Clear Sky Science · pt
Algoritmo DDPG priorizado modificado para otimização conjunta de beamforming e fase de RIS em sistemas MISO downlink
Superfícies inteligentes para a próxima onda de comunicações sem fio
À medida que nossos telefones, carros e sensores exigem conexões cada vez mais rápidas e confiáveis, as redes sem fio atuais são levadas ao limite. Este estudo explora uma nova forma de tornar as redes 6G do futuro mais verdes e mais confiáveis, combinando superfícies refletoras “inteligentes” em edifícios com uma técnica de inteligência artificial que aprende por conta própria a direcionar sinais de rádio usando menos energia.
Transformando paredes em espelhos úteis para sinais
Os sistemas 6G futuros precisarão atender a um enorme número de dispositivos com altas taxas de dados, confiabilidade sólida e latência muito baixa. Atender a todas essas exigências apenas com estações base tradicionais exigiria muito hardware e muita energia. Superfícies Inteligentes Reconfiguráveis (RIS) oferecem uma abordagem diferente: painéis revestidos com muitos elementos minúsculos e de baixo consumo que podem refletir ondas de rádio recebidas em direções controladas, como um espelho programável. Ao escolher cuidadosamente as fases dessas reflexões, um RIS pode redirecionar sinais em torno de obstáculos, fortalecer enlaces fracos e reduzir interferências, tudo isso sem transmitir potência ativa própria. Isso dá aos projetistas de rede um novo e poderoso controle para ampliar cobertura e melhorar a eficiência.
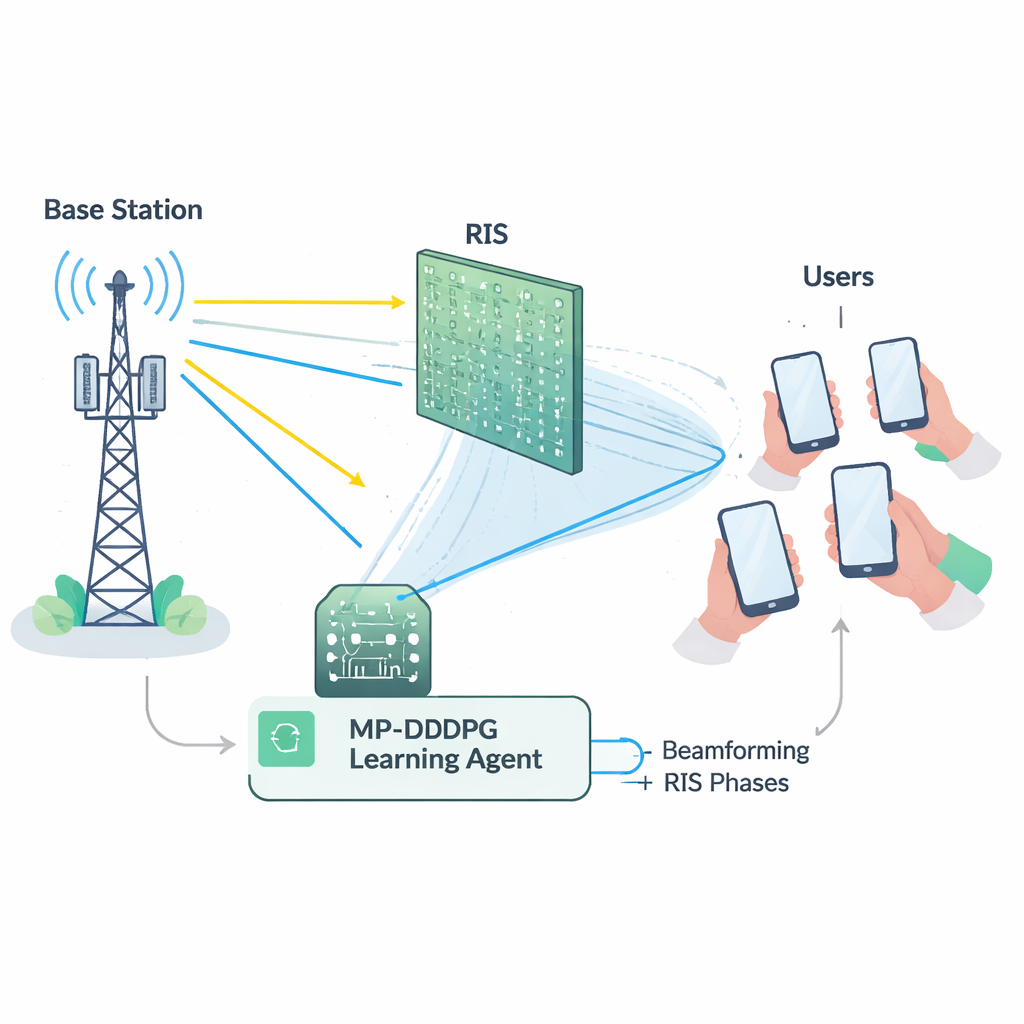
Um delicado ato de equilíbrio para a rede
Fazer bom uso de um RIS não é simples. A estação base precisa decidir como apontar suas antenas (beamforming), enquanto o RIS deve ajustar a fase de cada um de seus numerosos elementos refletivos. Essas escolhas estão fortemente interligadas e precisam respeitar vários limites ao mesmo tempo: manter a potência total de transmissão abaixo de um máximo, garantir a cada usuário uma qualidade de sinal mínima e observar limites físicos do hardware do RIS. Matematicamente, esse problema de ajuste conjunto é altamente não linear e “não convexo”, o que significa que ferramentas de otimização convencionais tendem a ser lentas, frágeis ou ficarem presas em soluções subótimas, especialmente conforme as redes crescem. Além disso, medir com precisão o estado detalhado de cada enlace de rádio (a chamada informação de estado do canal) é em si custoso e sujeito a erros em implantações reais.
Deixando um agente de IA aprender a fazer beam
Para superar esses obstáculos, os autores constroem um agente de aprendizado usando aprendizado profundo por reforço, um ramo da IA em que um agente descobre boas estratégias por tentativa e erro em um ambiente. O método deles, chamado DDPG Determinístico Profundo Prioritário Modificado (MP‑DDPG), observa o estado atual da rede — direções de feixe anteriores, configurações do RIS, potência recebida e qualidade do sinal — e então escolhe novos valores de beamforming e de fase do RIS. Após cada escolha, recebe uma recompensa que incentiva três objetivos simultâneos: menor potência de transmissão, atendimento das metas de qualidade de serviço para os usuários e respeito ao limite de potência da estação base. Ao longo de muitas interações simuladas, o agente gradualmente aprende uma política de controle que equilibra essas metas sem que lhe seja explicitamente dada qualquer fórmula do canal de rádio.
Aprendendo mais rápido ao focar no que importa
A inovação chave está em como o algoritmo aprende a partir de experiências passadas. Abordagens padrão armazenam muitas situações anteriores e as amostram aleatoriamente durante o treinamento, o que pode ser ineficiente e lento. MP‑DDPG em vez disso atribui a cada experiência armazenada uma prioridade que depende tanto da recompensa quanto de quão diferente seu estado é em relação aos vizinhos mais próximos. Experiências que são informativas e diversas são amostradas com mais frequência, enquanto as redundantes são ignoradas. Essa “replay priorizado modificado” torna cada passo de aprendizado mais útil, acelerando a convergência e ajudando o agente a evitar soluções locais pobres. Os autores também analisam o custo computacional adicional que isso traz e mostram que, embora a administração seja mais complexa do que no método básico, o aprendizado mais rápido compensa essa sobrecarga na prática.
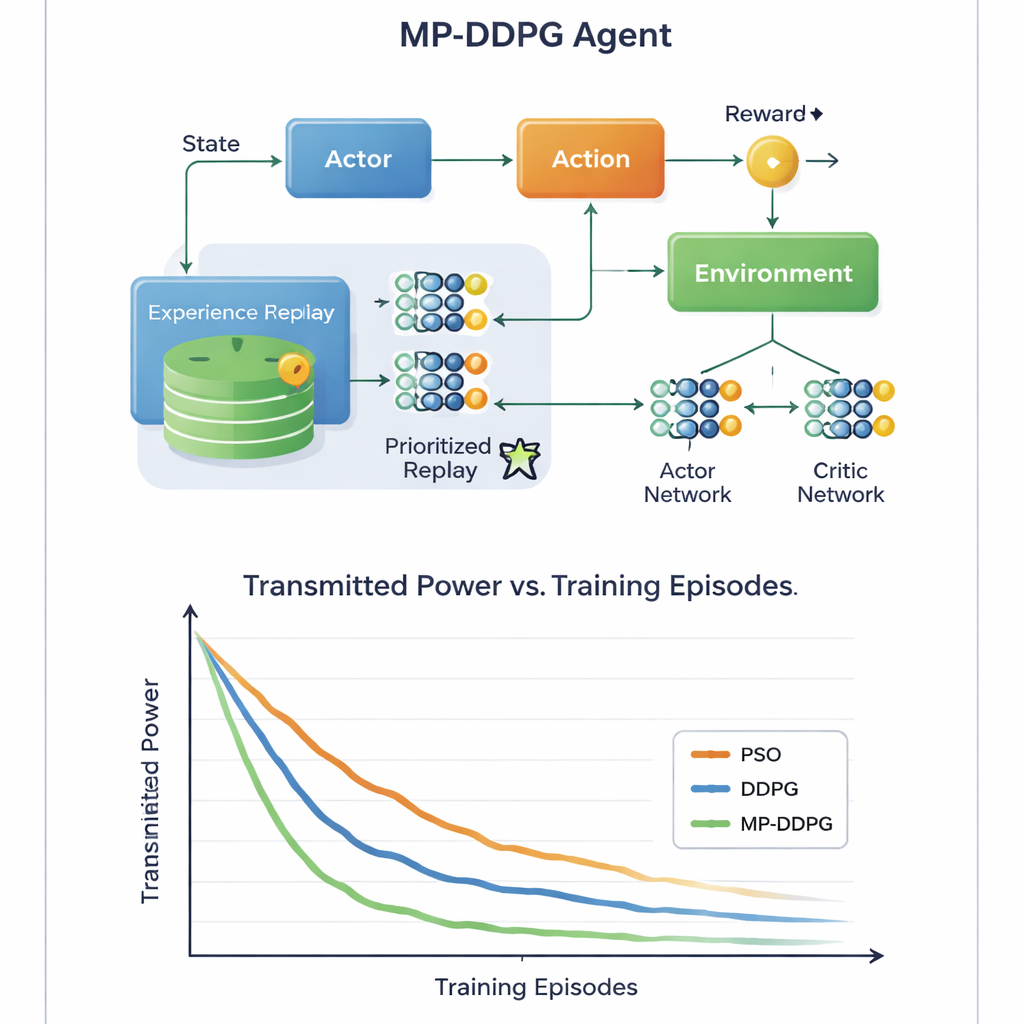
Sinais mais verdes com menos hardware
Através de simulações detalhadas de computador de um cenário celular downlink, o estudo compara MP‑DDPG com duas alternativas: um método tradicional de otimização por enxame de partículas e o algoritmo DDPG original. O novo método constantemente alcança potência de transmissão menor em menos episódios de treinamento, e faz isso usando menos elementos do RIS e menos antenas na estação base para o mesmo nível de desempenho. Em termos simples, a rede aprende a extrair mais benefício de cada placa refletora e de cada antena. Para um leitor leigo, a mensagem é que, ao permitir que um controlador de IA ajuste inteligentemente tanto os feixes da estação base quanto as superfícies inteligentes em paredes próximas, as redes 6G do futuro poderiam entregar sinais fortes e confiáveis usando menos energia e menos hardware, ajudando a tornar nosso mundo cada vez mais conectado mais sustentável.
Citação: Shukry, S., Fahmy, Y. Modified prioritized DDPG algorithm for joint beamforming and RIS phase optimization in MISO downlink systems. Sci Rep 16, 5942 (2026). https://doi.org/10.1038/s41598-026-36179-w
Palavras-chave: superfície inteligente reconfigurável, 6G sem fio, aprendizado profundo por reforço, otimização de beamforming, redes energeticamente eficientes