o modelo convolucional perde cerca de 18 a 22 pontos percentuais, e o LSTM mostra declínios semelhantes.
O que dá errado dentro dos modelos
Uma análise mais detalhada revela que as palavras mais vulneráveis coincidem com o que as pessoas realmente leem no texto. Em avaliações de hotéis, quase metade das palavras alvo são adjetivos como “bom” ou “terrível”, que carregam peso emocional claro. Em artigos de notícias, a maioria das palavras selecionadas são substantivos e nomes que sinalizam tópicos como política, esportes ou finanças. Quando essas palavras-chave são trocadas por formas dialetais, modelos treinados apenas em MSA frequentemente deixam de reconhecê-las. Modelos transformadores mostram-se especialmente frágeis: sua dependência em fragmentos sublexicais e a atenção a poucos tokens altamente ponderados tornam uma única palavra dialetal suficiente para reverter uma previsão. Modelos menores, que distribuem atenção de forma mais uniforme pela frase, ainda são enganados, mas se mostram um pouco mais robustos.
Egípcio versus Golfo: nem todos os dialetos são iguais
Os ataques também mostram que o árabe egípcio tende a desestabilizar os modelos mais do que o árabe do Golfo. Estudos linguísticos corroboram isso: as variedades do Golfo frequentemente permanecem mais próximas do MSA no vocabulário e na estrutura, enquanto o árabe egípcio absorveu formas mais distintas ao longo da história e por contato com outras línguas. Como resultado, substituições do Golfo às vezes se assemelham o suficiente ao original em MSA para que o modelo ainda consiga lidar com elas, enquanto substituições egípcias têm mais chances de ficar fora do que o modelo já viu. Testes estatísticos confirmam que as quedas de desempenho observadas não são aleatórias — refletem pontos cegos sistemáticos em como os sistemas atuais lidam com a diglossia árabe.
O que isso significa para a IA em árabe
Para usuários do dia a dia, a conclusão é simples: a IA em árabe de hoje pode ser facilmente confundida por palavras dialetais ordinárias, mesmo quando os humanos acham o texto perfeitamente claro. Um único termo dialetal em uma avaliação de hotel pode inverter o julgamento de um modelo de positivo para negativo, ou rotular incorretamente o tópico de uma notícia. Para pesquisadores e desenvolvedores, a mensagem é um chamado para construir sistemas “sensíveis à diglossia” que sejam treinados tanto em MSA quanto em dialetos regionais, e para usar testes de estresse realistas como a substituição dialetal ao avaliar a robustez. Até lá, qualquer aplicação que presuma “árabe é só MSA” corre o risco de graves mal-entendidos no mundo real.
Citação: Alshemali, B. Dialectal substitution as an adversarial approach for evaluating Arabic NLP robustness. Sci Rep 16, 5996 (2026). https://doi.org/10.1038/s41598-026-36252-4
Palavras-chave: PNL em árabe, variação dialetal, exemplos adversariais, análise de sentimento, classificação de texto