Clear Sky Science · pt
A base de regras de crença otimizada por múltiplos parâmetros para prever o desempenho estudantil com interpretabilidade
Por que prever notas é assunto de todos
Boletins podem parecer simples, mas as forças que moldam as notas de um aluno estão longe de ser. As escolas recorrem cada vez mais a modelos computacionais para identificar alunos em dificuldade cedo e orientar intervenções. No entanto, muitos desses modelos são “caixas-pretas”: podem ser precisos, mas nem professores nem pais conseguem ver por que uma predição foi feita. Este artigo apresenta uma abordagem nova que busca ser ao mesmo tempo muito precisa e fácil de entender, para que educadores possam confiar e agir com base em seus resultados.
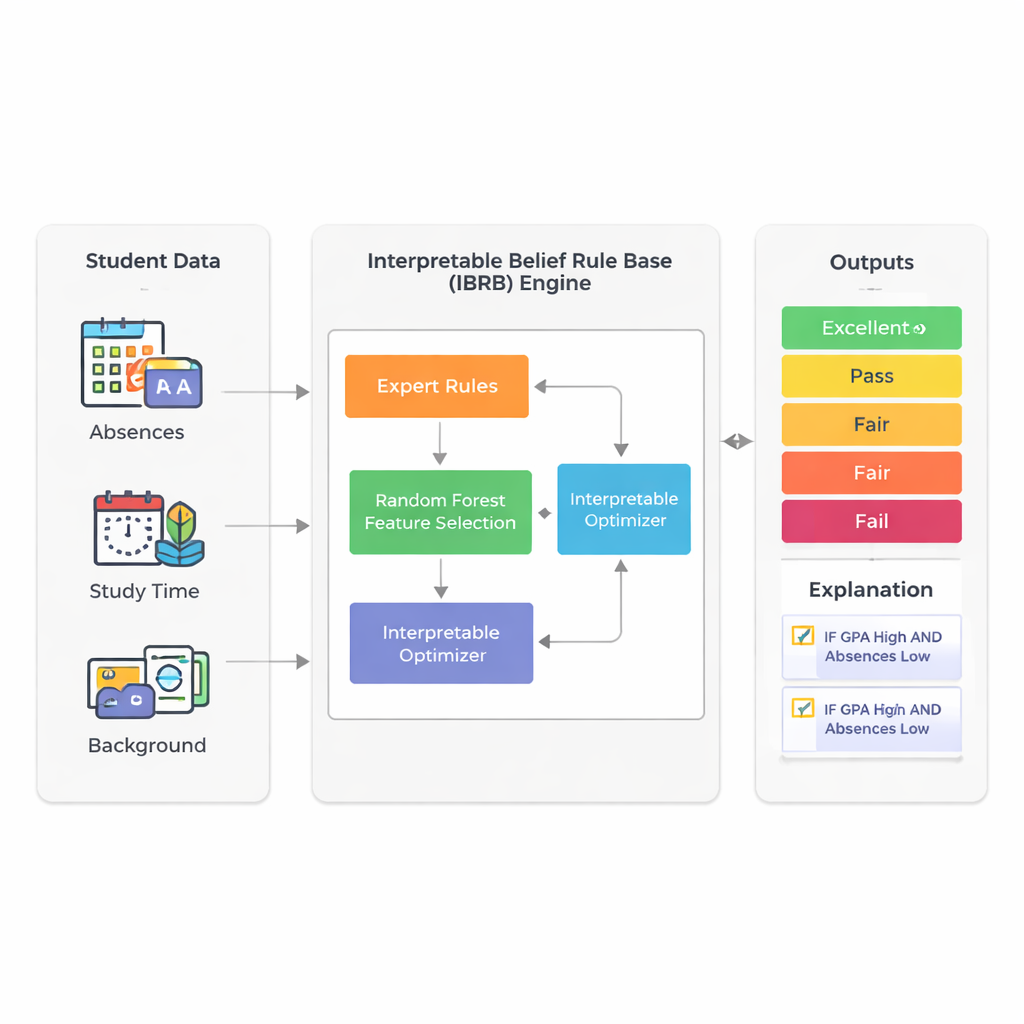
Uma maneira mais inteligente de ler os sinais
O estudo foca em prever quão bem os alunos irão se sair usando informações que as escolas já coletam: coeficiente de rendimento (GPA), faltas, tempo de estudo, histórico e fatores familiares e de atividades. Em vez de se apoiar em sistemas opacos de aprendizado profundo, os autores constroem sobre uma técnica chamada base de regras de crença. Neste quadro, especialistas escrevem regras que se parecem muito com o que um professor diria: “Se o GPA é alto e as faltas são poucas, então é provável que o aluno se saia bem.” Cada regra carrega um grau de crença sobre possíveis desfechos como Excelente, Bom, Suficiente, Regular ou Reprovado. Isso torna o processo de raciocínio visível e, em princípio, explicável a não especialistas.
Domando a complexidade sem perder significado
Um desafio importante com sistemas baseados em regras é que eles podem sair do controle quando muitos atributos do aluno são incluídos: cada fator extra multiplica o número de regras possíveis. Para evitar essa “explosão de regras”, os pesquisadores primeiro usam uma floresta aleatória—um conjunto amplamente usado de árvores de decisão—para medir quais características são mais relevantes para prever desempenho. Em seu conjunto de dados real com 2.392 alunos de uma fonte pública, GPA e número de faltas respondem por cerca de 73% do poder preditivo do modelo. Ao manter deliberadamente apenas essas duas entradas, o modelo final permanece compacto e mais fácil de interpretar, ao mesmo tempo em que reflete a maior parte da variação nos resultados dos alunos.
Construindo regras que as pessoas conseguem acompanhar
O núcleo do novo modelo, denominado IBRB-m, é um conjunto cuidadosamente estruturado de 25 regras que combinam níveis de GPA e faltas com graus de crença para as cinco categorias de desempenho. Os autores formalizam o que significa para tal modelo ser “interpretável”. Entre seus requisitos: cada nível de referência (como “GPA baixo”) deve cobrir uma faixa clara e distinta; a base de regras deve abranger todas as combinações realistas de entradas; parâmetros como pesos de regra e pesos de atributo devem ter significados intuitivos; e os cálculos internos do sistema devem transformar a informação de maneira transparente e matematicamente consistente. Além dessas condições tradicionais, eles acrescentam diretrizes específicas para educação que forçam as predições do modelo a seguir formas de senso comum—por exemplo, evitando casos bizarros em que um aluno é julgado simultaneamente muito provável de se destacar e de reprovar.
Deixando os dados refinarem o que os especialistas dizem
Especialistas humanos nem sempre concordam, e suas regras iniciais podem ser imprecisas. Para refinar essas regras sem transformar o modelo em uma caixa-preta, os autores projetam um algoritmo de otimização aprimorado que busca melhores valores de parâmetros enquanto obedece a restritas restrições de interpretabilidade. Esse algoritmo ajusta não só pesos de regra e graus de crença, mas também os pontos de corte que definem categorias como Excelente ou Suficiente. Mantém todas as mudanças dentro de limites aprovados pelos especialistas e impõe padrões de crença razoáveis e suaves ao longo das notas. Em efeito, o computador “empurra” o sistema especialista em direção a maior acurácia, mas não tem permissão para inventar regras que confundiriam um professor conhecedor.
Quão bem isso funciona na prática?
Testado no conjunto de dados de desempenho estudantil do Kaggle, o modelo IBRB-m prevê corretamente os níveis finais de desempenho em mais de 99% dos casos, superando tanto sistemas anteriores baseados em regras de crença quanto ferramentas comuns de aprendizado de máquina, como redes neurais, florestas aleatórias e k-vizinhos mais próximos. Tão importante quanto, as regras otimizadas permanecem próximas às avaliações originais dos especialistas quando medidas por uma métrica simples de distância, o que significa que o raciocínio por trás de cada predição ainda pode ser rastreado e justificado. Validação cruzada em múltiplas divisões dos dados mostra que o desempenho do modelo é estável, não um acaso de uma partição favorável.
O que isso significa para as salas de aula
Para leitores leigos, a principal conclusão é que é possível ter ferramentas de previsão estudantil que sejam ao mesmo tempo potentes e compreensíveis. Em vez de emitir pontuações de risco misteriosas, o modelo pode destacar padrões concretos como “GPA moderado, mas faltas frequentes” e mostrar como esses fatores contribuem para uma predição de Regular ou Reprovado. Professores e conselheiros podem então responder com ações direcionadas—como apoio à assiduidade ou treinamento de habilidades de estudo—enquanto explicam com confiança a alunos e pais por que o modelo chegou àquela conclusão. Os autores argumentam que essa combinação de acurácia e transparência é essencial para que sistemas movidos por dados desempenhem um papel confiável na promoção de uma educação justa e eficaz.
Citação: Li, J., Zhou, W., Jiang, S. et al. The multi-parameter optimized belief rule base for predicting student performance with interpretability. Sci Rep 16, 5772 (2026). https://doi.org/10.1038/s41598-026-35950-3
Palavras-chave: previsão de desempenho estudantil, IA interpretável, base de regras de crença, mineração de dados educacionais, aprendizado de máquina explicável