Clear Sky Science · pt
Navegação autônoma em ambientes externos não estruturados usando aprendizado por reforço guiado por segmentação semântica
Robôs Aprendendo a Caminhar pela Mata
Imagine um pequeno robô capaz de percorrer uma trilha na floresta sozinho, desviando entre árvores e rochas sem GPS ou um humano no joystick. Este artigo descreve um sistema que ensina robôs a “ver” os caminhos em matas densas e decidir, a cada instante, como avançar com segurança. O trabalho é relevante para robôs do futuro que possam ajudar no monitoramento florestal, prevenção de incêndios, busca e resgate e até entregas ao ar livre em locais onde sinais de satélite são fracos ou inexistentes.
Por que Florestas São Tão Difíceis para Robôs
Florestas estão entre os ambientes mais desafiadores para máquinas autônomas. Trilhas podem ser estreitas e sinuosas, o terreno é irregular, galhos e arbustos frequentemente bloqueiam a visão, e árvores altas tornam o GPS pouco confiável. Métodos tradicionais de navegação dependem de mapas precisos, GPS forte ou sensores a laser caros, e muitas vezes assumem espaços claros e estruturados como ruas ou fábricas. Na mata, essas suposições desmoronam: sombras, estações do ano e vegetação densa confundem sistemas visuais simples, enquanto controladores baseados em regras têm dificuldade para lidar com as situações bagunçadas e inesperadas que surgem numa trilha real.
Três Cérebro Trabalhando Juntos
Os autores propõem um sistema de navegação híbrido que dá aos robôs três “cérebros” complementares. Primeiro, um módulo visual profundo analisa cada imagem da câmera e marca, quase pixel por pixel, quais partes pertencem à trilha caminhável. Segundo, um módulo de decisão baseado em aprendizado usa reforço para escolher comandos suaves de direção e velocidade, recompensando comportamentos que permanecem na trilha, evitam colisões e alcançam o objetivo de forma eficiente. Terceiro, um controlador clássico converte a forma prevista da trilha em movimentos estáveis das rodas, alisando movimentos bruscos e mantendo o trajeto do robô elegante em vez de trêmulo. Em vez de uma única rede end-to-end opaca, esses módulos são separados mas estreitamente ligados, permitindo aos engenheiros entender e depurar cada etapa.
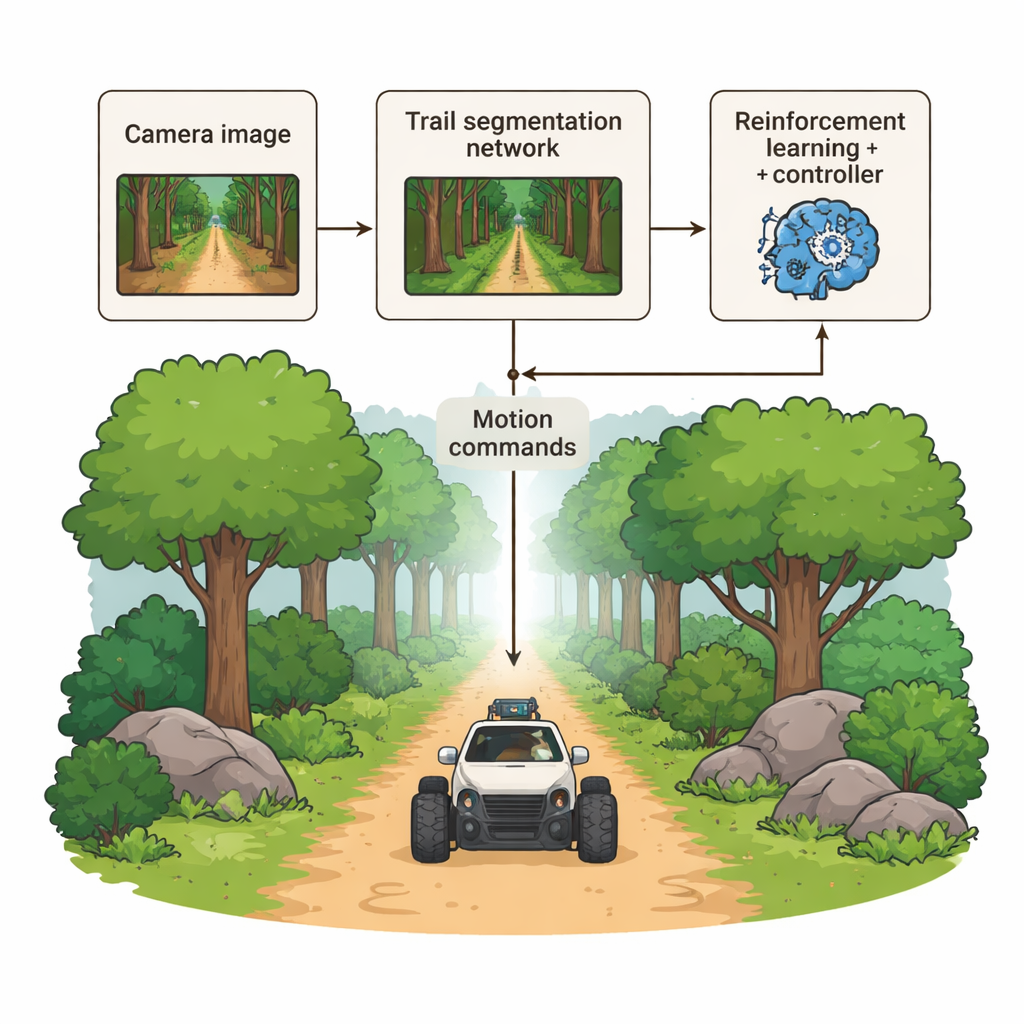
Ensinando a Visão a Reconhecer Trilhas
No coração dos “olhos” do robô está uma rede profunda conhecida como Mask R-CNN, aqui ajustada para realçar trilhas florestais em imagens coloridas comuns. Treinada em quase 24.000 quadros rotulados de filmagens reais feitas na altura de um humano, sob variações de luz, clima e tipos de trilha, o sistema aprende a pintar a região da trilha em cada quadro como uma máscara nítida. A partir dessa máscara extrai-se uma linha central fina que captura a direção e a curvatura do caminho adiante. Em testes, o módulo de visão atinge alta sobreposição com rótulos desenhados por humanos e mais de 90% de acurácia por pixel, delineando trilhas de forma robusta mesmo quando galhos ou sombras ocultam parcialmente o caminho. Esses indícios geométricos alimentam diretamente os módulos de decisão e controle como uma descrição compacta de “onde está o caminho”.
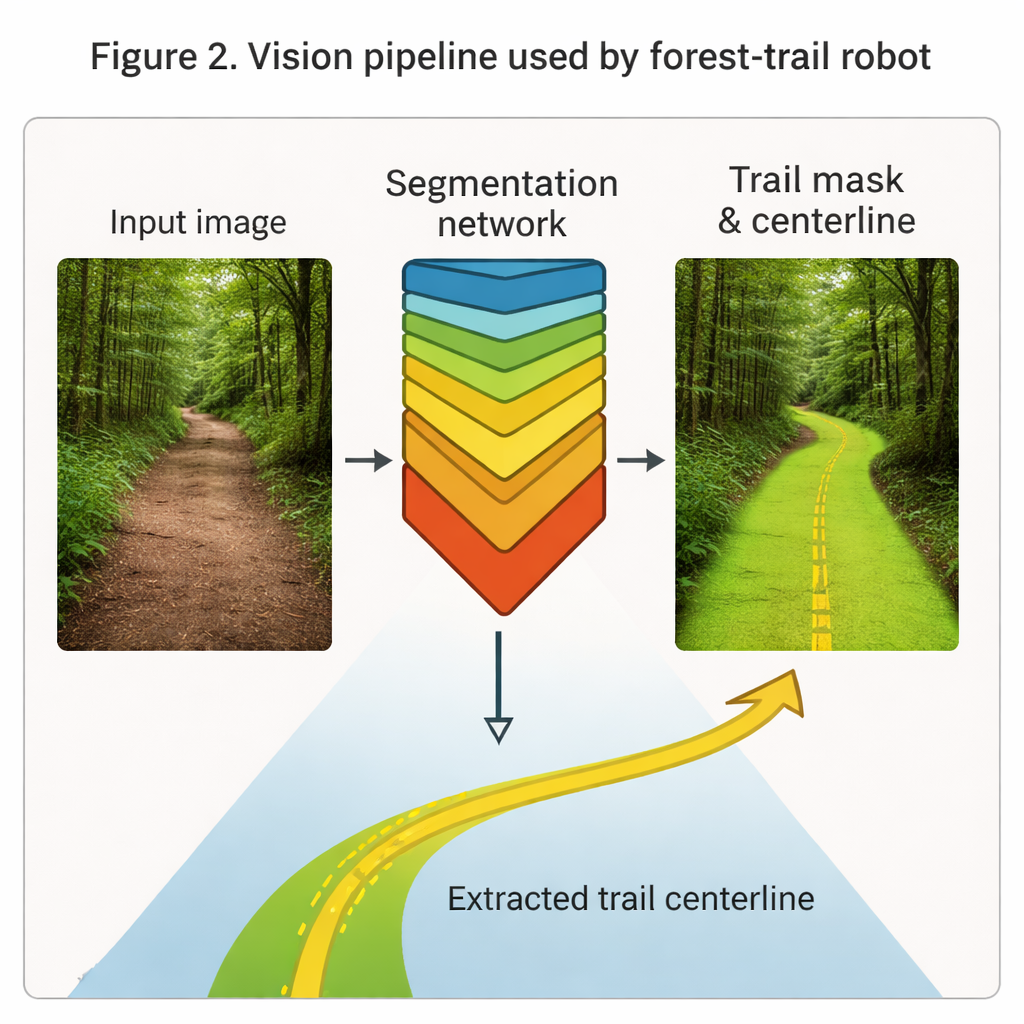
Treinando o Robô para Tomar Boas Decisões
A segunda peça chave é o módulo de decisão, que usa uma técnica chamada aprendizado por reforço. Em vez de receber instruções exatas, o robô testa ações em uma floresta simulada realista e recebe recompensas por resultados bons e penalidades por maus resultados. Avançar pela trilha é bom; desviar, colidir com obstáculos ou ficar preso é ruim. Ao longo de cerca de 150.000 passos de treinamento, o sistema gradualmente descobre estratégias que o mantêm centrado na trilha, contornam curvas com suavidade e reagem de forma sensata quando galhos ou pedras aparecem no caminho. Para manter os movimentos suaves e seguros, as ações aprendidas podem ser mescladas com as do controlador clássico, o que é especialmente útil em curvas fechadas ou condições ruidosas.
Colocando o Sistema à Prova
Para avaliar quão bem essa combinação funciona, os pesquisadores construíram três florestas virtuais detalhadas: uma com trilhas estreitas e cheias de entulho, outra com terreno íngreme e irregular e grandes obstáculos, e uma terceira repleta de bifurcações, becos sem saída e trilhas falsas distraidoras. Em 90 tentativas nesses mapas, o robô alcançou o objetivo sem colisão em cerca de 87% dos episódios, com uma média de apenas 0,2 colisões por execução e tipicamente mantendo-se a cerca de 30 centímetros do centro da trilha. Também completou rotas de forma rápida e consistente. Quando os autores removeram ou simplificaram um módulo por vez, o desempenho caiu acentuadamente — mostrando que os três componentes são necessários. Em comparação com outros sistemas recentes, incluindo os que usam scanners a laser, essa abordagem híbrida apenas por visão ofereceu a melhor combinação de taxa de sucesso, precisão e segurança.
O que Isso Significa para Robôs no Mundo Real
Para um público não especialista, a conclusão é que os robôs estão ficando melhores em trilhar como usuários cautelosos e competentes das trilhas. Ao combinar um forte senso de contexto visual (“isto é o caminho”), tomada de decisão baseada em prática (“esses movimentos funcionaram bem antes”) e um mecanismo de direção estável, o sistema proposto permite que um pequeno robô com rodas navegue por florestas complexas sem mapas ou GPS. Embora o trabalho tenha sido testado em simulação e ainda enfrente desafios como iluminação extrema e tipos raros de trilha, ele oferece um roteiro prático para futuros robôs de campo que possam compartilhar ambientes selvagens com pessoas com segurança, ajudando na inspeção de florestas, no apoio a equipes de resgate e na gestão de recursos naturais de forma mais eficaz.
Citação: Tibermacine, A., Tibermacine, I.E., Akrour, D. et al. Autonomous navigation in unstructured outdoor environments using semantic segmentation guided reinforcement learning. Sci Rep 16, 2633 (2026). https://doi.org/10.1038/s41598-026-36022-2
Palavras-chave: navegação autônoma, robótica florestal, visão computacional, aprendizado por reforço, segmentação semântica