Clear Sky Science · pt
Previsão por aprendizado de máquina de dependência alimentar em estudantes universitários usando características demográficas, antropométricas e de personalidade
Por que nossa relação com a comida pode parecer fora de controle
Muitas pessoas brincam que são “viciadas” em chocolate ou fast food, mas para algumas, os desejos e a perda de controle em relação à alimentação são sérios e angustiantes. Estudantes universitários são especialmente vulneráveis, conciliando estresse, novas liberdades e mudanças corporais. Este estudo faz uma pergunta atual: programas de computador podem aprender a identificar quais estudantes estão em maior risco de dependência alimentar usando informações simples sobre histórico, medidas corporais e personalidade? Se sim, poderíamos um dia detectar problemas mais cedo e ajustar o suporte antes que os hábitos alimentares se transformem em questões de saúde de longo prazo.
Analisando os estudantes por múltiplos ângulos
Os pesquisadores trabalharam com 210 estudantes universitários em Ahvaz, Irã, com idades entre 18 e 35 anos. Cada estudante forneceu detalhes básicos, como idade e nível educacional, informou altura e peso para que o índice de massa corporal (IMC) pudesse ser calculado, e respondeu a um questionário padrão de personalidade. Também foram avaliados com uma versão breve da Yale Food Addiction Scale, que classifica se alguém apresenta padrões semelhantes aos de dependência em relação a alimentos altamente palatáveis, como desejos intensos, tentativas fracassadas de reduzir o consumo ou comer apesar de consequências negativas. Apenas 30 estudantes atenderam aos critérios de dependência alimentar, enquanto 180 não, refletindo como tais problemas afetam uma parcela menor da população.
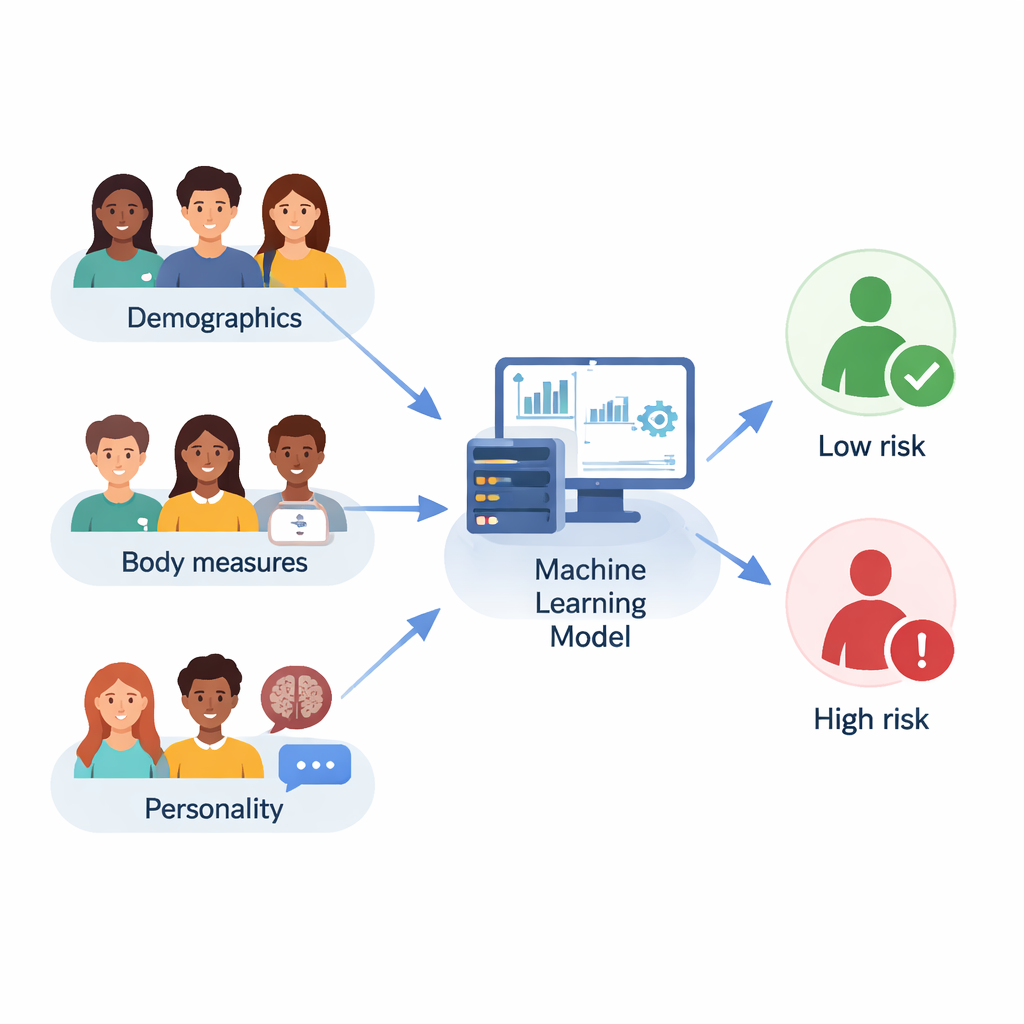
Equilibrando dados desbalanceados e treinando máquinas inteligentes
Como muito menos estudantes foram classificados como dependentes alimentares, o conjunto de dados ficou desequilibrado. Esse desbalanceamento pode levar modelos computacionais a predizerem majoritariamente o grupo majoritário e a ignorarem a minoria de alto risco. Para combater isso, a equipe usou dois truques de tratamento de dados. Primeiro, aplicaram um método chamado Tomek Links para remover cuidadosamente casos do grupo majoritário que estavam muito próximos dos casos minoritários e geravam confusão. Em seguida usaram SMOTE, que cria exemplos sintéticos realistas do grupo minoritário, para equilibrar os números. Apenas os dados de treinamento foram alterados dessa forma; um conjunto de teste separado e intacto foi reservado para verificar quão bem os modelos se saíam em novos estudantes não vistos.
Testando muitos algoritmos
Os pesquisadores não confiaram em uma única receita matemática. Em vez disso, compararam dez modelos diferentes de aprendizado de máquina, desde métodos simples como regressão logística e k‑nearest neighbors até métodos “ensemble” mais avançados, como Random Forest, Gradient Boosting, LightGBM e CatBoost. Também testaram doze estratégias de seleção de características para decidir quais perguntas e medidas eram mais informativas, e usaram validação cruzada e buscas automatizadas para ajustar os parâmetros de cada modelo. O desempenho geral foi avaliado usando várias medidas, incluindo acurácia (com que frequência o modelo estava certo), F1‑score (um equilíbrio entre detectar casos verdadeiros sem muitos falsos positivos) e a área sob a curva ROC, que captura quão bem um modelo separa indivíduos de maior risco dos de menor risco.
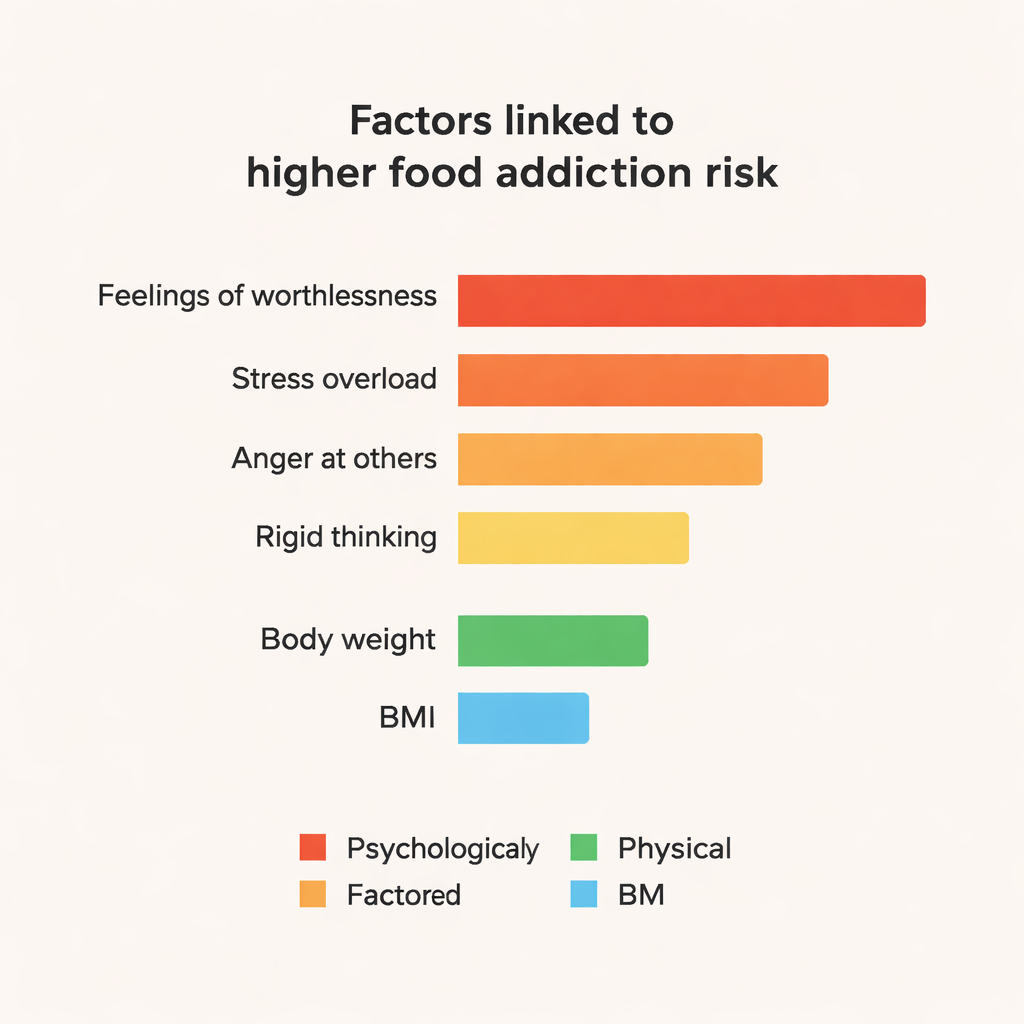
O que impulsiona as previsões por baixo do capô
Modelos ensemble, especialmente CatBoost e Random Forest, superaram consistentemente abordagens mais simples, alcançando cerca de 84% de acurácia e F1‑scores em torno de 0,84 neste pequeno conjunto de dados. Para ir além de previsões em “caixa‑preta”, a equipe usou uma ferramenta chamada SHAP para explorar quais características empurravam o modelo a rotular alguém como dependente alimentar. As influências de destaque foram psicológicas: afirmações fortes como “Às vezes me sinto completamente inútil”, sentir‑se como se estivesse “desmoronando” sob estresse, raiva frequente pela forma como os outros o tratam, tensão emocional e pensamento rígido e inflexível. Peso corporal e IMC também importaram, mas foram menos centrais do que esses sinais ligados à emoção e à personalidade. Traços associados a bom humor e boa organização mostraram um efeito protetor leve.
O que isso significa para a vida cotidiana
Para o leitor comum, a mensagem principal é que dependência alimentar não é simplesmente uma questão de força de vontade ou gostar de petiscos saborosos. Neste grupo piloto de estudantes, dificuldades emocionais mais profundas — baixa autoestima, dificuldade em lidar com o estresse e relacionamentos conturbados — estiveram fortemente entrelaçadas com padrões alimentares problemáticos. Versões iniciais de ferramentas de aprendizado de máquina, alimentadas por questionários básicos e medidas corporais, foram capazes de perceber esses padrões com acurácia encorajadora. No entanto, os autores enfatizam que a amostra foi pequena, baseada em autorrelatos e proveniente de uma única universidade, portanto os resultados são preliminares. Com estudos maiores e mais diversos, modelos semelhantes poderiam, eventualmente, ser usados ao lado de avaliações clínicas padrão para sinalizar jovens que poderiam se beneficiar de apoio para manejar tanto as emoções quanto os hábitos alimentares.
Citação: Rahimnezhad, A., Mortazavi, S.T., Behdarvand, Y. et al. Machine learning prediction of food addiction in university students using demographic, anthropometric and personality traits. Sci Rep 16, 6745 (2026). https://doi.org/10.1038/s41598-026-36162-5
Palavras-chave: dependência alimentar, estudantes universitários, traços de personalidade, aprendizado de máquina, alimentação emocional