Clear Sky Science · pt
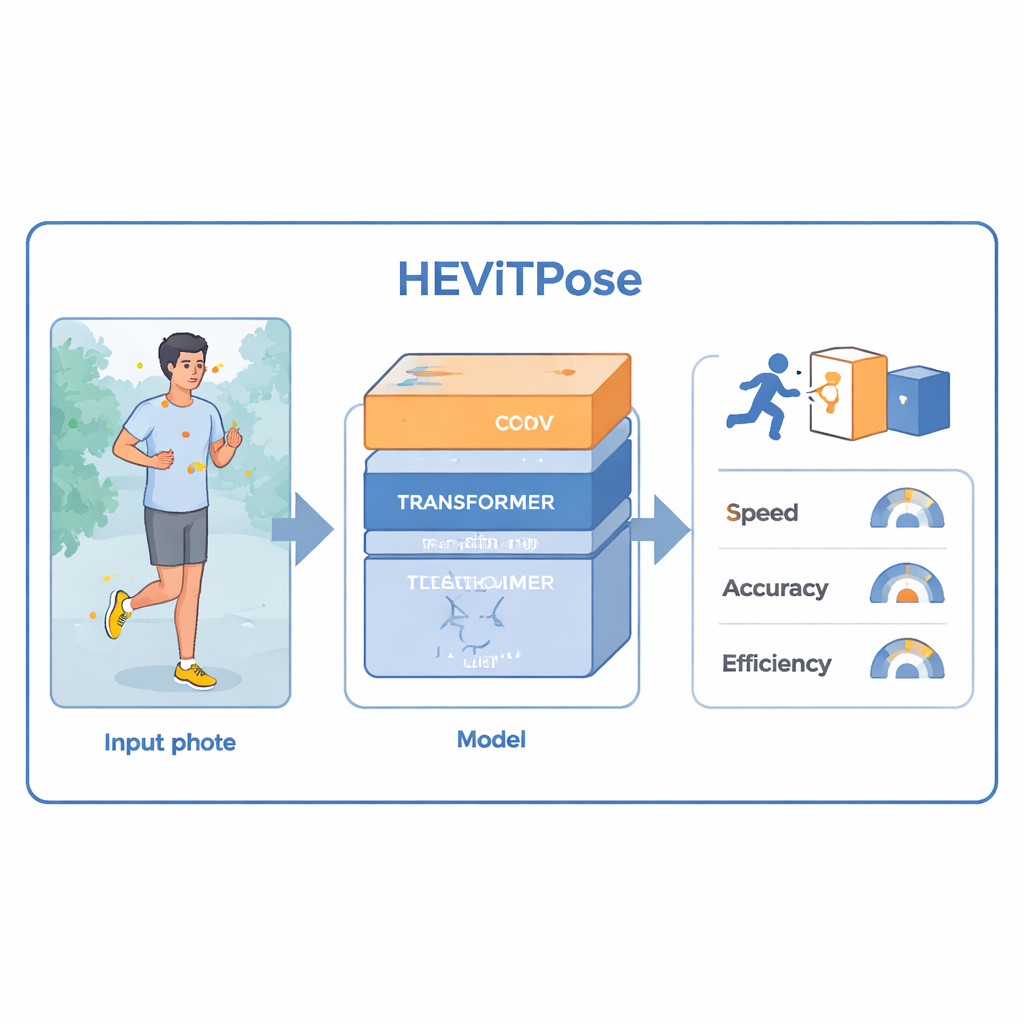
HEViTPose: rumo à estimativa de pose humana 2D de alta precisão e eficiência com atenção em redução espacial em grupo em cascata
Ensinando computadores a ler a linguagem corporal
De aplicativos de fitness a sistemas de assistência ao motorista, muitas tecnologias dependem hoje da capacidade de um computador entender como as pessoas se movem. Essa habilidade, chamada estimativa de pose humana, consiste em encontrar as posições das articulações do corpo — como ombros, joelhos e tornozelos — em uma imagem ou vídeo. O desafio é fazer isso com precisão e rapidez suficientes para uso em tempo real em hardware comum. Este artigo apresenta o HEViTPose, um novo método que busca manter alta precisão consumindo menos poder de processamento que muitos sistemas atuais.
Por que encontrar articulações em imagens é tão difícil
À primeira vista, localizar articulações pode parecer simples: basta procurar braços e pernas. Na prática, as pessoas aparecem em tamanhos diferentes, em poses incomuns, em cenas lotadas e frequentemente atrás de objetos como móveis ou carros. Sistemas modernos de estimativa de pose geralmente resolvem isso gerando um “mapa de calor” detalhado para cada articulação, onde pontos brilhantes indicam posições prováveis. Mapas de calor são muito precisos, mas caros de computar. Sistemas tradicionais baseiam-se principalmente em redes neurais convolucionais, que são boas em detectar padrões locais, mas precisam ficar mais profundas e pesadas para capturar relações de longo alcance por todo o corpo. Modelos mais recentes baseados em transformers se destacam em captar essas relações de longo alcance, porém costumam exigir grandes conjuntos de dados e alto custo computacional, o que os torna mais difíceis de usar em tempo real ou em dispositivos menores.
Vislumbres sobrepostos para uma visão mais suave
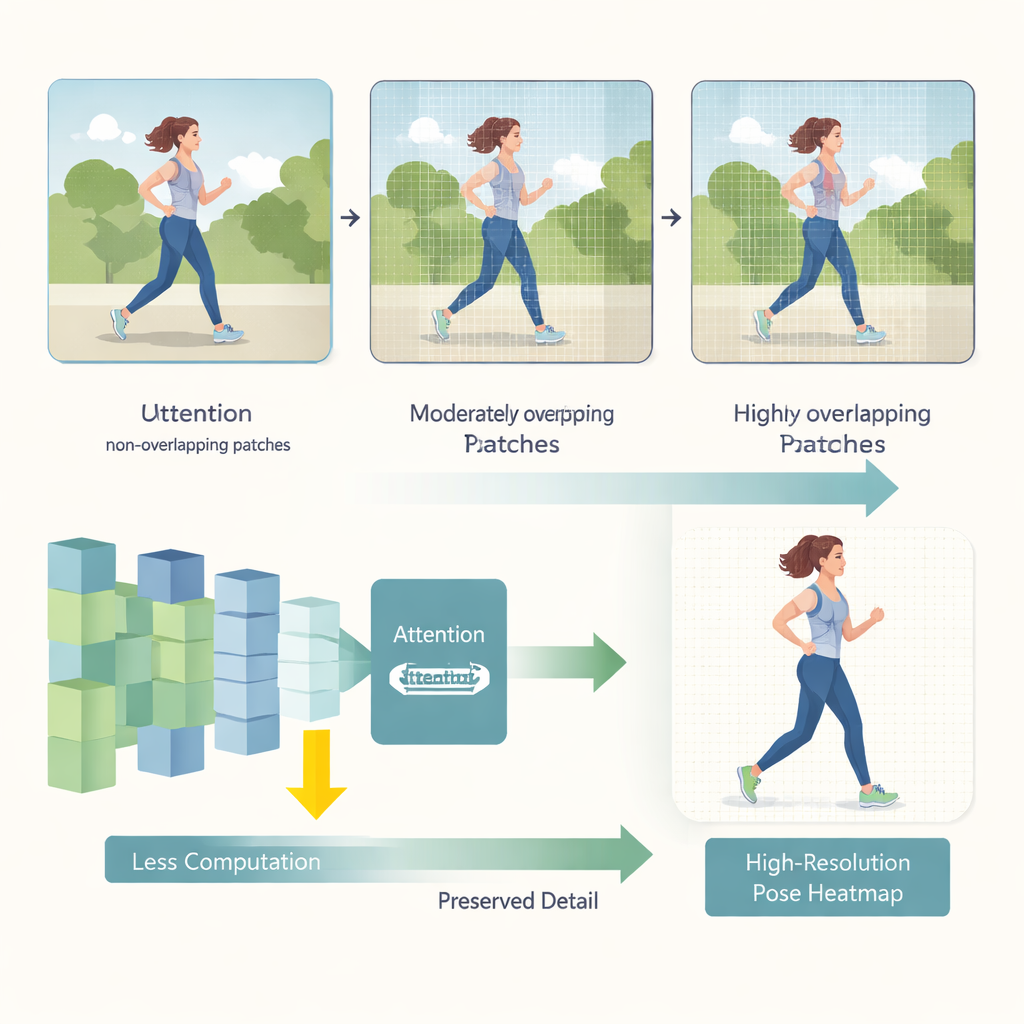
O HEViTPose começa repensando como uma imagem é dividida em partes para análise. Modelos transformers anteriores frequentemente dividiam imagens em blocos não sobrepostos, o que pode romper a continuidade visual entre regiões vizinhas — como cortar o braço de uma pessoa na borda de um bloco. O HEViTPose se baseia em uma ideia chamada incorporação de patches sobrepostos e introduz uma medida clara e ajustável chamada Largura de Sobreposição da Incorporação de Patches (Patch Embedding Overlap Width, PEOW). PEOW simplesmente conta quantos pixels os blocos vizinhos compartilham ao longo de suas bordas. Ao variar sistematicamente essa sobreposição, os autores mostram que uma sobreposição moderada permite que a rede “sinta” melhor a mudança suave de cor e forma entre um bloco e outro. Essa continuidade local mais rica leva a posições de articulações mais precisas, sem explodir o tamanho do modelo ou o custo computacional.
Atenção mais inteligente com menos trabalho
A segunda inovação chave é um novo módulo de atenção chamado Atenção Multi-Cabeça com Redução Espacial em Grupo em Cascata (Cascaded Group Spatial Reduction Multi-Head Attention, CGSR-MHA). Mecanismos de atenção dizem à rede quais partes da imagem devem influenciar cada previsão, mas tipicamente crescem em custo à medida que as imagens aumentam. O CGSR-MHA enfrenta isso de três maneiras. Primeiro, ele divide as características em grupos, de modo que cada grupo lida apenas com uma parcela da informação em vez de tudo de uma vez. Segundo, reduz a resolução espacial dentro de cada grupo antes de calcular a atenção, diminuindo bastante o número de operações. Terceiro, usa várias cabeças de atenção pequenas em vez de algumas grandes, preservando a diversidade do que o modelo pode “prestar atenção” enquanto mantém baixo o custo. Configurações cuidadosamente escolhidas sobre quantos grupos usar, quanto reduzir e quantas cabeças incluir alcançam um equilíbrio entre velocidade e precisão.
Modelos leves que ainda competem no topo
Para testar o HEViTPose, os autores o avaliam em dois benchmarks amplamente usados: o conjunto de dados MPII de atividades humanas do cotidiano e o maior conjunto COCO com pessoas em muitas cenas diferentes. Em vários tamanhos de modelo, o HEViTPose iguala ou chega perto da precisão dos principais sistemas de estimativa de pose, utilizando muito menos parâmetros e menos computação. Por exemplo, uma versão atinge precisão similar a uma popular rede de alta resolução (HRNet) enquanto reduz o número de parâmetros aprendidos em mais de 60% e diminui o volume de computação em mais de 40%. Em comparação com outro modelo híbrido moderno que mistura convoluções e transformers, o HEViTPose entrega desempenho parecido, mas roda cerca de 2,6 vezes mais rápido em uma unidade gráfica. Essas economias se traduzem diretamente em desempenho em tempo real mais suave e requisitos de hardware menores.
O que isso significa para aplicações do dia a dia
Em termos simples, o HEViTPose mostra que não precisamos escolher entre precisão e eficiência ao ensinar computadores a ler a linguagem corporal humana. Ao sobrepor com cuidado as partes da imagem que examina e ao redesenhar como a atenção é calculada dentro da rede, o sistema consegue localizar articulações com alta precisão permanecendo compacto e rápido. Isso o torna atraente para usos do mundo real, como monitoramento esportivo, vigilância por vídeo, interação humano–robô e monitoramento dentro de veículos, onde tanto velocidade quanto consumo de energia importam. As ideias por trás do HEViTPose — sobreposição mais inteligente e atenção eficiente — também podem ser adaptadas a tarefas relacionadas, como rastreamento de pose animal ou detecção de marcos faciais, potencialmente trazendo “olhos digitais” mais nítidos a muitos dispositivos sem exigir hardware de nível supercomputador.
Citação: Wu, C., Chen, Z., Ying, B. et al. HEViTPose: towards high-accuracy and efficient 2D human pose estimation with cascaded group spatial reduction attention. Sci Rep 16, 5637 (2026). https://doi.org/10.1038/s41598-026-35859-x
Palavras-chave: estimativa de pose humana, visão computacional, transformer de visão, aprendizado profundo eficiente, mecanismo de atenção