Clear Sky Science · pt
Fusão de recursos espaço-temporais guiada por atenção para detecção robusta de anomalias em vigilância por vídeo
Por que câmeras mais inteligentes importam
De estações de trem movimentadas a shoppings, a vida moderna está repleta de câmeras de segurança que gravam silenciosamente tudo o que acontece. Ainda assim, a maior parte desses vídeos é examinada — quando é que é — por olhos humanos cansados que facilmente podem perder um momento crucial. Este artigo explora um novo tipo de sistema de vigilância “inteligente” que pode identificar automaticamente comportamentos incomuns ou de risco, como furtos ou vandalismo, em tempo real, ao compreender tanto o que aparece em uma cena quanto como isso muda ao longo do tempo.

Vendo mais do que pixels
Um fluxo de câmera tradicional é apenas uma sequência de imagens. Sistemas antigos tentavam detectar problemas analisando cada quadro separadamente, procurando formas e contornos que lembrassem pessoas ou objetos. Os autores primeiro testam uma versão moderna dessa ideia que usa uma rede compacta de reconhecimento de imagens combinada com detectores clássicos de borda. Essa configuração funciona razoavelmente bem em cenas bem enquadradas, especialmente para notar sinais visuais claros, como alguém agarrando um item. Mas, por focar em instantâneos isolados, ela tem dificuldade quando pessoas se bloqueiam mutuamente, quando multidões ficam densas ou quando a mesma postura pode significar comportamento normal ou suspeito dependendo de como se desenrola ao longo do tempo.
Entendendo movimento e comportamento
Para capturar a história por trás de uma ação, e não apenas a aparência de um único quadro, o estudo avalia então um modelo focado em vídeo que analisa clipes curtos em vez de imagens estáticas. Esse modelo aprende como o movimento flui por vários quadros e consegue identificar melhor mudanças súbitas, como correr, briga ou um arranco. Ele se mostra eficaz em capturar muitos eventos anômalos, o que leva a alta sensibilidade. Entretanto, também sofre de um problema clássico do mundo real: eventos realmente incomuns são raros comparados à atividade cotidiana. Como resultado, o modelo pode ficar instável, gerando muitos falsos positivos e exigindo segmentos de vídeo cuidadosamente pré-recortados que não refletem a natureza bagunçada e contínua das filmagens de vigilância reais.
Misturando onde e quando
Com base nos pontos fortes e fracos dessas duas abordagens de referência, os autores propõem um novo sistema híbrido chamado HybridModel-1, que busca “pensar” tanto no espaço quanto no tempo ao mesmo tempo. Ele combina uma rede muito boa em entender quais objetos estão presentes em cada quadro com um detector rápido que localiza esses objetos na cena. Um módulo especial de fusão aprende a enfatizar os detalhes visuais mais informativos — como pessoas e objetos-chave — enquanto minimiza o ruído de fundo, como paredes, árvores ou carros passando. Ao mesmo tempo, uma nova estratégia de treinamento pune suavemente o sistema sempre que sua confiança salta bruscamente de um quadro para o outro, incentivando decisões mais suaves e consistentes ao longo de todo o vídeo.
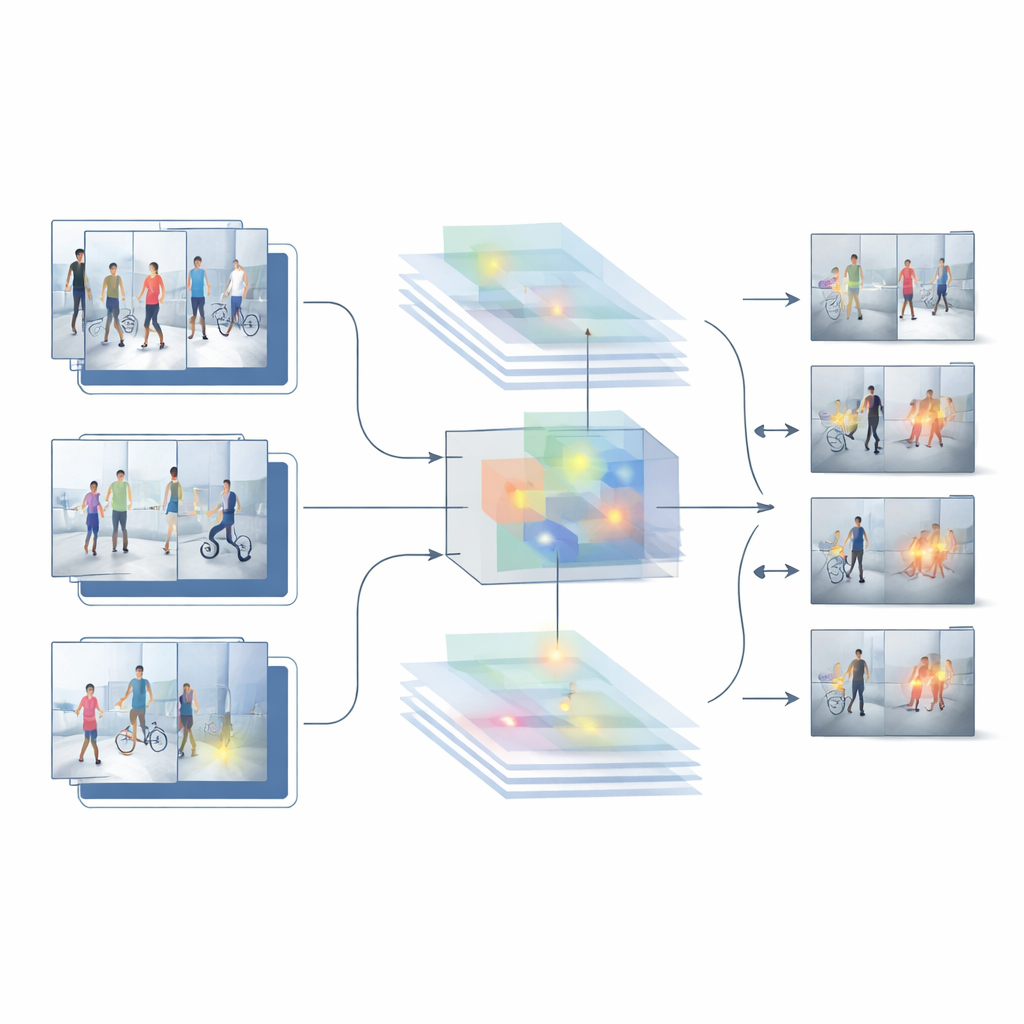
Colocando o sistema à prova
Para verificar se esse projeto funciona fora do laboratório, os pesquisadores o testam em vários conjuntos de dados públicos desafiadores com filmagens de vigilância reais. Essas coleções incluem desde cenas de furtos em ambientes internos até calçadas de campi externos, com posições de câmera, iluminação, tamanhos de público e tipos de incidentes variados. Nesses benchmarks, o modelo híbrido supera tanto as referências apenas com imagens quanto as apenas com vídeo. Ele alcança maior precisão geral, gera muito menos alarmes falsos e mantém desempenho forte mesmo quando avaliado em filmagens nas quais não foi treinado. Comparações detalhadas e estudos de ablação — nos quais partes do sistema são removidas ou alteradas — mostram que o módulo de fusão de recursos e a etapa de treinamento focada em suavidade contribuem de forma significativa para esses ganhos.
O que isso significa para a segurança cotidiana
Em termos simples, este trabalho mostra que sistemas de vigilância ficam mais confiáveis quando aprendem a prestar atenção às partes certas de uma cena e a manter consistência em seus julgamentos ao longo do tempo. Em vez de tratar cada quadro como uma imagem isolada ou confiar apenas no movimento bruto, a abordagem proposta combina “o quê” e “quando” em uma única estrutura cuidadosamente ajustada. Embora desafios permaneçam em visões extremamente escuras ou fortemente obstruídas, os resultados sugerem um caminho prático rumo a redes de câmeras que podem filtrar silenciosamente grandes volumes de vídeo, destacar eventos genuinamente suspeitos e reduzir a carga de falsos alarmes para operadores humanos. Para o público, isso pode significar espaços mais seguros monitorados por sistemas que não estão apenas observando, mas realmente entendendo o que veem.
Citação: Nivethika, S.D., Joshi, S., Verma, K. et al. Attention-guided saptio-temporal feature fusion for robus video surveillance anomaly detection. Sci Rep 16, 8027 (2026). https://doi.org/10.1038/s41598-026-36130-z
Palavras-chave: vigilância por vídeo, detecção de anomalias, câmeras inteligentes, detecção de crimes, aprendizado de máquina