Clear Sky Science · pt
Estratégia de otimização dinâmica guiada por aprendizado por reforço para design paramétrico de modelos 3D
Designs 3D Mais Inteligentes Com Menos Tentativas às Cegas
De edifícios que chamam atenção a pequenas peças mecânicas dentro do seu telefone, muitos objetos modernos começam como modelos 3D computacionais. Designers frequentemente usam modelos “paramétricos”, em que controles deslizantes e fórmulas regulam formas, tamanhos e padrões. Isso facilita explorar muitas opções — mas também cria um labirinto de possibilidades impossível de vasculhar manualmente. Este artigo apresenta uma nova abordagem de inteligência artificial chamada HRL‑DOS que ajuda computadores a navegar esse labirinto, melhorando automaticamente projetos 3D em termos de resistência, uso de material e facilidade de fabricação.
O Desafio de Tantas Escolhas
No design paramétrico, um único objeto pode depender de dezenas ou centenas de parâmetros interligados: espessuras de parede, tamanhos de furos, curvas e regras de alinhamento. À medida que os modelos ficam mais complexos, esses parâmetros interagem de maneiras não óbvias. Ferramentas tradicionais de otimização ou dependem de funções matemáticas suaves, que falham quando os designs são irregulares ou ruidosos, ou de métodos de busca por tentativa e erro, que podem ser terrivelmente lentos para problemas grandes. Mesmo o aprendizado por reforço padrão — onde um agente de IA aprende por repetidas tentativas e feedback — tem dificuldade quando precisa considerar todas as combinações possíveis de decisões de projeto ao mesmo tempo.
Uma IA em Dois Níveis que Pensa como um Designer
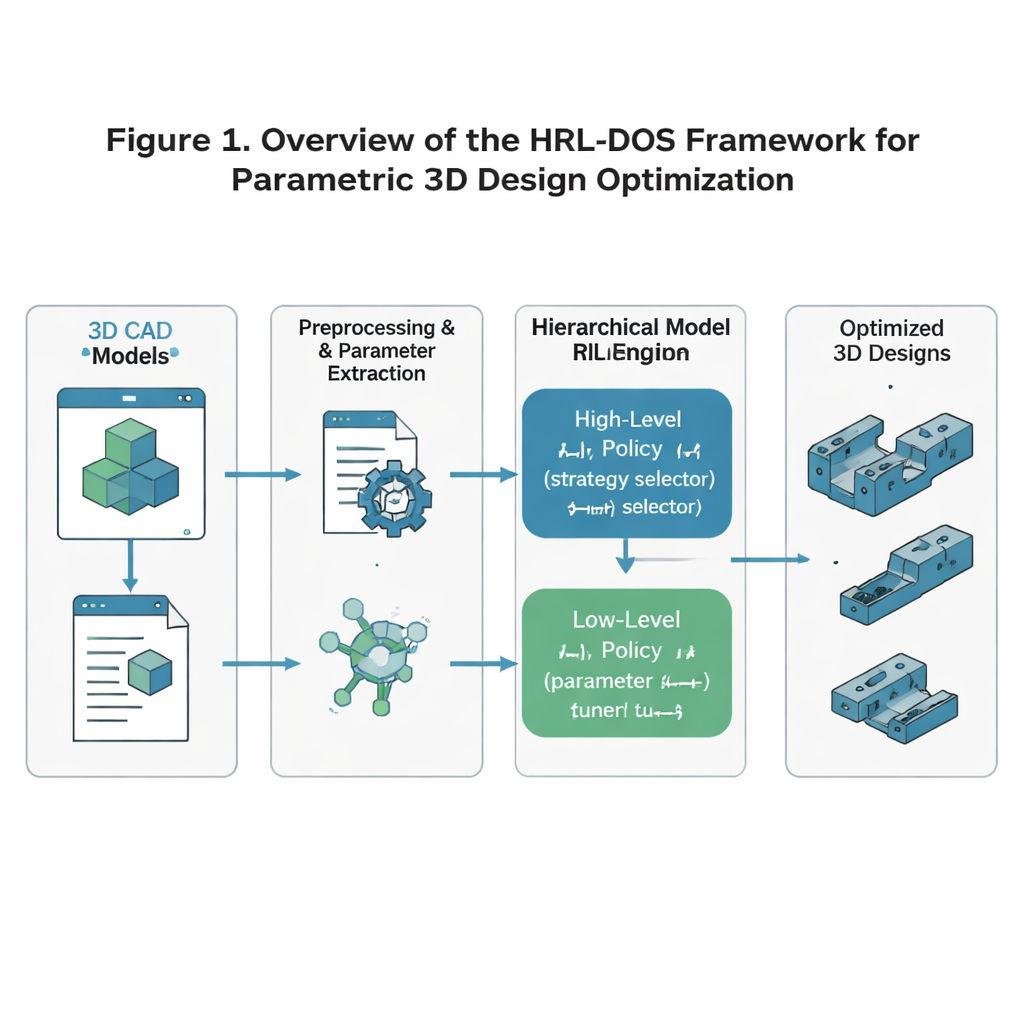
Os autores propõem a Estratégia de Otimização Dinâmica baseada em Aprendizado por Reforço Hierárquico, ou HRL‑DOS, para lidar com essa complexidade. Em vez de tratar o projeto como uma única decisão gigante, o HRL‑DOS divide a tarefa em duas camadas. Uma política de alto nível escolhe uma direção geral para o projeto — como priorizar menor massa, maior simetria ou margem de segurança adicional. Uma política de baixo nível então ajusta parâmetros individuais, como dimensões específicas ou posições de recursos, dentro desse plano mais amplo. Ambas as camadas recebem feedback baseado em quão bem o modelo atual se sai em três objetivos centrais: estabilidade estrutural, eficiência geométrica e fabricabilidade. Essa estrutura em camadas espelha a forma de trabalhar dos designers humanos: primeiro decidir um conceito, depois aprimorar os detalhes.
Transformando Modelos 3D Brutos em Dados Aprendíveis
Para treinar o sistema, os pesquisadores começam com o ABC Dataset, uma grande coleção aberta de modelos industriais 3D detalhados, como suportes, engrenagens, alavancas e chapas de montagem. Eles pré‑processam cada modelo para que a IA veja uma representação limpa e consistente: a geometria é normalizada para uma escala e orientação padrão; dimensões e características-chave são extraídas como parâmetros; e regras de fabricação — como espessura mínima de parede ou ângulos de balanço permitidos — são codificadas como restrições. Esses parâmetros são então transformados em uma descrição “latente” compacta que naturalmente desencoraja formas impossíveis ou instáveis. O resultado é um estado numérico que a IA pode modificar com segurança sem deixar de respeitar regras básicas de engenharia.
Aprendendo a Melhorar Peças Realistas
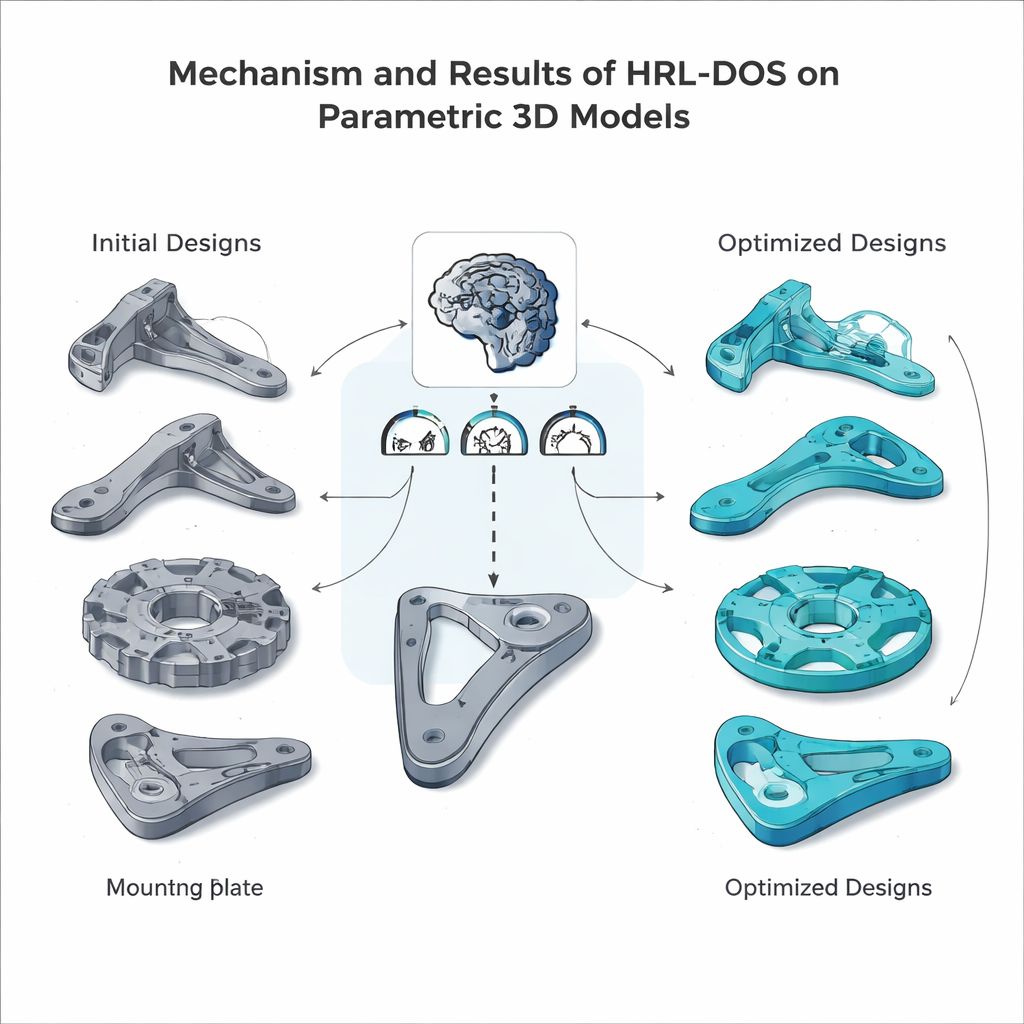
Dentro desse ambiente preparado, os agentes hierárquicos propõem repetidamente novos projetos, executam simulações para estimar massa e tensões, verificam a fabricabilidade e recebem uma pontuação de recompensa combinada. Ao longo de muitos episódios de treinamento, o agente de alto nível aprende quais metas estratégicas tendem a compensar, enquanto o agente de baixo nível descobre quais ajustes de parâmetro realmente alcançam essas metas. A equipe testou o HRL‑DOS em várias peças representativas do conjunto de dados — um suporte nervurado, um disco dentado, uma alça de alavanca e uma chapa de montagem — e comparou seu desempenho com várias alternativas avançadas, incluindo aprendizado por reforço simples, híbridos com algoritmos genéticos e outras ferramentas de projeto assistido por IA. O HRL‑DOS alcançou boas soluções cerca de 27% mais rápido e produziu modelos com aproximadamente 18% a mais na pontuação geral de qualidade.
Projetos Fortes, Fabricáveis e Flexíveis
Além do desempenho bruto, o HRL‑DOS mostrou-se melhor em permanecer dentro de limites rígidos de engenharia. Gerou muito menos projetos que violavam restrições de segurança ou fabricação e obteve pontuações de fabricabilidade mais altas em verificações como ângulos de balanço, cavidades internas e tolerâncias. O método também generalizou bem para tipos de peças novos e não vistos e permaneceu robusto quando os dados de entrada eram ruidosos ou parcialmente ausentes — uma característica importante para fluxos de trabalho de projeto no mundo real. Em conjunto, esses resultados sugerem que o aprendizado por reforço hierárquico pode servir como um motor prático para projeto auxiliado por computador inteligente, ajudando arquitetos e engenheiros a explorar mais opções em menos tempo, mantendo seus modelos seguros, eficientes e prontos para fabricação.
Citação: Zhong, G., Vijay, V.C. Reinforcement learning-driven dynamic optimization strategy for parametric design of 3D models. Sci Rep 16, 5041 (2026). https://doi.org/10.1038/s41598-026-35863-1
Palavras-chave: design 3D paramétrico, aprendizado por reforço, otimização de projeto, projeto auxiliado por computador, engenharia generativa