Clear Sky Science · pt
Integração de otimização e aprendizado de máquina para estimar resistividade da água e saturação em reservatórios de arenitos xistosos
Por que isso importa para energia e meio ambiente
Empresas de óleo e gás dependem de medições feitas ao longo de um poço para decidir onde os hidrocarbonetos estão e se um campo vale a pena ser desenvolvido. Em muitos reservatórios, especialmente os ricos em argila e silte, essas medições são notoriamente difíceis de interpretar, de modo que os engenheiros podem subestimar quanto petróleo ou gás realmente existe. Este estudo apresenta uma nova maneira de extrair informações mais confiáveis dos dados existentes combinando otimização baseada em física com aprendizado de máquina moderno, potencialmente melhorando a recuperação ao mesmo tempo que reduz a necessidade de amostras de testemunho caras.
O problema das rochas lamacentas
Muitos dos reservatórios de hidrocarbonetos do mundo são “arenitos xistosos” – misturas de grãos de areia, fluidos de poro e minerais de argila condutivos. Essas argilas distorcem as medições elétricas usadas para estimar quanto do espaço poroso da rocha está preenchido por água versus hidrocarbonetos. Ferramentas e gráficos clássicos, desenvolvidos para areias mais limpas, assumem estruturas rochosas simples e pouca argila. Em arenitos xistosos, essas suposições se quebram, frequentemente fazendo as rochas parecerem mais encharcadas do que realmente são e levando engenheiros a desconsiderar intervalos que podem, na verdade, conter volumes significativos de petróleo ou gás.
Transformando medições esparsas em uma âncora sólida
Os autores enfrentam uma quantidade central chamada resistividade da água de formação, que descreve quão bem a água nos poros conduz eletricidade. Se esse valor estiver incorreto, toda estimativa subsequente de saturação de água fica enviesada. Em vez de confiar em algumas medições de laboratório ou em métodos gráficos subjetivos, eles formulam o problema como uma tarefa de otimização: encontrar o único valor de resistividade da água que faz um modelo físico de arenito xistoso ajustar-se melhor à resistividade medida ao longo do poço. Eles testam vários algoritmos de busca e mostram que métodos simples e sem derivadas, como Powell e Nelder–Mead, conseguem recuperar a verdadeira resistividade da água com erro extremamente pequeno quando comparados a dados de testemunhos e amostras de água de 11 poços no Mar do Norte norueguês e no Deserto Ocidental do Egito.
Criando um registro “pseudo-testemunho” para aprendizado de máquina
Uma vez que essa resistividade da água otimizada é determinada, o mesmo modelo físico é usado para calcular um perfil contínuo de saturação de água ao longo de cada poço. Esse perfil é tratado como um rótulo de alta qualidade, informado pela física — uma espécie de “pseudo-testemunho” — que existe em todas as profundidades, não apenas em alguns intervalos amostrados. Os pesquisadores então alimentam registros padrão de poço, como raios gama, porosidade por nêutrons, densidade e resistividade profunda, em uma ampla gama de modelos de aprendizado de máquina. Estes incluem ensembles baseados em árvores (Random Forest, XGBoost, CatBoost), máquinas de vetores de suporte e várias arquiteturas de redes neurais, incluindo uma rede recorrente especial chamada LSTM que pode reconhecer padrões que evoluem com a profundidade. Pré-processamento cuidadoso, triagem de outliers e normalização ajudam a garantir que os modelos aprendam relações geológicas reais em vez de ruído.
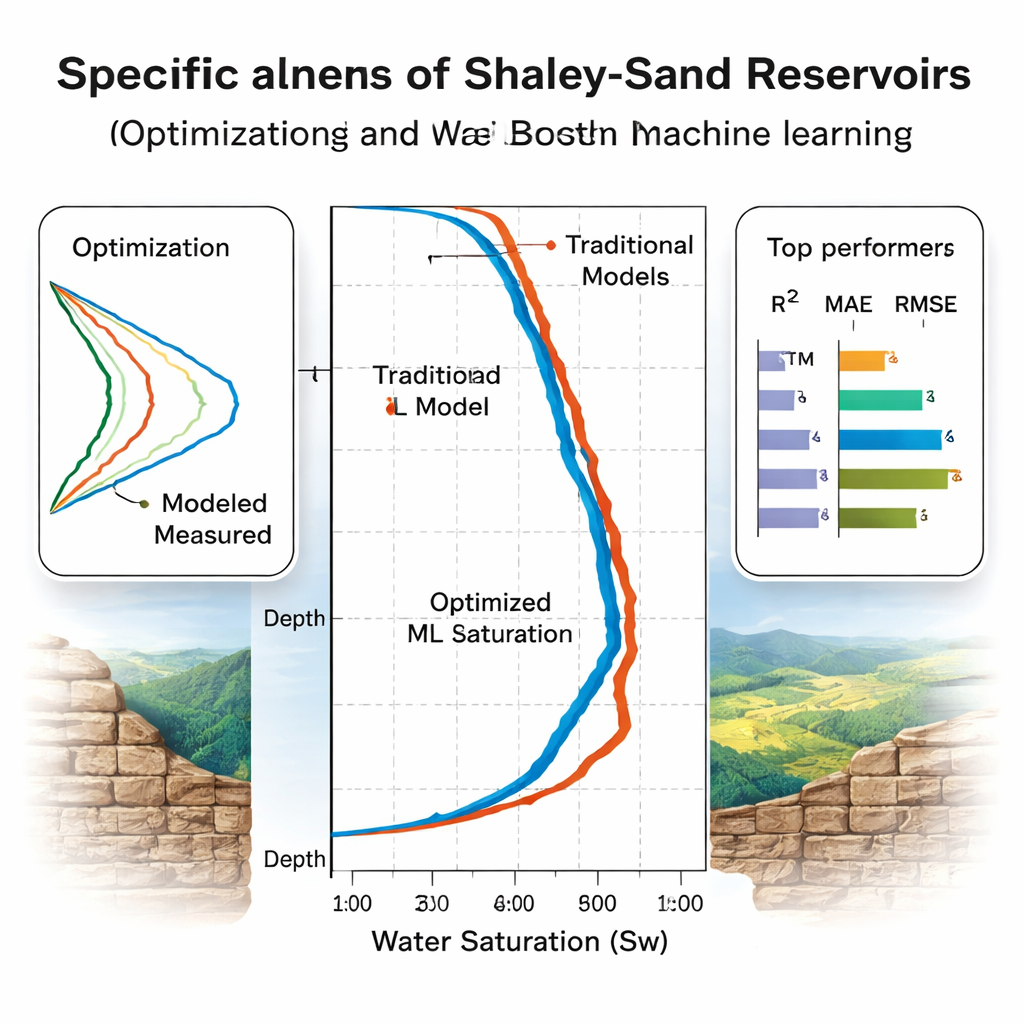
Quais modelos realmente generalizam?
A equipe avalia os modelos em duas etapas. Primeiro, eles usam validação cruzada em cinco partes em oito poços do Mar do Norte para ajustar e ranquear os modelos, constatando que o Random Forest parece vencer nas métricas de acurácia padrão. Depois vem o teste mais revelador: três poços “cegos”, incluindo dois de uma bacia egípcia geologicamente diferente que nunca foram usados no treinamento. Aqui, alguns modelos tropeçam. O desempenho do Random Forest cai, sinalizando sobreajuste à bacia original. Em contraste, árvores com gradiente impulsionado (CatBoost e XGBoost) e as redes LSTM e redes neurais com regularização Bayesiana mantêm alta acurácia, explicando mais de 93–94% da variação na saturação de água com erros modestos. A análise de importância de características usando SHAP, uma ferramenta moderna de interpretabilidade, confirma que os modelos dependem principalmente de entradas fisicamente sensatas, como resistividade, porosidade e volume de xisto.
O que isso significa em termos simples
Para não especialistas, a ideia central é que os autores primeiro usam a física para limpar e ancorar o problema, e só então aplicam aprendizado de máquina. Ao deixar que uma rotina de otimização encontre a resistividade da água que melhor se ajusta e transformar isso em um conjunto de treinamento denso e compatível com a física, eles evitam o gargalo usual de dados de testemunho escassos e caros. Seus resultados mostram que essa abordagem “otimização primeiro, ML depois” pode fornecer estimativas confiáveis de quanto de um reservatório xistoso está preenchido por água versus hidrocarbonetos, mesmo em bacias novas não usadas no treinamento. Em termos práticos, isso pode ajudar os operadores a mapear zonas produtoras com mais confiabilidade, reduzir sondagens desnecessárias e melhorar estimativas de hidrocarbonetos in situ — tudo isso usando de forma mais inteligente os dados que já estão coletando.
Citação: Hameedy, M.A.E., Mabrouk, W.M. & Metwally, A.M. Integrating optimization and machine learning for estimating water resistivity and saturation in shaley sand reservoirs. Sci Rep 16, 6342 (2026). https://doi.org/10.1038/s41598-026-36133-w
Palavras-chave: reservatórios de arenitos xistosos, saturação de água, resistividade da água de formação, aprendizado de máquina em petrofísica, caracterização de reservatórios