Clear Sky Science · pt
Modelagem de contexto de longo alcance para detecção de vulnerabilidades de software usando uma abordagem baseada em XLNet
Por que falhas ocultas em software importam
A vida moderna depende de software, desde sistemas bancários online e hospitais até players de vídeo e aplicativos de chat. Ainda assim, até pequenos erros no código podem abrir portas para invasores, colocando em risco roubo de dados ou interrupções de serviço. Especialistas em segurança recorrem cada vez mais à inteligência artificial para vasculhar milhões de linhas de código em busca dessas fraquezas. Este artigo explora um novo método baseado em IA, chamado XLNetVD, projetado para identificar vulnerabilidades sutis de software lendo trechos de código muito maiores do que muitas ferramentas existentes conseguem processar.
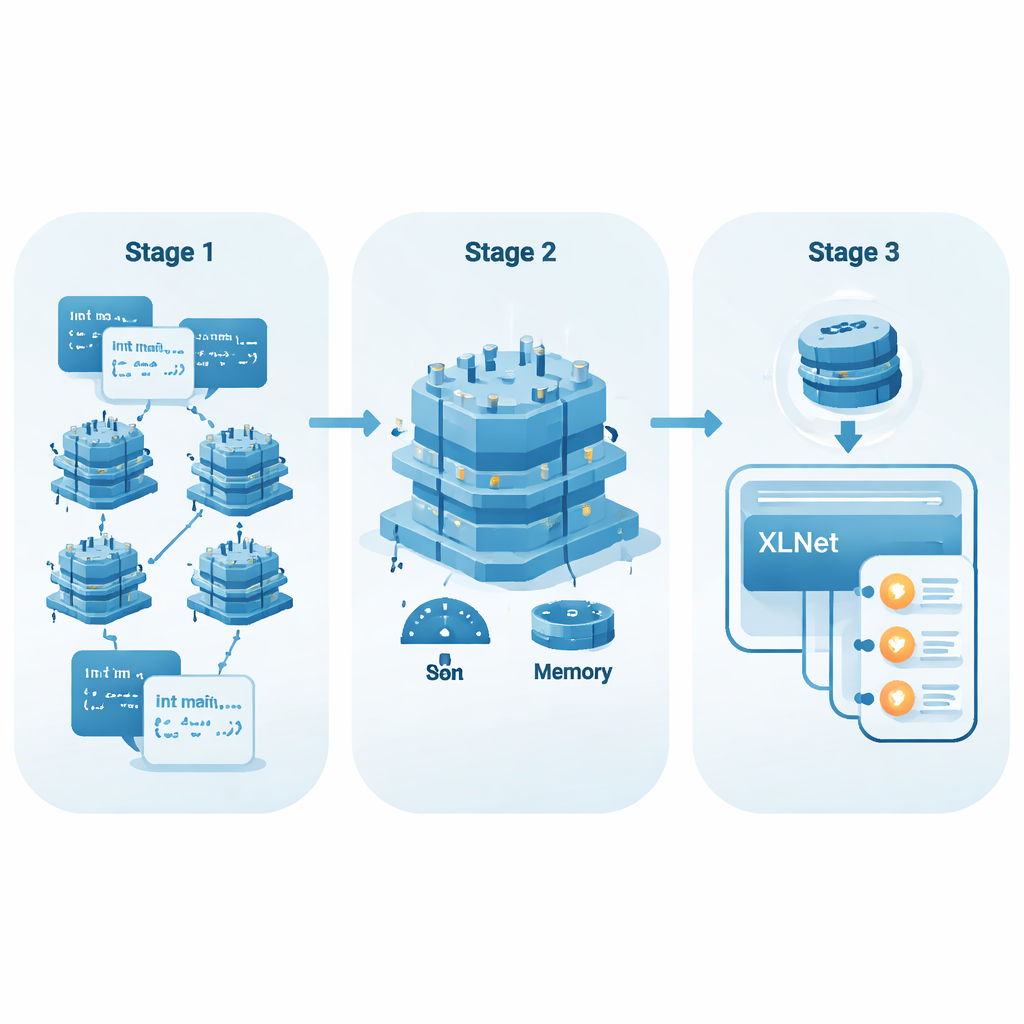
De listas de palavras simples para código que entende contexto
Métodos iniciais de IA para analisar código tratavam cada token — como um nome de variável ou símbolo — quase como uma palavra de dicionário com significado fixo. Técnicas como Word2Vec ou GloVe aprendiam um vetor por token, independentemente de onde aparecesse. Isso funciona razoavelmente bem para linguagem natural, mas fica aquém para programas, onde o mesmo nome de variável pode se comportar de maneiras muito diferentes dependendo de onde e como é usado. Modelos mais recentes, conhecidos como modelos de embedding contextual, passam a analisar a função inteira de uma só vez e ajustam a representação de cada token conforme seu entorno. Isso permite captar padrões relacionados ao fluxo de dados, fluxo de controle e dependências entre variáveis — padrões que frequentemente determinam a diferença entre código seguro e inseguro.
Deixar a IA ler mais do arquivo
Modelos de código populares como CodeBERT e GraphCodeBERT já usam essa abordagem sensível ao contexto, mas tipicamente limitam sua “visão” a cerca de 512 tokens. Para funções longas, ou para vulnerabilidades que são insinuadas em partes do código amplamente separadas, essa janela pode ser curta demais. Verificações importantes no início de uma função podem ficar desconectadas de operações arriscadas no final. Os autores, em vez disso, constroem sobre o XLNet, um modelo baseado no Transformer-XL, que pode lembrar informações através de segmentos e processar sequências mais longas confortavelmente (até 768 tokens em seus experimentos). Isso o torna mais apto a vincular eventos distantes no código — por exemplo, entender que um valor foi validado anteriormente, ou perceber que nunca foi.
Tornando modelos poderosos mais leves e rápidos
Modelos de IA grandes costumam exigir hardware robusto, o que limita seu uso em ambientes de desenvolvimento cotidianos. Para contornar isso, os autores aplicam um método de fine-tuning chamado Low-Rank Adaptation (LoRA). Em vez de alterar todos os numerosos parâmetros do XLNet, o LoRA adiciona pequenas camadas adaptadoras que são muito mais baratas de treinar e armazenar. A equipe introduz uma métrica simples, EffScore, que pondera quanto de memória e tempo são economizados em relação a qualquer queda na qualidade de detecção. Entre vários modelos de ponta, o XLNet com LoRA surge como o mais eficiente no conjunto, oferecendo boa acurácia ao usar recursos significativamente menores.
Testes em projetos reais e sintéticos
Os pesquisadores avaliam o XLNetVD em dois conjuntos de dados bastante diferentes. Um consiste em código C real de 12 projetos open-source — como bibliotecas de mídia e servidores web — com uma razão extremamente desequilibrada de cerca de 1 função vulnerável para 65 não vulneráveis, refletindo a realidade de grandes bases de código. O outro é uma coleção sintética balanceada do projeto SARD, onde cada função é construída para representar um tipo conhecido de fraqueza. O XLNetVD não apenas iguala ou supera sistemas de aprendizado profundo anteriores e ferramentas clássicas de análise estática nesses testes, como também se sai bem em cenários cross-project, onde precisa encontrar falhas em um projeto que não viu antes. Sua vantagem é especialmente forte para funções longas, onde contexto estendido é crucial, e através de várias categorias de vulnerabilidades, incluindo estouros de inteiro, má gestão de recursos e tratamento inadequado de entrada.
O que isso significa para a segurança de software no dia a dia
Para um não especialista, a mensagem principal é que IA mais inteligente e sensível ao contexto pode ler e raciocinar sobre código de forma mais próxima a um revisor humano experiente, mas em escala de máquina. Ao permitir que o modelo veja mais de cada função e ajustá-lo de forma eficiente, o XLNetVD oferece uma maneira prática de priorizar quais partes de uma grande base de código merecem inspeção humana mais atenta. Não substitui auditorias de segurança manuais nem métodos formais, e não pode garantir que o software esteja livre de bugs. No entanto, melhora substancialmente as chances de detectar erros perigosos cedo, mesmo em projetos desconhecidos, tornando-se um componente promissor para uma infraestrutura digital mais confiável e segura.
Citação: Zhao, Y., Lin, G. & Liao, Z. Long-range context modeling for software vulnerability detection using an XLNet-based approach. Sci Rep 16, 5338 (2026). https://doi.org/10.1038/s41598-026-36196-9
Palavras-chave: vulnerabilidades de software, segurança de código, aprendizado profundo, XLNet, fine-tuning LoRA