Clear Sky Science · pt
Integração de regressão krigagem baseada em Random Forest para analisar a variabilidade espacial da chuva em regiões áridas e semiáridas
Por que mapear a chuva em terras secas importa
Em países onde a água é escassa, saber exatamente onde e quando chove pode ser a diferença entre segurança alimentar e crise. O Paquistão abrange montanhas, desertos e planícies férteis, e suas precipitações tornaram-se mais erráticas com as mudanças climáticas. Ainda assim, as estações meteorológicas no solo são poucas e distantes entre si. Este estudo aborda uma questão prática: com dados limitados, técnicas modernas de aprendizado de máquina combinadas com métodos clássicos de mapeamento podem gerar mapas de chuva mais nítidos e confiáveis para orientar a agricultura, o planejamento de enchentes e a gestão da água?
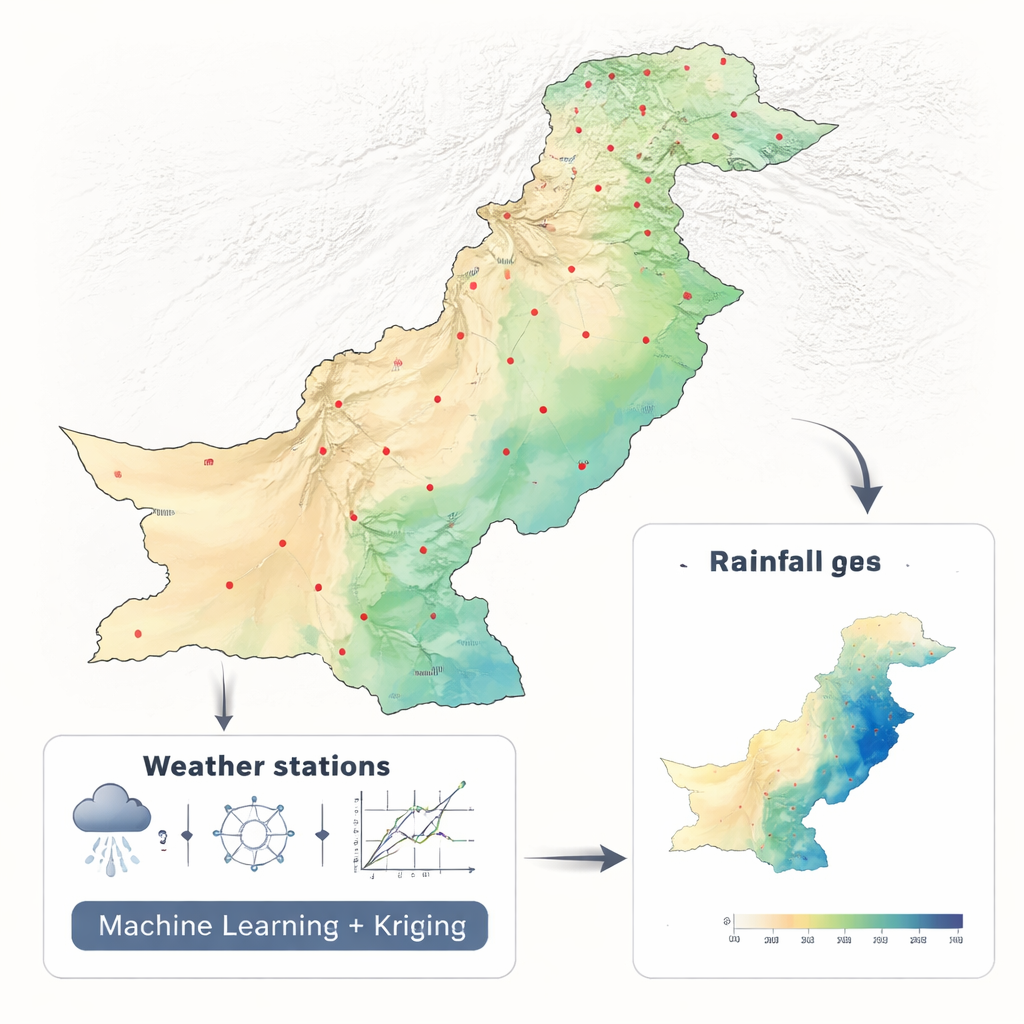
Transformando pluviômetros dispersos em mapas completos
Os pesquisadores trabalharam com duas décadas de dados mensais de precipitação (2001–2010 e 2011–2021) de 42 estações pelo Paquistão, usando um conjunto de dados climáticos consistente da NASA. Em vez de alimentar um modelo complexo com dezenas de variáveis ambientais, eles usaram deliberadamente apenas latitude e longitude. Esse desenho enxuto permitiu focar em uma questão central: qual abordagem matemática transforma melhor medições pontuais dispersas em um mapa contínuo. Compararam seis métodos de aprendizado de máquina — Random Forest, Máquina de Vetores de Suporte (SVM), K-Vizinhos Mais Próximos, Rede Neural, Elastic Net e Regressão Polinomial — cada um inserido em uma estrutura chamada regressão krigagem, amplamente usada nas geociências.
Mesclando aprendizado em estilo big data com intuição espacial
A regressão krigagem funciona em duas etapas. Primeiro, um modelo de regressão prevê a chuva em qualquer local a partir de suas coordenadas, capturando padrões amplos, como montanhas mais úmidas e desertos mais secos. Em seguida, um método espacial chamado krigagem preenche as diferenças residuais, padronizadas localmente, entre observações e predições. Para tornar essa segunda etapa confiável, a equipe primeiro estudou quão semelhantes ou diferentes eram as chuvas entre pares de estações a várias distâncias — uma ferramenta chamada variograma. Eles descobriram que formas matemáticas simples, “circular” e “linear”, descreveram melhor como a semelhança da chuva decai com a distância entre estações ao longo das estações do ano e entre as duas décadas, indicando sistemas de chuva suaves e regionais em vez de saltos abruptos.
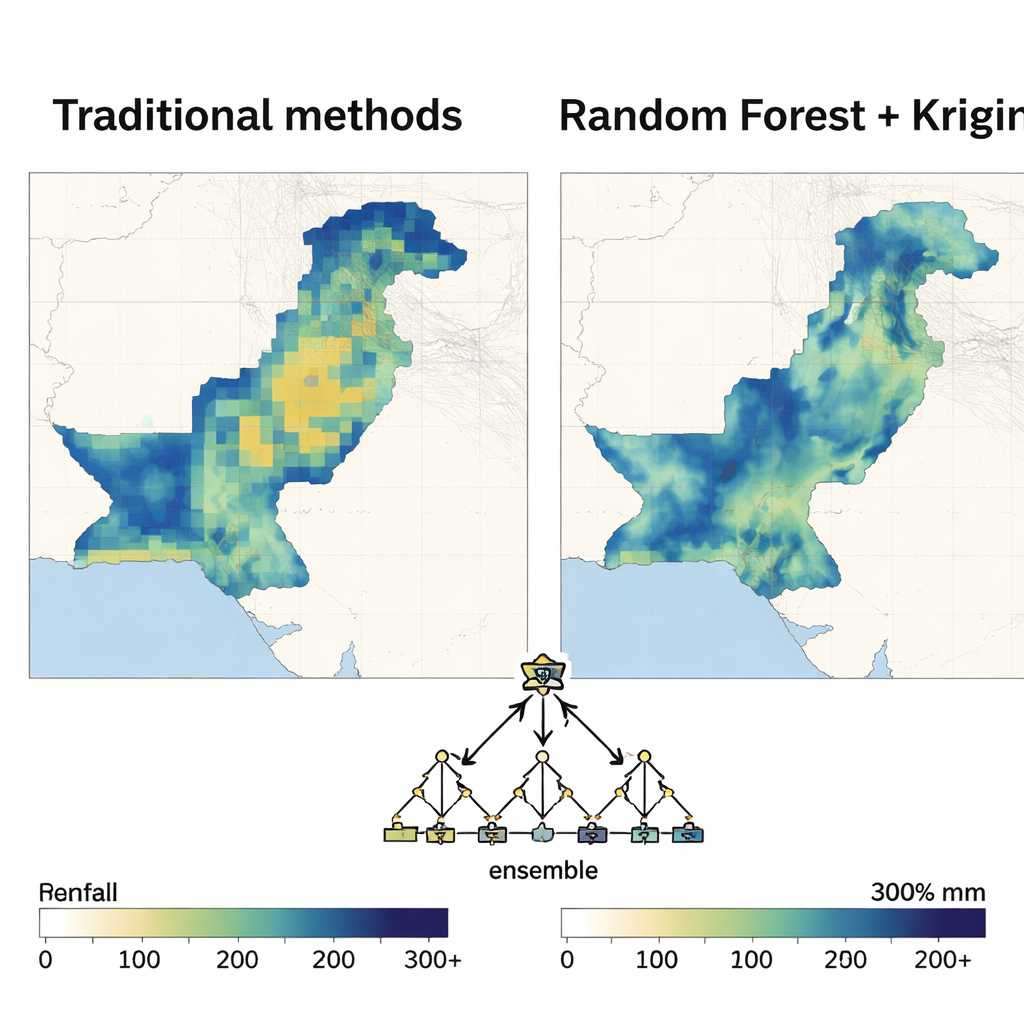
Random Forest surge como líder
Uma vez definida a estrutura espacial, cada método de aprendizado de máquina atuou como o motor de regressão dentro do modelo híbrido. Os autores avaliaram o desempenho com medidas padrão de erro e pela parcela da variabilidade da chuva que o modelo conseguia explicar. Em quase todos os meses e nas duas décadas, a abordagem baseada em Random Forest produziu os mapas mais precisos e estáveis. Reduziu os erros de previsão muito mais do que a regressão polinomial e superou de modo consistente máquinas de vetores de suporte, redes neurais e outros métodos, especialmente durante os meses de monção, quando a precipitação é mais intensa e variável. Os mapas resultantes foram suaves onde deveriam ser, mas ainda capturaram contrastes nítidos entre zonas secas e úmidas, com incerteza relativamente baixa.
O que os padrões de chuva em mudança revelam
Ao comparar as duas décadas, o estudo também observou sinais de comportamento de precipitação em mudança. Em média, a década mais recente (2011–2021) foi mais úmida, com maior variabilidade mês a mês e de lugar para lugar, particularmente na primavera e durante a monção. A estrutura espacial da chuva tornou-se mais dispersa, sugerindo oscilações mais amplas em onde a água é distribuída. Importante, a combinação Random Forest–krigagem lidou tanto com o clima anterior, relativamente mais brando, quanto com o período recente mais variável sem perder precisão, indicando que tais ferramentas flexíveis são bem adequadas a um mundo mais quente e menos previsível.
De mapas a decisões no terreno
Em termos práticos, o artigo mostra que algoritmos inteligentes podem extrair mais valor de registros pluviométricos limitados, produzindo mapas de alta resolução úteis mesmo em regiões com poucos dados. Para o Paquistão, esses mapas podem apoiar melhor o planejamento de irrigação, a operação de reservatórios e a defesa contra enchentes, além de ajudar a identificar comunidades mais expostas à seca ou a chuvas intensas. Os autores enfatizam que seu trabalho é uma prova de conceito focada nas técnicas de mapeamento em si, e não ainda um sistema completo de alerta de enchentes ou secas. Ainda assim, a conclusão é clara: combinar aprendizado de máquina em conjunto, liderado pelo Random Forest, com mapeamento geoestatístico oferece um caminho prático e poderoso para acompanhar como a chuva está mudando em terras áridas e semiáridas ao redor do mundo.
Citação: Manaf, M., Ali, Z. & Scholz, M. Integrating random forest-based regression kriging for analyzing spatial variability of rainfall in arid and semi-arid regions. Sci Rep 16, 5298 (2026). https://doi.org/10.1038/s41598-026-36074-4
Palavras-chave: mapeamento de chuva, random forest, regressão krigagem, clima do Paquistão, recursos hídricos